
[Object Detection] EfficientNet and EfficientDet
- 1. EfficientNet : Improbing Accuracy and Efficiency through AutoML and Model Scaling
- 2. EfficientDet:Scalable and Efficient Object Detection
1. EfficientNet
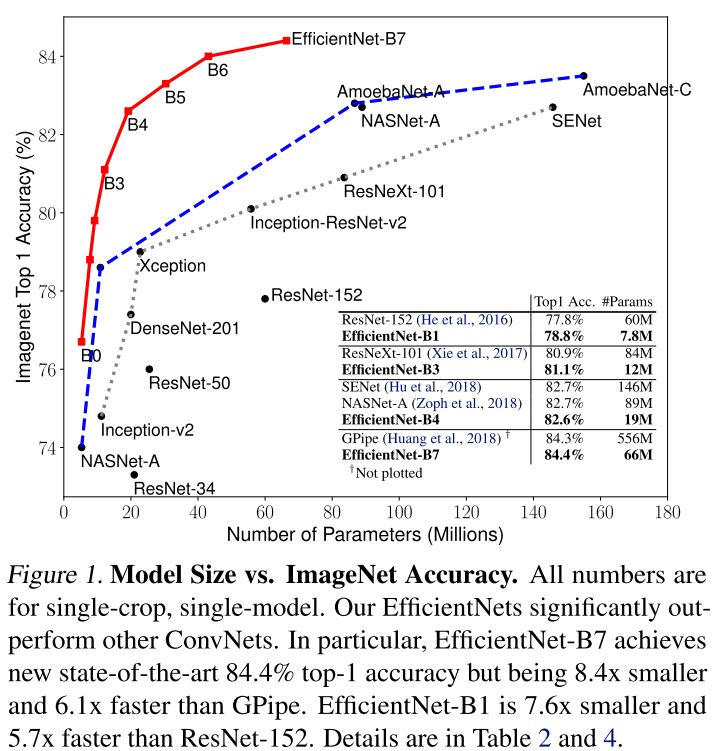
EfficientNet 은 위 그래프와 같이 압도적인 성능을 자랑한다. 위 그림 1에서도 알 수 있듯 EfficientNet-B7 이 GPipe 를 능가하였으며, 그럼에도 불구하고 파라미터의 사용량은 1/8 수준이다. 또한 실제 inference time 도 6배 빠르다고 한다. 이러한 성능이 가능했던 이유는 "compound cofficient" 를 사용하여 모든 차원의 깊이(depth) / 폭 (width) / 해상도(resolution) 를 균일하게 스케일링 하는 방법을 사용했기 때문이다. 먼저 Model Scaling 기법 부터 살펴보자면 아래와 같다.
Model Scaling
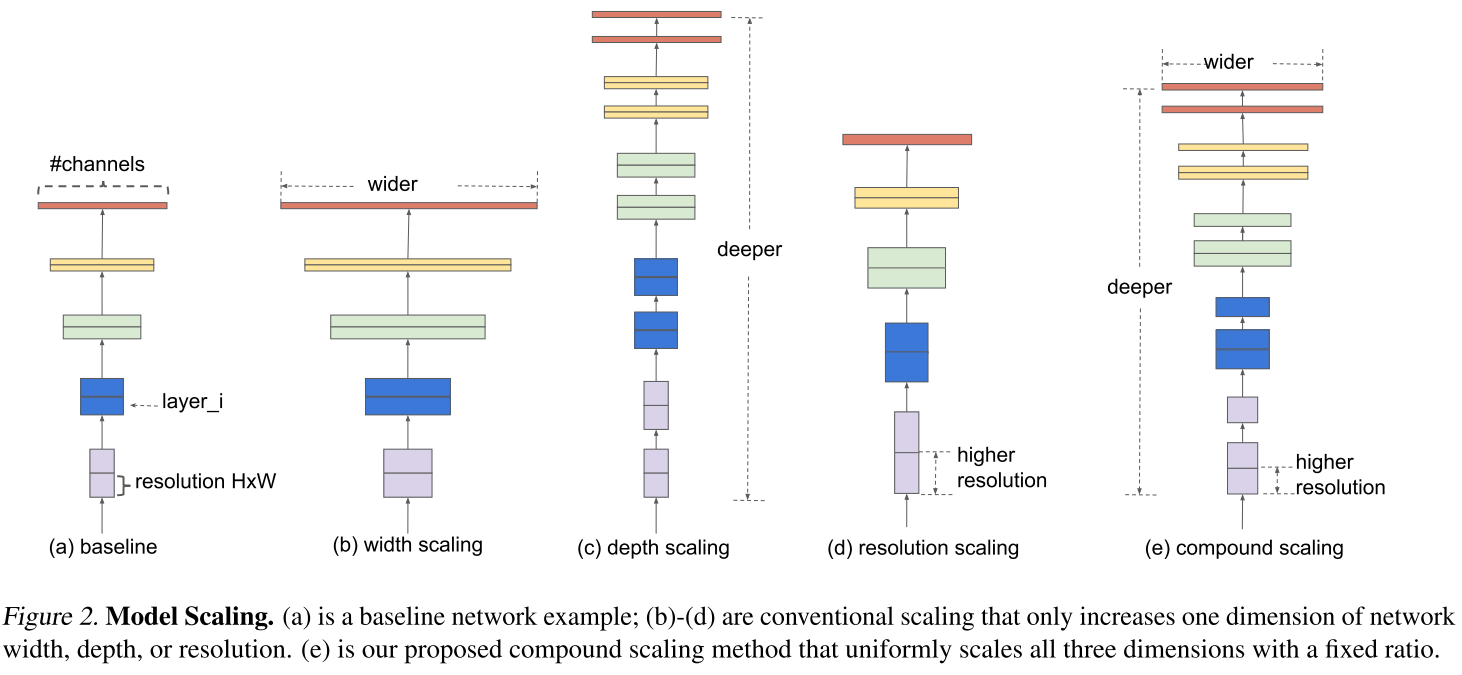
- baseline network
- 가장 기본적인 신경망 구조
- width scaling
- filter (= channel) 의 수를 늘려서 scale-up 하는 방법
- width 를 제어하는 모델은 대게 작은 크기의 모델들이다.
- 기존 연구에 따르면 width 를 넓게 할 수록 미세한 정보(fine-grained feature)들을 더 많이 담을 수 있다고 한다.
- depth scaling
- layer 의 수를 늘려서 scale-up 하는 방법
- 가장 흔한 scale 방식이
- 깊은 신경망은 더 좋은 성능을 달성 할 수 있으나 신경망을 계속 깊게 쌓는 것은 한계가 있다. 실제로 ResNet-1000 과 ResNet-101 은 거의 비슷한 성능을 가진다.
- resolution scaling
- input image 의 해상도를 높여서 scale-up 하는 방법
- 최신 연구인 GPipe 에서는 480 x 480 크기를 사용하였다.
- 또한 object detection 영역에서는 600 x 600 을 사용하면 더 좋은 성능을 보인다고 한다.
- compound scaling
- 이 논문에서 제안하는 방법
- width + depth + resolution 을 적절하게 조절하여 정확도를 높이고자함
위 그림(b) ~ (e)는 존재하는 모델의 width, depth, resolusion 의 size 를 키우는 여러 스케일 방법을 설명하고있다. 대표적인 신경망 모델인 ResNet 은 depth scaling 을 적용시킨 대표적인 모델이다. 또한 MobileNet, ShuffleNet 등이 width scaling 을 적용시킨 대표적인 모델이다. 이 논문에서는 이러한 여러 scaling 기법들을 동시에 고려하는 경우는 없다고 말하고 있다.
또한 세 가지의 scaling 기법 중에 어떤 것을 조절해야 정확도가 오르는지에 대해서 실험을 수행하였다.
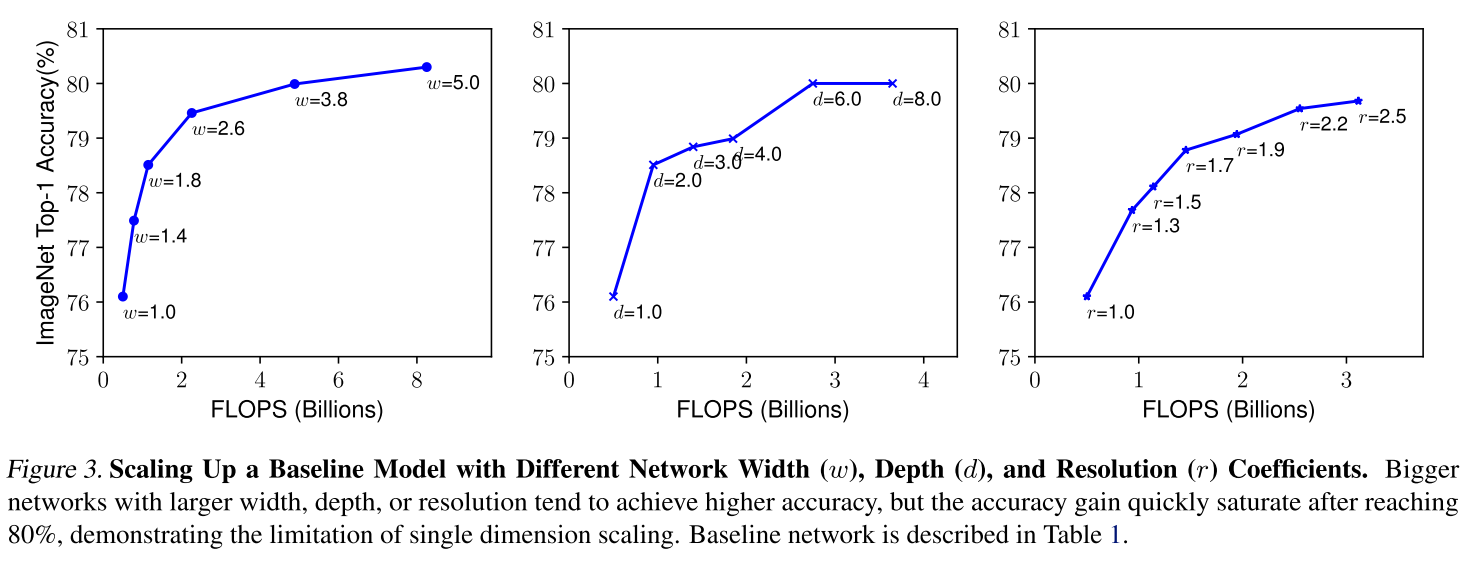
위 그래프를 보면 width 나 depth scaling 같은 경우 사이즈를 키우는데 비교적 이른 시점에 값이 수렴되는 것을 볼 수 있는데, 이에 비해 resolution은 값을 키우면 키울수록 정확도가 향상하는 것을 볼 수 있다. 하지만 전체적으로 봤을 때 width / depth / resolution 을 키우면 성능이 올라가긴 하지만, 점점 커질 수록 얻어지는 이득은 적어진다는 것을 알 수 있다.
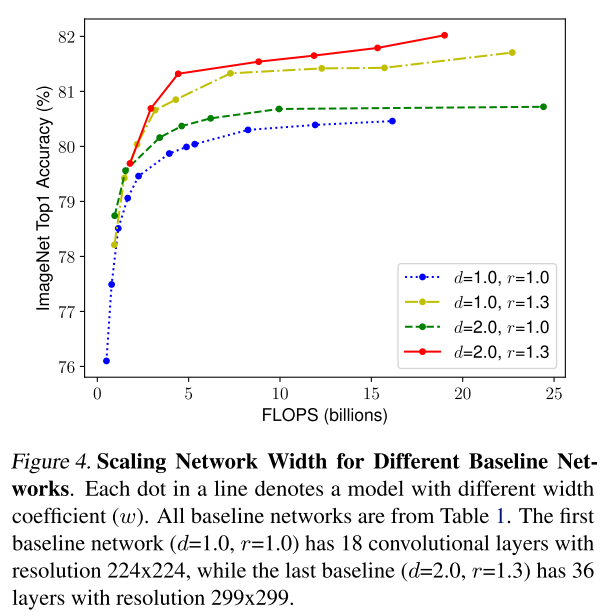
또한 위와 같이 width 를 고정시켜놓고 depth 와 resolution 의 값을 조절해가면서 정확도를 측정한 결과를 보면, depth 를 키우는 것 보다는 resolution 을 키우는 것이 더 효과적임을 알 수 있고, 세 가지 요소의 크기를 동시에 키우는 것이 가장 성능이 좋다는 것을 보여주고있다. 이러한 입증을 통하여 논문의 저자는 어떠한 모델 F 를 고정하고 depth, width, resolution 3가지를 조절하는 것을 제안하고 있다. 이 때 어떠한 모델 F는 초기 모델 자체의 성능이 낮을 경우 값들을 조절했을 때 결과도 낮게 나올 것 이므로 성능이 좋은 모델이어야한다. 이 논문에서는 MnasNet 과 거의 동일한 search space 하에서 AutoML을 통해 모델을 탐색하여 찾은 작은 모델을 EfficientNet-B0 라고 부르고있다.
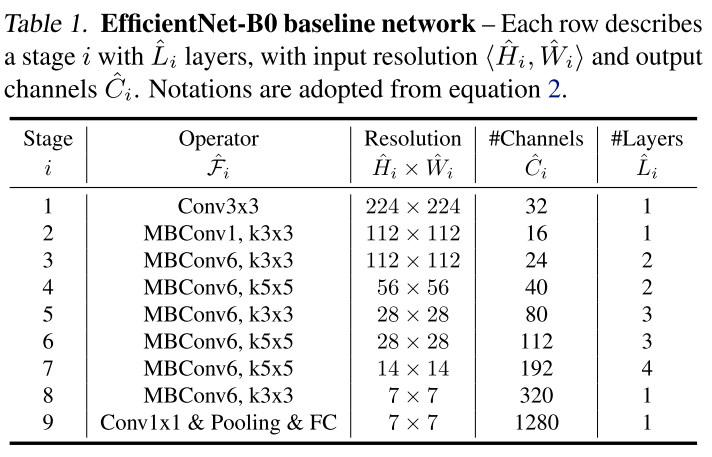
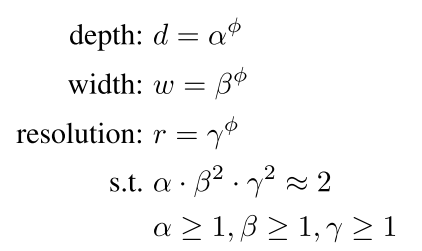
이 때 depth(알파), width(베타), resolution(감마) 은 간단한 grid search 를 통해 구하는 방식을 제안하고 있으며, 처음 단계 에서는 파이를 1로 고정한 뒤, 타겟 데이터 셋에서 좋은 성능을 보이는 값들을 찾아낸다. 본 논문에서 알파 값은 1.2 베타 값은 1.1 감마 값은 1.15를 사용하고 있으며, 이 scaling factor 를 고정한 뒤 파이를 키워주며 모델의 사이즈를 키워준다. 기존 사람이 설계한 ConvNet, AutoML 을 통해 찾은 ConvNet 들과 비교한 결과는 다음과 같다.
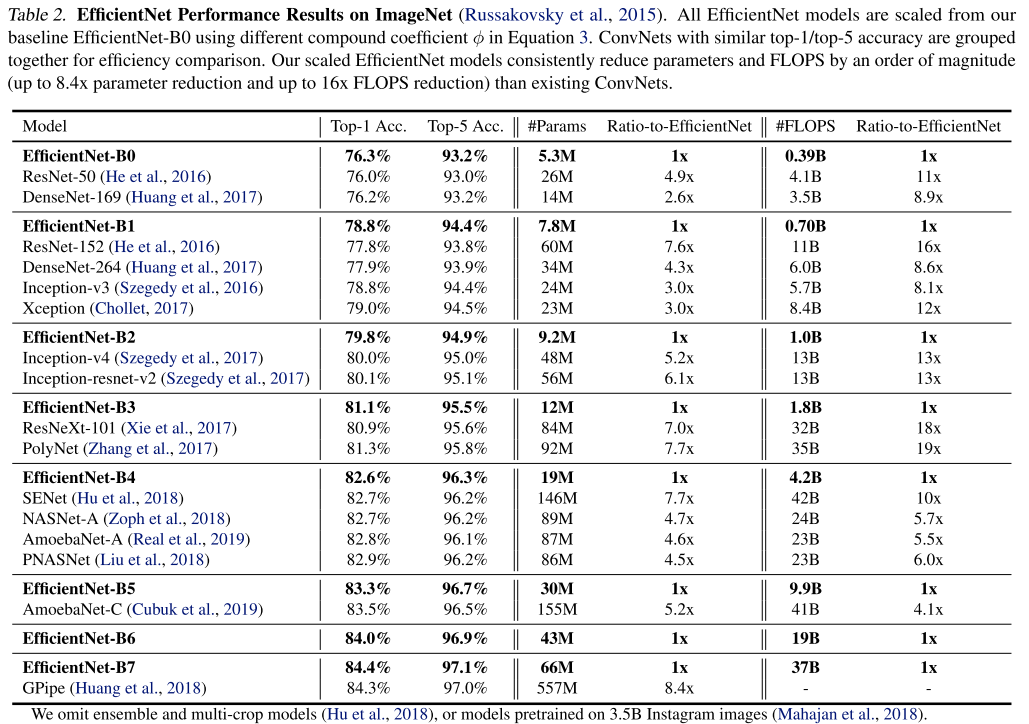
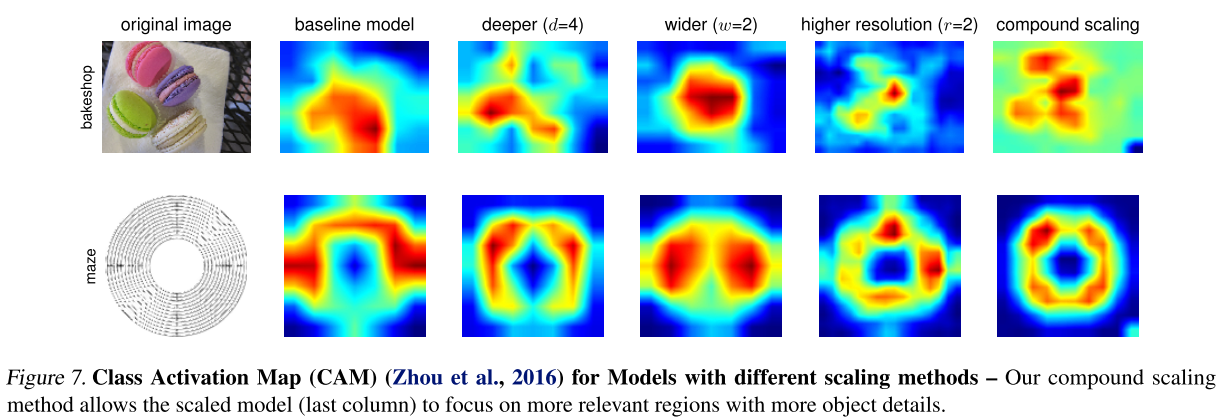
위 결과는 이미지 분류 시 class activation map 의 결과인데, 3개의 scaling factor 를 각각 고려할 때 보다 동시에 고려했을 때(compound scaling)가 더 정교한 CAM를 얻을 수 있음을 확인 할 수 있다.
2. EfficientDet
EfficientDet 은 위에서 언급한 "EfficientNet : Improbing Accuracy and Efficiency through AutoML and Model Scaling" 의 저자들이 속한 Google Brain 팀에서 쓴 논문이다.
여기서 BiFPN(bi-directional feature pyramid network)을 제안하였다. 이는 기존 FPN에서 레이어마다 가중치를 주어 좀 더 각각의 층에 대한 해상도 정보가 잘 들어갈 수 있도록 하는 트릭이다. 본 논문이 가지는 차별점은 다음과 같다.
- Efficient multi-scale feature fusion
- 본 논문에서는 기존 FPN을 사용하는 선행 연구들이 모두 서로 다른 input feature 들을 합칠 때 구분없이 단순히 더하는 방식을 사용하고 있음을 지적하였다.
- 서로 다른 input feature 들은 해상도가 다르기 때문에 output feature 에 기여하는 정도를 다르게 가져가야함을 주장하였다. 단순히 더하기만 한다면 같은 weight 로 기여하기 때문이다.
- 그래서 간단하지만 효과적인 weighted bi-directional FPN(BiFPN) 구조를 제안한다.
- Model scaling
- EfficientNet 에서 제안한 Compound Scaling 기법은 모델의 크기와 연산량을 결정하는 요소들인 width, depth, resolution 을 동시에 고려하여 모델의 사이즈를 증가시키는 방법을 의미한다. 이러한 아이디어를 EfficientDet의 backbone, feature network, box/class prediction network 등 모든 곳에 적용하였다.
Cross-scale Connections
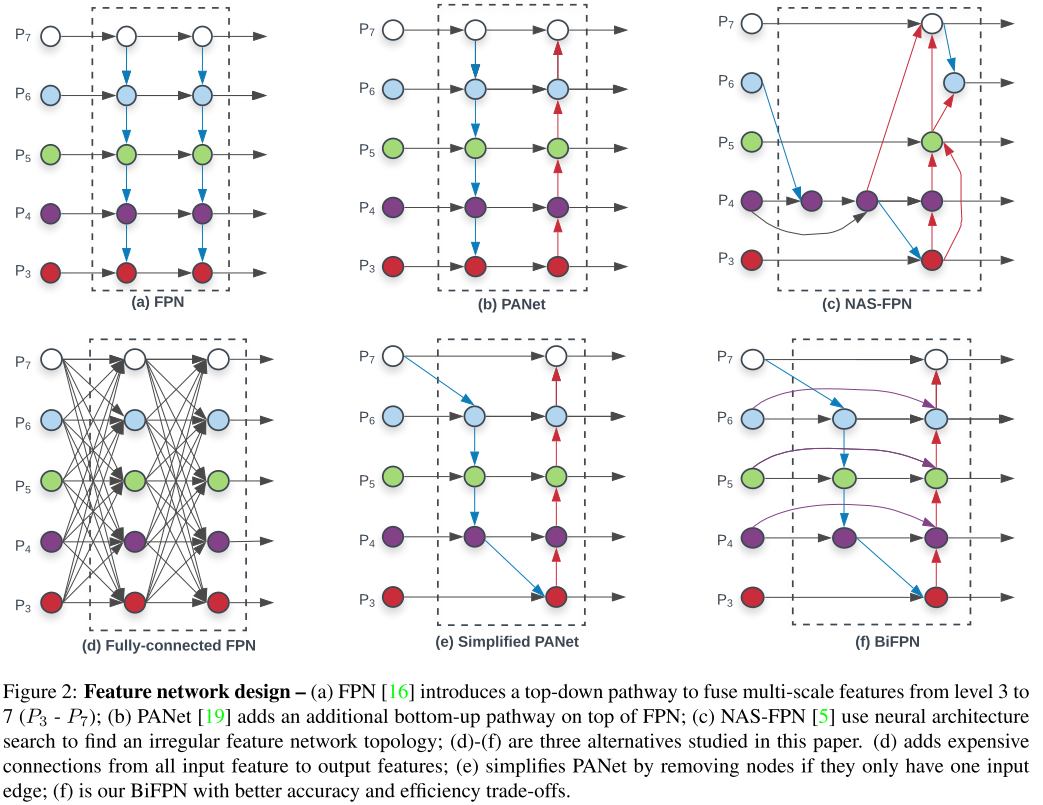
FPN 을 이용한 방법들을 모아둔 그림은 위와 같다.
(a) 전통적인 FPN 구조 (같은 scale 에만 connection 이 존재)
(b) PANet 은 추가로 bottom-up pathway 를 FPN에 추가한 방법 (같은 scale 에만 connection 이 존재)
(c) AutoML의 Neural Architecture Search 를 FPN에 적용시킨 방법 (scale 이 다른 경우에도 connection 이 존재하는 Cross-Scalse Connection 적용)
(d) 와 (e) 는 본 논문에서 추가로 제안하고 실험한 방식
(f) 본 논문에서 제안하는 BiFPN 구조
Weighted Feature Fusion
기존 FPN 에서는 서로 다른 resolution 의 input feature 들을 합칠 때, 같은 해상도가 되도록 resize 를 시킨 뒤 합치는 방식을 사용한다. 본 논문에서는 이러한 점을 개선하기 위해 input feature 에 가중치를 주고, 학습을 통해 가중치를 배울 수 있는 방식을 제안하였다.
weight 아래와 같이 세 가지 방식으로 줄 수 있다.
- scalar ( = per-feature)
- vector ( = per-channel)
- multi-dimensional tensor ( = per-pixel)
본 논문에서는 scalar 를 사용하는 것이 정확도와 연산량 측면에서 효율적임을 실험을 통해서 밝혔고, scalar weight 를 사용하였다고 한다. input feature 에 가중치를 주는 Weighted Feature Fusion 방법은 아래와 같이 세가지로 나뉜다.
- Unbounded Feature Fusion
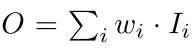
이는 unbound 되어있기 때문에 학습에 불안정성을 유발할 수 있어서 weight normalization 을 사용하였다고 한다.
- SoftMax-based Feature Fusion
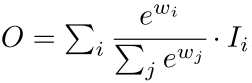
Softmax 를 사용한 것인데 이는 GPU 하드웨어에서 slowdown 을 유발한다고 한다.
- Fast normalized Feature Fusion
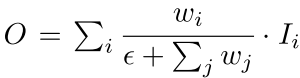
weight 들은 ReLU를 거치기 때문에 non-zero 임이 보장되고, 분모가 0이 되는 것을 막기 위해 0.0001 크기의 입실론을 넣어준다. weight 값이 0~1 사이로 nomalize 가 되는 것인 Softmax 와 유사하며 ablation study 를 통해 softmax-based fusion 방식보다 좋은 성능임을 보여주고 있다고 한다.
위 BiFPN 을 기반으로 EfficientDet 이라는 One-stage Detector 구조를 제안하였다.
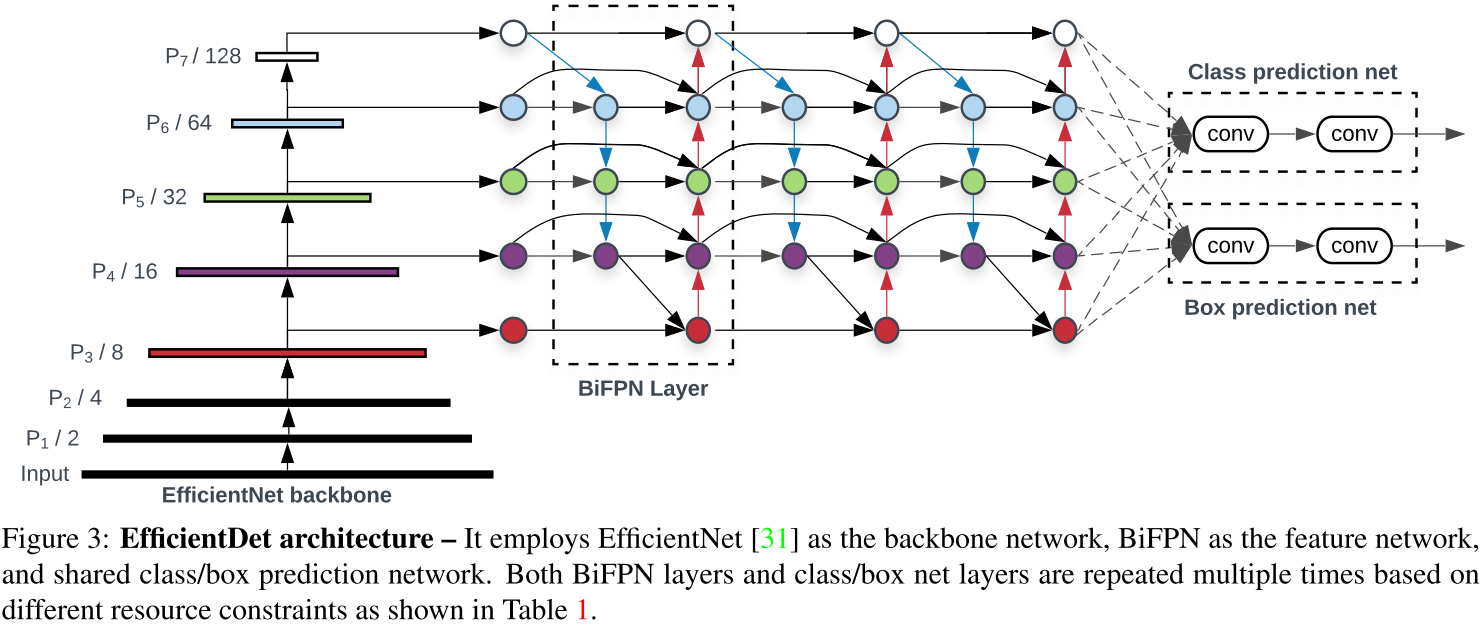
EfficientDet 의 backbone 으로는 ImageNet-pretrained EfficientNet 을 사용하였으며, BiFPN 을 Feature Network 로 사용하였고, level 3-7 feature 에 적용하였다. 또한 top-down , bottom-up bidirectional feature fusion 을 반복적으로 사용하였다.
기존 Compound Scaling 처럼 input 의 resolution 과 backbone network 의 크기를 키워주었으며, BiFPN 과 Box/class network 도 동시에 키워 다음과 같이 실험결과를 내뱉었다.

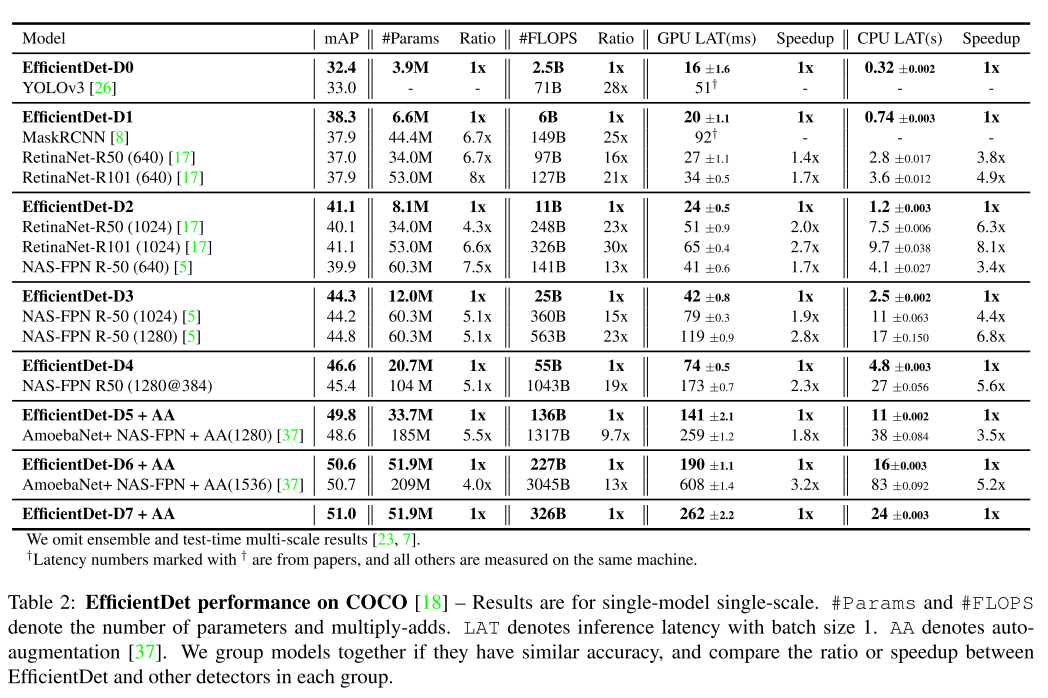
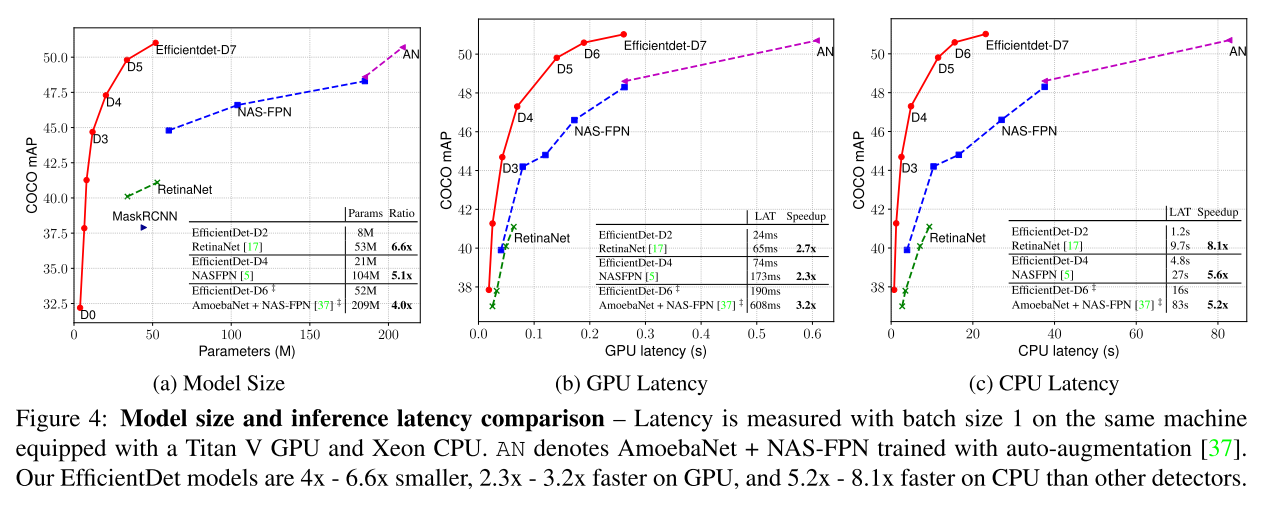
참고자료 1 : https://hoya012.github.io/blog/EfficientNet-review/
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 리뷰
ICML 2019에 제출된 “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks” 논문에 대한 리뷰를 수행하였습니다.
hoya012.github.io
참고자료 2 : https://norman3.github.io/papers/docs/efficient_net
EfficientNet: Rethinking Model Scaling for CNN.
참고로 그림 2(a) 에서 입력 크기는 \(<224, 224, 3>\) 이고, 출력 크기는 \(<7, 7, 512>\) 이다.
norman3.github.io
참고자료 3 : https://hoya012.github.io/blog/EfficientDet-Review/
EfficientDet : Scalable and Efficient Object Detection Review
“EfficientDet: Scalable and Efficient Object Detection
hoya012.github.io
참고자료 4 : https://arxiv.org/abs/1911.09070
EfficientDet: Scalable and Efficient Object Detection
Model efficiency has become increasingly important in computer vision. In this paper, we systematically study various neural network architecture design choices for object detection and propose several key optimizations to improve efficiency. First, we pro
arxiv.org
참고자료 5 : https://arxiv.org/abs/1905.11946
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing n
arxiv.org
'AI Research Topic > Object Detection' 카테고리의 다른 글
| [Object Detection] Soft NMS (0) | 2020.03.08 |
|---|---|
| [Object Detection] Deformable Convolutional Networks (0) | 2020.03.08 |
| [Object Detection] The Car Connection Picture Dataset (4) | 2020.02.03 |
| [Paper Review] Imbalance Problems in Object Detection : A Review (1) | 2020.01.30 |
| [Object Detection] darknet 으로 Gaussian YOLOv3 학습하기 (linux) (0) | 2020.01.29 |