[Paper Review] M2Det : A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
객체 탐지(Object Detection) 분야에서 객체 인스턴스(Instance)의 스케일(Scale) 변화는 주요 challenge 중 하나이다. 일반적으로 이 문제를 해결하기 위한 두가지 방법은 이미지 피라미드(Image Pyramid)에서 객체를 탐지하는 것과 입력에서 추출된 Feature Pyramid 에서 객체를 탐지하는 것이다. 전자의 방법은 메모리와 계산 복잡성을 증가시키기 때문에 효율성이 떨어지며, 후자의 방법은 트레이닝 및 테스트 단계에서 활용할 수 있고, 전자의 방법보다는 메모리와 계산 비용이 적게 든다. 또한 이 Feature Pyramid 는 End-to-end 방식이기 때문에 쉽게 통합이 가능하다는 장점을 가진다.
M2Det(Multi-level and Multi-scale Detection) 은 멀티레벨 및 멀티스케일 특징을 사용하여 객체 탐지에서 일어나는 객체 인스턴스의 스케일 변화 민감도에 대한 문제를 해결 할 수 있고, 최신 객체 탐지기들의 정확도를 개선시켰으며, 실시간으로 동작할 수 있는 가능성을 보여주는 좋은 알고리즘이다.
Multi-Scale Testing 방식은 이름에서도 유추가 가능하듯이 하나의 이미지에 대해서 여러 scale에서 test를 하는 방법을 의미합니다. 그동안 하나의 이미지를 여러 scale에서 학습을 하는 논문들은 많았었습니다. 대표적으로 SSD, YOLO이 있으며 SSD에서는 여러 scale의 feature map에 대해서 적용을 하였고, YOLO는 학습 데이터의 해상도를 320x320 부터 608x608까지 다양한 scale로 resize를 하여 학습을 시켰습니다. 이러한 방식들은 학습 단계에 feature map 혹은 input image 자체에 multi scale을 적용하고 있습니다.
Introduction

위 그림 (b)에서와 같이, 객체 탐지 분야에서 FPN(Feature Pyramid Network)은 RetinaNet, RefineDet 과 같은 One-stage Object Detector와 Mask R-CNN, DetNet 등의 Two-stage Object Detector 에 적용되어 전체적으로 Scale Variation 으로 인한 문제를 해결해주는 역할을 수행한다.
이러한 FPN 형태를 갖고있는 객체 검출기들은 원래 객체 분류(Object Classification)를 위해 설계된 백본(Backbone)의 멀티 스케일 피라미드 구조에 따라 특징을 구성하기 때문에 객체 탐지에 있어서는 다음과 같은 제한이 있다.
1. FPN 의 특징 맵은 객체 분류를 위해 백본 레이어가 간단하게 설계되어있기 때문에 객체 탐지를 위해선 충분하지 않음
2. FPN의 각 특징맵은 주로 단일 레벨(Single-level)로 구성이 되기 때문에 단일 레벨 정보만을 포함함
또한, 저수준(Low-level)의 특징은 단순한 모양으로 객체를 특성화하는데 더 적합하지만, 고수준(High-level) 특징은 복잡한 모양을 가진 객체에 적합하다. 실제 환경에서 신호등과 먼 사람의 크기는 비슷할 수 있으며, 사람의 외모는 신호등 보다 훨씬 더 복잡하기 때문에 단일 레벨의 특징으로는 최적의 탐지 성능을 기대 할 수 없다는 한계가 있다.
그렇기 때문에 M2Det 에서는 MLFPN(Multi-Level Feature Pyramid Network)를 제안하여 다양한 스케일의 물체를 감지하기 위한 신경망을 제안하였다.
Proposed Method
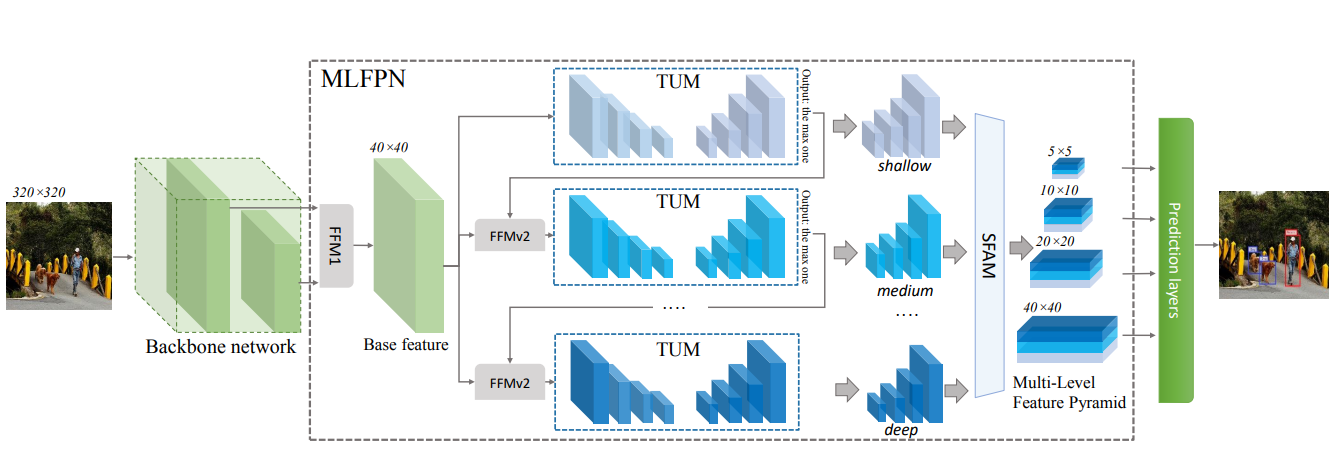
Multi-level Feature Pyramid Network
M2Det 의 전체 아키텍쳐는 위 그림과 같다.
M2Det 은 간단하게 말하자면,
백본에서 추출한 멀티 레벨 특징(i.e. multiple layers) 을 베이스 특징(Base Feature)으로 통합한다. 그 다음 베이스 특징을 교차 결합된 TUM(Thinned U-shape Modules) 블록에 전달하고, 각 Ushape 모듈의 디코더 레이어를 객체를 탐지하기 위한 특징으로 사용한다. 마지막으로 동일한 스케일로 디코더 레이어를 수집하여 객체 탐지를 위한 FPN을 구성한다. 모든 특징 맵은 여러 레벨의 레이어로 구성된다.
자세히 말하자면,
백본 및 MLFPN 을 사용하여 입력 이미지에서 특징을 추출한 다음, SSD 와 유사하게 dense 한 경계 상자(Bounding Box) 및 스코어(Score) 값을 생성한 다음 NMS(Non-Maximum Suppression) 작업을 수행하여 최종 결과를 생성한다.
MLFPN의 구성은 다음과 같다.
1. FFM(Feature Fusion Module)
2. TUM(Thinned U-shape Modules)
3. SFAM(Scale-wise Feature Aggregation Module)
MLFPN의 세가지 모듈 중 FFM 모듈의 FFMv1 은 얕고 깊은(Shallow and Deep) 특징을 융합하여 VGG의 conv4_3 , conv5_3 처럼 베이스 특징을 생성하여 MLFPN에 대한 멀티레벨 시맨틱(Semantic) 정보를 제공한다.
또한 여러 TUM과 FFMv3 가 교대로 쌓이는데 TUM은 서로 다른 스케일로 여러 특징 맵들을 생성한다. FFMv2 는 이전 TUM의 베이스 특징과 가장 큰 출력 특징 맵을 통합하는 역할을 수행한다. 첫번째 TUM에는 다른 TUM에 대한 사전지식이 없으므로 Xbase 로 부터 학습된다. 멀티레벨 멀티스케일 특징들은 다음과 같이 계산된다.

Xbase 는 베이스 특징을 나타내고, xli 는 l번째 TUM에서 i번째 스케일을 나타내고, L은 TUM들의 갯수를 뜻한다. Ti은 l번째 TUM processing 을 나타내며, F는 FFMv1 processing을 나타낸다.
세번째 모듈인 SFAM은 스케일별 특징 Concat 작업과 채널별로 Adaptive Attention 메커니즘을 통해 특징을 멀티 레벨 특징 피라미드로 통합한다.
1. FFM

위 그림(a, b)과 같이, FFM은 M2Det의 다양한 레벨에서 특징들을 통합하여 최종 멀티 레벨 특징 피라미드를 구성하는데 중요한 역할을 수행한다. 1x1 conv 를 사용하여 입력 특징의 채널을 압축하고 Concat 연산을 사용하여 특징 맵을 통합한다. 특히 FFMv1은 입력으로 백본의 스케일이 다른 두 개의 특징 맵을 취하므로 Concat 작업 이전에 깊은 특징들을 동일한 스케일로 다시 스케일링 하기 위해 하나의 업샘플(Upsample) 연산을 수행한다. 한편 FFMv2 는 이전 TUM의 베이스 특징과 가장 큰 출력 특징 맵을 입력으로 받는다. 이 두 가지는 입력과 동일한 스케일이며, 다음 TUM에 대한 융합된 특징을 생성한다.
2. TUMs
FPN 및 RetinaNet 과 달리 TUM 은 그림 FFM 에서 (c)에 표시된 것처럼 더 얇은 U 자형 구조를 갖고있다. 인코더는 Stride 2 로 된 3x3 conv 이다. 그리고 디코더는 이러한 레이어의 출력을 특징맵의 기준 세트로 설정하고, 원본 FPN은 ResNet 백본에서 각 단계의 마지막 레이어의 출력을 선택한다. 또한 업샘플링 및 elementwise 연산 후, 1x1 conv 레이어를 디코더 브랜치에서 추가하여 학습 능력을 향상시키고 smoothness 특징을 유지한다. 각 TUM의 디코더에 있는 모든 출력은 현재 레벨의 멀티 스케일 특징을 형성한다. 전체적으로 쌓인 TUM의 출력은 멀티 레벨 멀티 스케일 특징을 형성하는 반면, 앞단에 있는 TUM은 주로 얕은 레벨 특징을 제공하고, 중간에 있는 TUM은 중간 레벨 특징을 제공하며, 뒷단에 있는 TUM은 깊은 레벨의 특징을 제공한다.
3. SFAM

SFAM은 위 그림과 같이 TUM 에 의해 생성된 멀티 레벨 멀티 스케일 특징을 멀티 레벨 특징 피라미드로 통합하는 것을 목표로 한다. SFAM의 첫번째 단계는 채널 차원을 통해 동등한 스케일의 특징을 Concat 시키는 것이다. 합쳐진 특징 피라미드는 X는 다음과 같이 나타낸다.
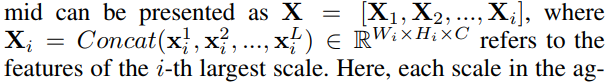
여기서 Xi 의 i는 i번째로 큰 스케일의 특징을 나타낸다. 여기서 통합된 피라미드의 각 스케일에는 멀티레벨 특징들이 포함된다. 그러나 간단한 Concat 으로는 충분하지 않기 때문에, 두번째 단계에서는 채널 별 모듈을 도입하여 특징이 가장 의미있는(benefit) 채널에 집중하도록 한다.
SE(Squeeze Excitation) block 에 의해, 이 논문에서는 Global Average Pooling 을 사용하여 Squeeze 단계에서 채널별 통계 z 를 생성한다. 채널 별 종속성을 완전히 알아내기 위해 다음 수식 2 에서 두 개의 Fully connected layer 를 통해 메커니즘을 학습한다.
Squeeze Excitation
Squeeze operation은 말 그대로 짜내는 연산을 하게됩니다. 이는 다르게 말해서 각 채널들의 중요한 정보만 추출해서 가져가겠다는 뜻과 같습니다. Local receptive field가 매우 작은 네트워크 하위 부분에서는 이렇게 중요 정보 추출이라는 개념이 매우 중요합니다. 논문에서는 중요 정보를 추출하는 가장 일반적인 방법론 중 하나인 GAP(Global Average Pooling)을 사용합니다. GAP를 사용하면 global spatial information을 channel descriptor로 압축시킬 수 있다고 합니다. 쉽게 설명하자면 HH, WW, CC 크기의 피쳐맵들을 1, 1, C크기로 만든 것입니다. zczc는 채널 CC 의 원소 중 하나가 됩니다.
식 2에서는 ReLU 함수와 Sigmoid 함수를 사용하며, r은 reduction ratio 를 뜻한다. (이 실험에서는 r = 16) 마지막 출력에서는 입력 x를 활성화 s 로 Re-weighting 하여 얻는다. 식 3에서 X는 각 특징은 리스케일링 작업으로 향상되거나, 약화된다.

Network Configurations
이러한 세가지 모듈로 이루어진 M2Det 의 네트워크 구성의 세부사항은 다음과 같다.
기본 백본을 VGGnet 과 Mask R-CNN 으로 설정하였다. 전체 신경망을 학습하기 전에 ImageNet 2012 데이터 세트에서 백본을 사전에 훈련해야한다. MLFPN의 모든 기본 구성에는 8개의 TUM이 포함되어 있으며, 각 TUM에는 5개의 striding-convs 및 5개의 업샘플링 작업이 있으므로 6개의 스케일로 특징을 출력한다.
매개변수의 수를 줄이려면 각 스케일의 TUM 기능에 256개의 채널만 할당하므로, 신경망에서 GPU를 쉽게 학습 할 수 있다. 입력 크기는 원래 SSD, RefineDet 및 RetinaNet, 즉 320, 512, 800 크기를 따른다. 검출 단계에서 6개의 피라미드 특징 각각에 2개의 conv 레이어를 추가하여 Location 회귀 및 분류를 달성한다.
6개의 특징 맵에서 default box 의 검출 스케일 범위는 원래 SSD 의 설정을 따른다. 입력 크기가 800 x 800 이라면, 가장 큰 특징 맵의 최소 크기를 유지하는 것을 제외하고 스케일의 범위가 비례적으로 증가한다. 피라미드 특징의 각 픽셀에서 3개의 비율로 6개의 앵커(Anchor) 를 설정했다. 이후에 낮은 스코어를 가지는 앵커를 걸러내기 위해 임계값으로 0.05 의 점수를 사용하였다.
그 다음 Post-processing 을 위해 선형 커널(Linear-kernel) 과 함께 soft-NMS를 사용하여 경계 상자를 탐지한다. 임계값을 0.01 로 줄이면 더 나은 검출 결과를 얻을 수 있지만, 추론 시간이 많이 느려질 수 있으므로 더 나은 값을 얻기 위해 고려하지는 않았다.
Experiments
실험은 MS-COCO를 통해 수행되었다.

위 표에는 최신 검출기들의 성능이 표시되어있다. M2Det 은 8개의 TUM을 사용하였고, 각 TUM에 대해 256개의 채널을 설정하여 실험하였다고 한다.
정확도 측면에서는 VGG 백본인 M2Det-320 의 AP는 38.9 로 이보다 강력한 백본을 가지고 있는 방법들이나 더 큰 입력 크기를 가진 객체 탐지기들보다 더 좋은 성능을 보여준다. ResNet-101 백본을 사용한 M2Det 은 AP 38.8 을 기록하였다. 이 결과는 Two-stage Detector 인 Mask R-CNN 과 경쟁할만하다.
또한 속도 측면에서는 Pytorch 최적화를 기반으로 15.8 FPS 를 달성한다고 한다.
RefineDet 은 One-stage Detector 와 Two-stage Detector 의 장점을 결합하여 AP는 41.8 을 달성하였고, CornetNet은 검출을 위해 Key Point 회귀를 제안하고, Hourglass 및 Focal Loss 의 결합에 따라 AP 42.1 을 달성하였다. 대조적으로 M2Det 은 SSD 의 회귀 방식을 따르며, 멀티스케일 및 멀티레벨 특징의 도움으로 AP 44.2 를 달성한다. 이는 모든 One-stage Detector 의 성능을 능가한다.
대부분의 접근법은 사용된 방식이나 트릭이 다르기 때문에 멀티 스케일 추론을 사용한 방식의 속도는 비교하지 않는다. 또한 M2Det 의 주요 사항이 모델이 깊이가 깊어지거나 더 많은 매개변수가 사용되는 것이 아니라는 것을 강조하기 위해 One-stage Detector 와 Two-stage Detector 를 비교한다.
Hourglass 모듈이 있는 CornerNet 에는 201M 개의 매개변수가 있고, ResNeXt-101-32x8d-FPN 은 205M개의 파라미터가 존재한다. 이와는 대조적으로 M2Det800-VGG는 147M 개의 매개변수를 가진다.
Ablation study
M2Det 은 많은 모듈들로 구성되어있기 때문에 아래와 같이 나누어 Ablation study 를 진행하였다. 베이스라인은 SSD (320 x 320) 사이즈 및 VGG-16 백본을 이용하였다.
TUM
TUM의 효과를 설명하기 위해 세가지 실험을 수행하였는데, DSSD에 이어 일련의 Deconv 레이어로 검출기를 확장하고, 아래 표에서 세번째 열에 표시된 것 처럼 27.5 로 개선되었고 MLFPN 으로 변경한다. Ushape 모듈의 경우 먼저 8개의 s-TUM들을 쌓아 1x1 conv 레이어를 줄이도록 수정하였더니 3.1 만큼 성능이 향상하였다. 마지막으로 s-TUM을 TUM으로 바꾸면 30.8 의 AP 를 기록한다.
Base Feature
TUM을 쌓으면 검출 기능이 향상될 수 있지만, 첫번째 TUM의 입력 채널에 의해 제한된다. 즉, 채널을 줄이면 MLFPN의 추상화가 중단되고, 채널을 늘리면 매개 변수 수가 크게 증가한다. 베이스 특징을 한번만 사용하는 대신 각 TUM 입력에 베이스 특징을 사용하여 문제를 완화한다. 각 TUM에 내장된 베이스 특징은 얕은 특징들을 포함하기 때문에 필요한 local 정보들을 제공한다. AP 는 역시 32.7 로 증가한다.
SFAM
SFAM이 없는 아키텍쳐와 비교해도 성능이 올라간다. 특히 작은, 중간 및 큰 상자를 포함한 모든 경계 상자들이 더 정확한 결과 값을 가지게 된다.
Backbone feature
백본 신경망으로는 VGG-16 대신 잘 테스트 된 ResNet-101 을 사용하면 33.2 에서 34.1 까지 성능 개선을 볼 수 있다.

여기서 이제 얼마나 많은 TUM 이 필요한 것인가에 대한 의문이 들 때가 되었다.
아래 표와 같이 백본을 VGG-16 으로 고정하고, 입력 이미지 크기를 320 x 320 으로 고정한 다음, TUM 수와 각 TUM의 내부 채널 수를 조정한다. 결론적으로는, 채널이 고정되어있을 때, 많은 TUM을 쌓을 수록 검출 정확도가 향상된다. 그 다음 TUM 수를 고정하면 채널이 많을수록 결과가 좋게 나온다. TUM 2개와 채널을 128 로 고정해두면, 내부 채널을 늘리는 것 보다 많은 TUM 수를 사용하는 것이 더 큰 향상을 가져올 수 있지만, 매개변수의 증가는 비슷하게 이루어진다.

속도에 대한 실험은 그림으로 확인하는 것이 더 파악하기 쉽다.

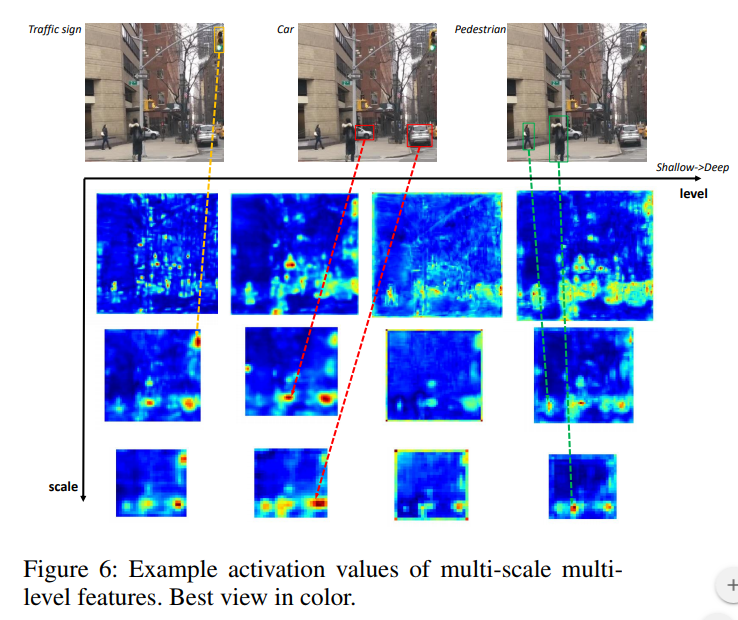
결론적으로, M2Det 은 멀티레벨, 멀티스케일 특징을 사용하게 되므로 Introduction 에서 설명하였던 객체 인스턴스 마다 모양이 복잡하고, 특징이 복잡한 변화들을 처리하는데 훨씬 효과적으로 객체 검출을 할 수 있다. 아래 그림과 같이, 신호등과 먼 거리의 사람의 크기가 같더라도, 사람의 얼굴의 특징이 더 복잡하기 때문에 이와 같은 어려운 object detection 의 문제들은 멀티스케일 및 멀티레벨 특징을 이용하여 검출을 하는 것이 효과적이다.
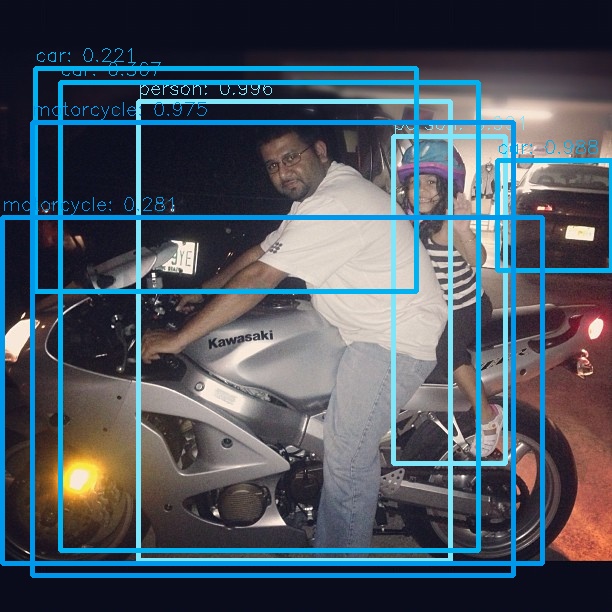
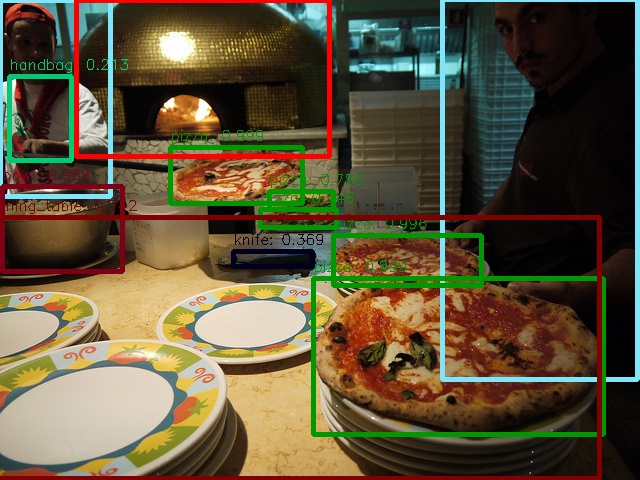
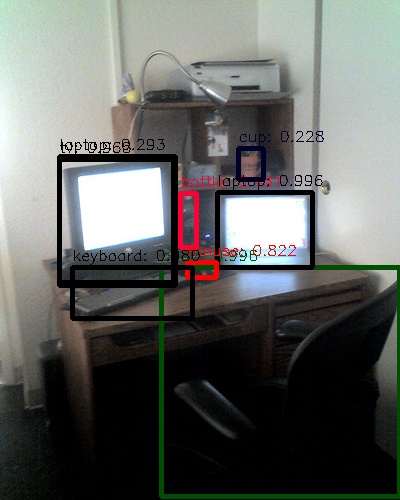
다음은 Github 의 Demo 를 실행해본 결과이다.
실제로 cam 을 이용하여 RTX 2080 환경에서 테스트 했을 때도 11 ~ 15 FPS 의 성능을 도달하며,
확실히 Yolo v3 보다 검출 성능이 우수한 것을 확인 할 수 있었다.





Paper : https://arxiv.org/abs/1811.04533
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
Feature pyramids are widely exploited by both the state-of-the-art one-stage object detectors (e.g., DSSD, RetinaNet, RefineDet) and the two-stage object detectors (e.g., Mask R-CNN, DetNet) to alleviate the problem arising from scale variation across obje
arxiv.org
Github : https://github.com/qijiezhao/M2Det
qijiezhao/M2Det
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network - qijiezhao/M2Det
github.com
참고자료 1 : 멀티 스케일 테스팅
https://hoya012.github.io/blog/Tutorials-of-Object-Detection-Using-Deep-Learning-performance-two/
“Tutorials of Object Detection using Deep Learning [6] Object Detection Multi Scale Testing Method Review”
Deep Learning을 이용한 Object detection Tutorial - [6] Object Detection Multi Scale Testing Method Review
hoya012.github.io
참고자료 2 : SE block
'AI Research Topic > Object Detection' 카테고리의 다른 글
| [Paper Review] Imbalance Problems in Object Detection : A Review (1) | 2020.01.30 |
|---|---|
| [Object Detection] darknet 으로 Gaussian YOLOv3 학습하기 (linux) (0) | 2020.01.29 |
| [Object Detection] Gaussian YOLOv3 (0) | 2019.12.27 |
| [Object Detection] darknet custom 학습하기 (83) | 2019.10.16 |
| [Object Detection] COCO Category 91 vs 80 (3) | 2019.10.08 |