[Paper Review] YOLACT : Real-time Instance Segmentation
You Only Look At CoefficienTs


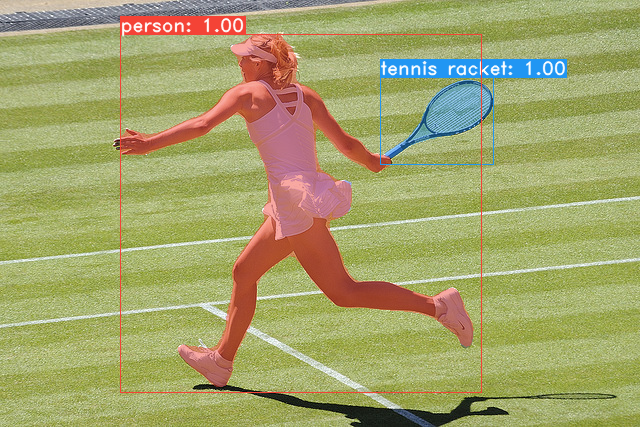
이번 ICCV 2019 에 발표된 YOLACT 논문이다. 파이토치로 구현되어있다.
https://github.com/dbolya/yolact
Abstract
YOLACT 는 Instance Segmentation 를 수행하기 위해 단순한 컨볼루션 모델을 제시한다. 이는 MS COCO 기준 29.8 mAP 및 33.5 fps 를 달성하여 실시간으로 객체를 탐지할 수 있다. 처음엔 프로토타입 마스크 세트를 생성하고, 인스턴스 별 마스크 계수(coefficient)를 예측한다. 그 다음 프로토타입을 마스크계수와 선형으로 결합하여 인스턴스 마스크를 생성하게 된다. 이 프로세스는 repooling에 의존하지 않기 때문에 고품질의 마스크를 생성할 수 있다고 한다. 또한 이 논문에서는 성능 저하 없이 표준 NMS를 12ms 더 빠르게 대체 할 수있는 Face NMS를 제안한다.
Introduction

“Boxes are stupid anyway though, I’m probably a true believer in masks except I can’t get YOLO to learn them.”
– Joseph Redmon, YOLOv3
지난 몇 년 동안 비전 분야에서는 객체 탐지를 시작으로 객체(인스턴스)를 분할하는데 큰 발전을 이루어왔다. 여기서 객체 분할이라함은 객체 탐지(Object Detection)에서 경계 상자(Bounding Box)로 각 개, 고양이와 같은 클래스들을 탐지하는 문제에서 더 발전하여 Box 형태가 아닌, 실제 고유의 클래스들이 가지는 모양 그대로 본따서 객체의 영역만을 탐지하는 문제를 말한다.
Mask-RCNN이나 FCIS 와 같은 인스턴스 분할(Instance Segmenataion) 연구에서는 Fast-RCNN 및 R-FCN과 같은 객체 탐지와 깊은 연관이 있다. 그러나 이러한 방법은 속도보다는 성능에 중점을 둔다. 이러한 점에서 이 논문의 목표는 SSD와 YOLO 같은 방식으로 빠르게 One-Stage 인스턴스 분할 모델을 구현하는 것이다.
하지만 각각의 클래스를 분할하는 문제는 객체 탐지 문제보다 훨씬 어려운 문제이다. SSD 및 YOLO 와 같은 One-Stage 검출기들은 단순히 Two-Stage를 제거하고 다른 방식으로 손실된 성능을 보충함으로써 Faster R-CNN과 같은 기존 Two-Stage 검출기의 속도를 따라잡을 수 있다.
그러나 이러한 접근법은 객체 분할 영역에 바로 확장하여 적용 할 수 없다. 최근 Two-Stage 객체 분할 연구는 Feature Localization을 중점적으로 마스크를 생성한다. 즉, 이러한 방법은 일부 경계 상자 영역(Rolpool 또는 align)의 기능을 "repool"한 다음, Localization 된 특징들을 마스크 예측기(mask predictor)에 제공한다. 이러한 방법은 순차적으로 가속화하기 어렵기 떄문에 FCIS 와 같이 이러한 단계를 병렬로 수행하는 One-Stage 접근법이 있지만, Localization 후에 상당한 양의 Post-processing이 필요하기 떄문에 실시간으로 작동하는 것이 어렵다.
본 논문에서는 이러한 문제를 해결하기 위하여 즉, 방대한 Post-processing이 필요한 Localization을 포기하고 "실시간"으로 작동하도록 하는 객체 분할 프레임워크 YOLOACT를 제안하였다.
대신 객체 분할 단계를 2개의 병렬 작업으로 수행한다.
1. 전체 영상에 대해 Non-local Prototype Mask 를 생성
2. 인스턴스 당 선형 조합(Linear Combination) 계수 세트를 예측
즉, 각 인스턴스에 대해 예측된 계수(predicted coefficients)를 사용하여 프로토 타입을 선형으로 결합한 다음 예측된 경계 상자를 이용하여 크롭한다. 이러한 방식으로 분할을 수행함으로써 신경망은 시각적(visually), 공간적(spatially), 의미적(semantically)으로 유사한 인스턴스가 프로토타입에서 다르게 나타나는 인스턴스 마스크를 자체적으로 Localization 하는 방법을 학습하게 된다.
또한 프로토 타입 마스크의 수는 카테고리 수와는 무관하기 때문에 (프로토 타입보다 더 많은 카테고리가 있을 수 있다고 함) YOLACT는 각 인스턴스가 카테고리간에 공유되는 프로토타입의 조합으로 분할되는 분산된 표현을 학습한다.
이러한 분산된 표현은 프로토타입 공간에서 아래 그림과 같이 흥미로운 동작들을 수행한다. 일부 프로토타입은 영상을 공간적으로 분할하고, 일부 인스턴스를 Localization을 수행하고, 일부는 인스턴스 윤곽선을 검출하고, 일부는 위치 감지 방향 맵(position-sensitive directional maps)을 인코딩하여 대부분이 이러한 작업으로 Combination을 수행한다.
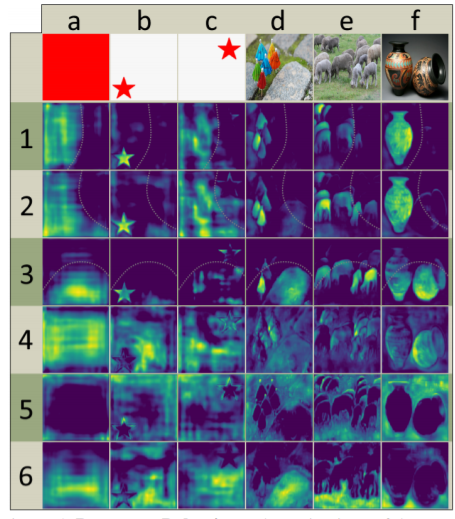
위와 같은 프로토타입에서 1~3은 소프트하고, 잘 안보이는 바운더리(점선으로 표시함)의 한쪽에 있는 객체를 보여주고 있으며, 프로토타입 4는 객체의 왼쪽 하단에서 활성화되는 것을 보여준다. 예를 들면 영상 d의 우산의 왼쪽 하단을 말한다. 프로토타입 5는 배경과 객체 사이의 가장자리에서 활성화된다. 그리고 프로토타입 6은 네트워크가 영상에서 땅이라고 생각하는 부분을 분할하게 된다. 영상 d-f에서 이러한 프로토타입 4, 5, 6의 특징이 두드러지게 잘 관찰된다.
이러한 방식은 무엇보다 실시간으로 동작할 만큼 빠르다고 한다. 병렬 구조를 가지고 있으며 초경량으로 프로세스를 조합했기 때문에 YOLACT는 One-Stage 백본 검출기에 약간의 계산 오버헤드만 추가하여 ResNet-101을 사용할 때도 30 fps 를 기록한다. 실제로 전체 mask branch는 ~5 ms 밖에 안걸린다고한다.
또한 YOLACT를 통해 나오는 마스크는 고품질이라고 한다. 마스크는 RePooling 과정을 통해 영상 손실 없이 영상 공간의 전체 범위를 사용하기 떄문에 큰 물체에 대한 마스크는 다른 최신 방법들에 비해 품질이 훨씬 좋다고 한다.

위에 그림에서 보듯 FCIS 나 Mask-RCNN 과 달리 세그먼트 성능이 우수하다.
그리고, 일반적으로 프로토타입과 마스크 계수를 생성하는 아이디어는 거의 모든 최신 객체 탐지기에 추가될 수 있다고한다.
이 논문의 주요 Contribution은 MSCOCO 데이터세트에 대하여 우수한 세그먼트 결과를 보여주는 최초의 실시간 (> 30 fps) 객체 분할 알고리즘이다. 또한, 기존 NMS 보다 12ms 빠른 새로운 Fast NMS 접근 방식을 제공한다.
Networks
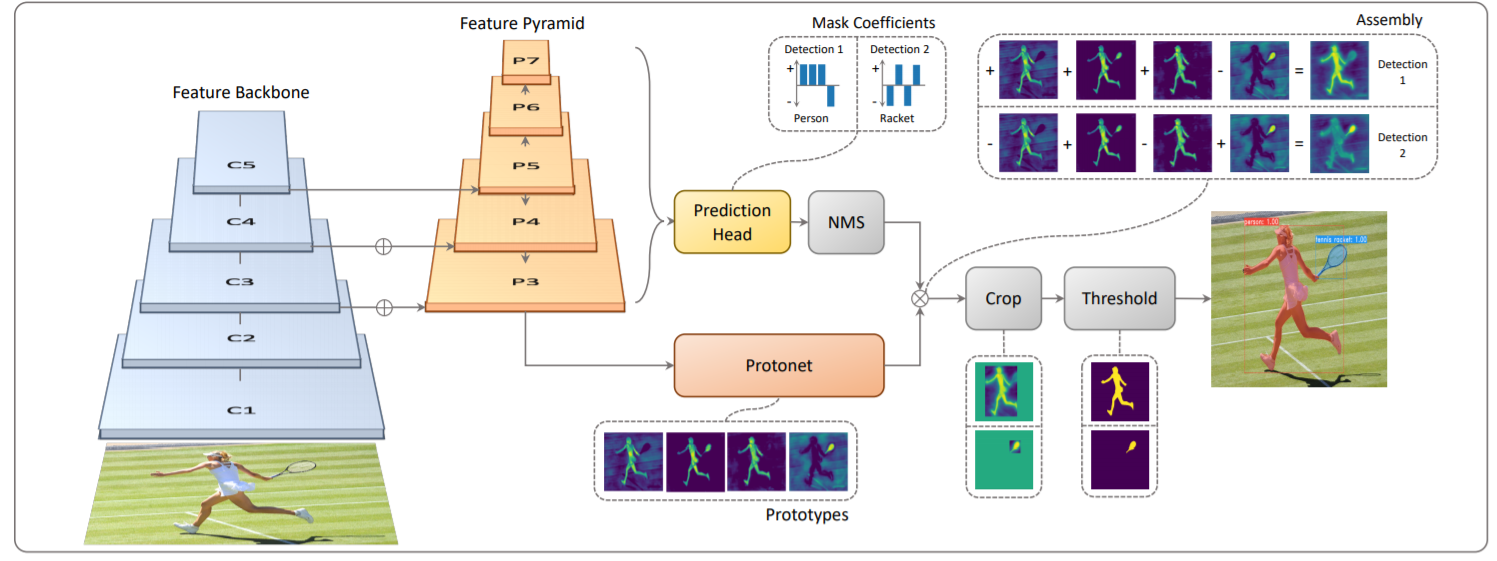
YOLACT의 네트워크는 ResNet101 + FPN 을 이용하여 RetinaNet에 기반한 구조이다.
프로토타입을 생성하는 분기에서는 전체 영상에 대해 k개의 프로토타입 마스크세트를 예측한다. 아래 그림과 같이, 마지막 계층에서는 k개의 채널이 있는 FCN으로 ProtoNet을 구현하고 이를 백본 특징 레이어에 연결한다. 더 깊은 백본 특징에서 protonet 을 가져오면 더 강력한 마스크가 생성되고, 솔루션 프로토타입이 높을수록 작은 마스크와 성능이 향상된다. 따라서 가장 큰 특징 레이어가 가장 깊기 때문에 FPN을 사용한다. 그 다음 사이즈가 작은 영상의 성능을 높이기 위하여 입력 영상 크기의 1/4 로 업 샘플링을 수행한다. 마지막으로 프로토타입의 output 은 제한을 받지 않아야한다. 이는 신경망이 내놓는 프로토타입, 예를 들면 명확한 배경에 대해 압도적으로 활성화를 할 수 있기 때문이다. 따라서 ReLU를 사용하거나 비선형성을 갖지 않는 프로토타입을 사용한다.

일반적인 앵커(Anchor) 기반 객체 탐지기는 c 클래스 신뢰도를 예측하는 프로세스와 4개의 경계 상자 Regressor 를 예측하는 프로세스로 구성이된다. 여기서의 Mask Coefficient 예측은 각 프로토타입에 해당하는 k개의 마스크 계수를 예측하는 프로세스를 병렬로 추가하기만 하면 되다. 따라서 앵커 당 4 + c 계수를 생성하는 대신 4 + c + k 를 생성한다. 그렇기 때문에 다른 검출기에도 적용이 가능한 것이다. 또한 비선형성의 경우에는 최종 마스크에서 프로토타입을 빼는 것이 중요하다. 따라서 k 마스크 계수에 tanh를 적용하여 비선형성 없이도 보다 안정적인 output을 생성한다.
Result
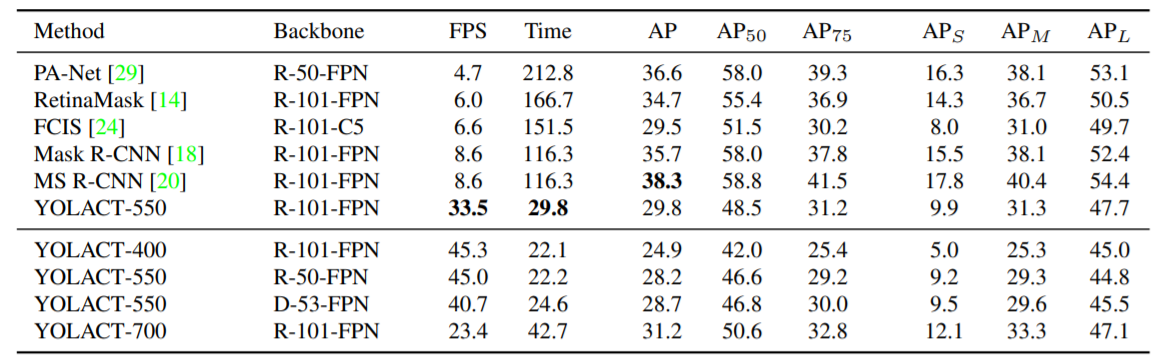
이는 COCO 데이터세트에 대하여 평가한 지표이다.

역시나 Mask R-CNN에 비해 우월한 FPS 를 보여준다. 객체를 세그먼트하는 분야는 시간이 굉장히 많이 소요되고, 복잡한 작업이어서 실시간은 절대 안될 것 이라고 생각했었는데, 그 틀을 깨준 논문이다. Segmentation이 실시간 성능이 보장되니, Bounding Box 를 검출하는 객체 검출기에서도 유용하게, 그리고 정확하게 사용할 수 있을 것으로 예상된다.

paper arxiv : https://arxiv.org/abs/1904.02689
YOLACT: Real-time Instance Segmentation
We present a simple, fully-convolutional model for real-time instance segmentation that achieves 29.8 mAP on MS COCO at 33.5 fps evaluated on a single Titan Xp, which is significantly faster than any previous competitive approach. Moreover, we obtain this
arxiv.org
Github : https://github.com/dbolya/yolact
dbolya/yolact
A simple, fully convolutional model for real-time instance segmentation. - dbolya/yolact
github.com
YOLACT 를 간단하게 정리한 PPT
https://www.slideshare.net/BrianKim244/20190708-bumsookim-yolact
20190708 bumsookim yolact
YOLACT: Real-time Instance Segmentation
www.slideshare.net
'AI Research Topic > Image Segmentation' 카테고리의 다른 글
| [Object Segmentation] ASPP : Atrous Spatial Pyramid Pooling (0) | 2020.07.19 |
|---|---|
| [참고자료] Image Segmentation (0) | 2017.11.27 |
| [Object Segmentation] Image segmentation using deconvolution layer in Tensorflow (0) | 2017.07.05 |