
사람은 역시 기본에 충실해야 하므로 ...
딥러닝의 기본중 기본인 배치 정규화(Batch Normalization)에 대해서 정리하고자 한다.
배치 정규화 (Batch Normalization) 란?
배치 정규화는 2015년 arXiv에 발표된 후 ICML 2015에 게재된 아래 논문에서 나온 개념이다.
Batch Normalization: Accelerating Deep Network Training b y Reducing Internal Covariate Shift
https://arxiv.org/pdf/1502.03167.pdf
Gradient Vanishing / Exploding 문제
신경망에서 학습시 Gradient 기반의 방법들은 파라미터 값의 작은 변화가 신경망 출력에 얼마나 영향을 미칠 것인가를 기반으로 파라미터 값을 학습시키게 된다. 만약 파라미터 값의 변화가 신경망 결과의 매우 작은 변화를 미치게 될 경우 파라미터를 효과적으로 학습 시킬 수 없게 된다. Gradient 라는 것이 결국 미분값 즉 변화량을 의미하는데 이 변화량이 매우 작아지거나(Vanishing) 커진다면(Exploding) 신경망을 효과적으로 학습시키지 못하고, Error rate 가 낮아지지 않고 수렴해버리는 문제가 발생하게 된다.
그래서 이러한 문제를 해결하기 위해서 Sigmoid 나 tanh 등의 활성화 함수들은 매우 비선형적인 방식으로 입력 값을 매우 작은 출력 값의 범위로 squash 해버리는데, 가령 sigmoid는 실수 범위의 수를 [0, 1]로 맵핑해버린다. 이렇게 출력의 범위를 설정할 경우, 매우 넓은 입력 값의 범위가 극도로 작은 범위의 결과 값으로 매핑된다. 이러한 현상은 비선형성 레이어들이 여러개 있을 때 더욱 더 효과를 발휘하여(?) 학습이 악화된다. 첫 레이어의 입력 값에 대해 매우 큰 변화량이 있더라도 결과 값의 변화량은 극소가 되어버리는 것이다. 그래서 이러한 문제점을 해결하기 위해 활성화 함수로 자주 쓰이는 것이 ReLU(Rectified Linear Unit) 이다. 또한 아래와 같은 방법들도 존재한다.
- Change activation function : 활성화 함수 중 Sigmoid 에서 이 문제가 발생하기 때문에 ReLU 를 사용
- Careful initialization : 가중치 초기화를 잘 하는 것을 의미
- Small learning rate : Gradient Exploding 문제를 해결하기 위해 learning rate 값을 작게 설정함
위와 같은 트릭을 이용하여 문제를 해결하는 것도 좋지만, 이러한 간접적인 방법 보다는 "학습하는 과정 자체를 전체적으로 안정화"하여 학습 속도를 가속 시킬 수 있는 근본적인 방법인 "배치 정규화(Batch Normalization)"를 사용하는 것이 좋다. 이는 위와 마찬가지로 Gradient Vanishing / Gradient Exploding이 일어나는 문제를 방지하기 위한 아이디어이다.
정규화(Normalization)
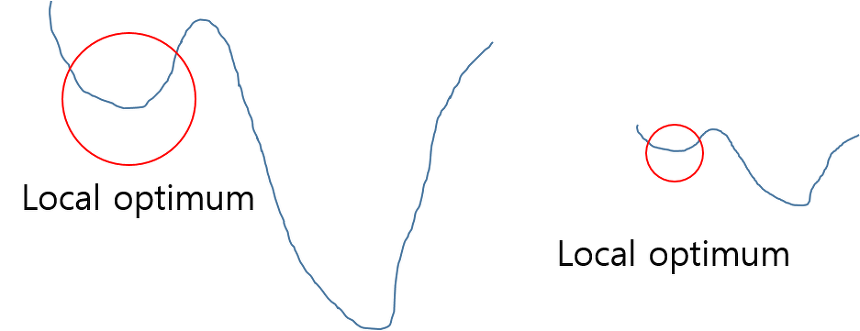
기본적으로 정규화를 하는 이유는 학습을 더 빨리 하기 위해서 or Local optimum 문제에 빠지는 가능성을 줄이기 위해서 사용한다. 아래 그림을 보면 이해가 쉽게 될 것 같다. 아래 그림에서 최저점을 찾을 때 그래프를 전체적으로 이해하지 못하여 global optimum 지점을 찾지 못하고 local optimum 에 머물러 있게 되는 문제가 발생하게 된다. 이러한 문제점은 정규화 하여 그래프를 왼쪽에서 오른쪽으로 만들어, local optimum 에 빠질 수 있는 가능성을 낮춰주게 된다.
Internal Covariance Shift
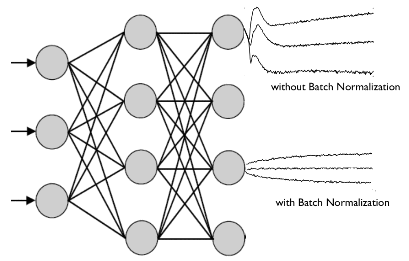
배치 정규화 논문에서는 학습에서 불안정화가 일어나는 이유를 'Internal Covariance Shift' 라고 주장하고 있는데, 이는 네트워크의 각 레이어나 Activation 마다 입력값의 분산이 달라지는 현상을 뜻한다.
Covariate Shift : 이전 레이어의 파라미터 변화로 인하여 현재 레이어의 입력의 분포가 바뀌는 현상
Internal Covariate Shift : 레이어를 통과할 때 마다 Covariate Shift 가 일어나면서 입력의 분포가 약간씩 변하는 현상

Whitening 의 문제점
이 현상을 막기 위해서 간단하게 각 레이어의 입력의 분산을 평균 0, 표준편차 1인 입력값으로 정규화 시키는 방법을 생각해볼 수 있다. 이는 Whitening 이라고 일컫는데, 백색 잡음으로 생각하면 될 것 같다. 또한 Whitening은 기본적으로 들어오는 입력값의 특징들을 uncorrelated 하게 만들어주고, 각각의 분산을 1로 만들어주는 작업이다. 이는 covariance matrix의 계산과 inverse의 계산이 필요하기 때문에 계산량이 많을 뿐더러, Whitening은 일부 파라미터들의 영향이 무시된다. 예를 들어 입력 값 X를 받아 Z = WX + b 라는 결과를 내놓고 적절한 bias b 를 학습하려는 네트워크에서 Z에 E(Z) 를 빼주는 작업을 한다고 생각해보면, 이 과정에서 b 값이 결국 빠지게 되고, 결과적으로 b의 영향은 없어지게 된다. 단순히 E(Z)를 빼는 것이 아니라 표준편차로 나눠주는 등의 scaling 과정까지 포함될 경우 이러한 경향은 더욱 악화 될 것이며, 논문에서 실험으로 확인을 했다고 한다. 이렇듯 단순하게 Whitening만을 시킨다면 이 과정과 파라미터를 계산하기 위한 최적화(Backpropagation)과 무관하게 진행되기 때문에 특정 파라미터가 계속 커지는 상태로 Whitening 이 진행 될 수 있다. Whitening 을통해 손실(Loss)이 변하지 않게 되면, 최적화 과정을 거치면서 특정 변수가 계속 커지는 현상이 발생할 수 있다.
배치 정규화 (Batch Normalization)
이러한 Whitening의 문제점을 해결하도록 한 트릭이 배치 정규화이다. 배치 정규화는 평균과 분산을 조정하는 과정이 별도의 과정으로 떼어진 것이 아니라, 신경망 안에 포함되어 학습 시 평균과 분산을 조정하는 과정 역시 같이 조절된다는 점이 단순 Whitening 과는 구별된다. 즉, 각 레이어마다 정규화 하는 레이어를 두어, 변형된 분포가 나오지 않도록 조절하게 하는 것이 배치 정규화이다.

배치 정규화는 간단히 말하자면 미니배치의 평균과 분산을 이용해서 정규화 한 뒤에, scale 및 shift 를 감마(γ) 값, 베타(β) 값을 통해 실행한다. 이 때 감마와 베타 값은 학습 가능한 변수이다. 즉, Backpropagation을 통해서 학습이 된다.
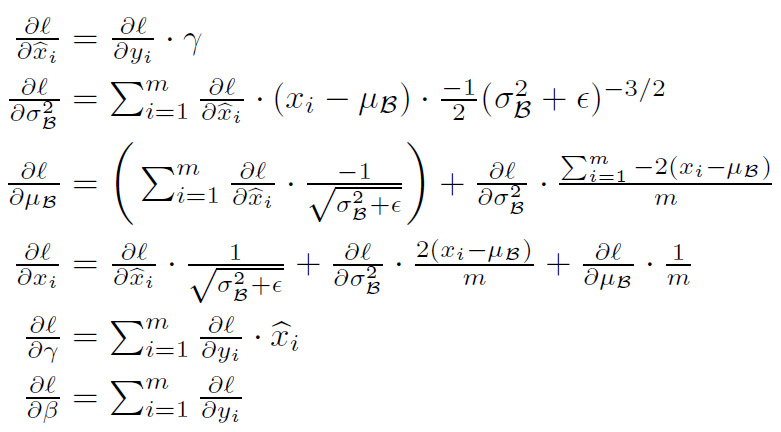
이렇게 정규화 된 값을 활성화 함수의 입력으로 사용하고, 최종 출력 값을 다음 레이어의 입력으로 사용하는 것이다.
기존 output = g(Z), Z = WX + b 식은 output = g(BN(Z)), Z = WX + b 로 변경되는 것이다.
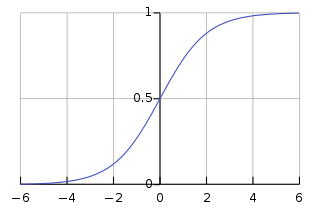
위 식에서 입실론(θ)은 계산할 때 0으로 나눠지는 문제가 발생하는 것을 막기 위한 수치적 안정성을 보장하기 위한 아주 작은 숫자이다(1e-5). 감마(γ) 값은 Scale 에 대한 값이며, 베타(β) 값은 Shift Transform 에 대한 값이다. 이들은 데이터를 계속 정규화 하게 되면 활성화 함수의 비선형 같은 성질을 잃게 되는데 이러한 문제를 완화하기 위함이다. 예를 들면 아래 그림과 같이 Sigmoid 함수가 있을 때, 입력 값이 N(0, 1) 이므로 95% 의 입력 값은 Sigmoid 함수 그래프의 중간 (x = (-1.96, 1.96) 구간)에 속하고 이 부분이 선형이기 때문이다. 그래서 비선형 성질을 잃게 되는 것이며, 이러한 성질을 보존하기 위하여 Scale 및 Shift 연산을 수행하는 것이다.
Inference 시의 배치 정규화
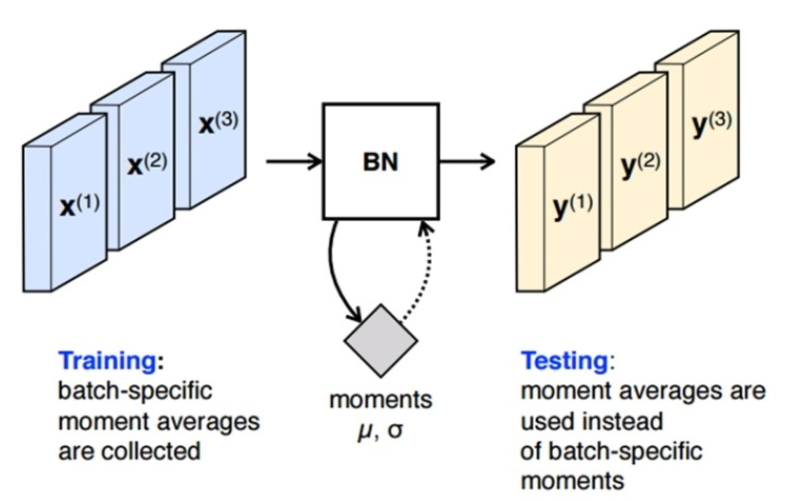
학습 시에는 배치 정규화의 미니 배치의 평균과 분산을 이용 할 수 있지만, 추론(inference) 및 테스트 할 때에는 이를 이용할 수 없다. inference 시 입력되는 데이터의 평균과 분산을 이용하면 배치 정규화가 온전하게 이루어지지 않는다. 애초에 배치 정규화를 통해 수행하고자 하는 것이 학습되는 동안 모델이 추정한 입력 데이터 분포의 평균과 분산으로 정규화를 하고자 하는 것인데 inference 시에 입력되는 값을 통해서 정규화를 하게 되면 모델이 학습을 통해서 입력 데이터의 분포를 추정하는 의미 자체가 없어지게 된다. 즉, inference 에서는 결과를 Deterministic 하게 하기 위하여 고정된 평균과, 분산을 이용하여 정규화를 수행하게 된다. 그래서 Train 모드와 Test 모드를 따로 두는 이유이기도 하다.

그래서 이러한 문제를 미리 저장해둔 미니 배치의 이동 평균(Moving Average)을 사용하여 해결한다. 즉, inference 전에 학습 시에 미리 미니 배치를 뽑을 때 Sample Mean 및 Sample Variance 를 이용하여 각각의 이동 평균을 구해놔야한다. 위 수식에서 Inference 시에 평균은 각 미니 배치에서 구한 평균들의 평균을 사용하고, 분산은 분산의 평균에 m/(m-1) 을 곱해주게 된다. 이를 곱하는 이유는 통계학적으로 unbiased variance 에는 "Bessel's correction"을 통해 보정을 해주는 것이다. 이는 학습 전체 데이터에 대한 분산이 아니라 미니 배치들의 분산을 통해 전체 분산을 추정할 때 통계학 적으로 보정을 위해 Bessel의 보정 값을 곱해주는 방식으로 추정하기 때문이다...
길이가 2인 경우의 이동 평균 예시는 다음과 같다. 처음엔 값이 100 하나 밖에 없기 때문에 이동 평균이 100이지만, 값이 업데이트 됨에 따라 가장 최근 2개 정보만을 통해 평균을 구한 것이 길이가 2인 경우의 이동 평균이다.
| 입력값 | 100 | 110 | 130 | 120 | 140 |
| 이동평균 | 100 | 105 | 120 | 125 | 130 |
CNN 구조에서의 배치 정규화
컨볼루션 레이어에서 활성화 함수가 입력되기 전에 WX + b 로 가중치가 적용되었을 때, b의 역할을 베타가 완벽히 대신 할 수 있기 때문에 b 를 삭제한다. 또한 CNN의 경우 컨볼루션 성질을 유지 시키고 싶기 때문에 각 채널을 기준으로 각각의 감마와 베타를 만들게 된다. 예를 들어 미니배치가 m 채널 사이즈가 n 인 컨볼루션 레이어에서 배치 정규화를 적용하면 컨볼루션을 적용한 후의 특징 맵의 사이즈가 p x q 일 경우, 각 채널에 대해 m x p x q 개의 스칼라 값(즉, n x m x p x q 개의 스칼라 값)에 대해 평균과 분산을 구한다. 최종적으로 감마 베타 값은 각 채널에 대해 한 개씩, 총 n개의 독립적인 배치 정규화 변수 쌍이 생기게 된다. 즉, 컨볼루션 커널 하나는 같은 파라미터 감마, 베타를 공유하게 된다.
결 론
결과적으로 정리해보자면, 배치 정규화의 알고리즘과, 배치 정규화의 장점은 다음과 같다.

- 배치 정규화는 단순하게 평균과 분산을 구하는 것이 아니라 감마(Scale), 베타(Shift) 를 통한 변환을 통해 비선형 성질을 유지 하면서 학습 될 수 있게 해줌
- 배치 정규화가 신경망 레이어의 중간 중간에 위치하게 되어 학습을 통해 감마, 베타를 구할 수 있음
- Internal Covariate Shift 문제로 인해 신경망이 깊어질 경우 학습이 어려웠던 문제점을 해결
- gradient 의 스케일이나 초기 값에 대한 dependency 가 줄어들어 Large Learning Rate 를 설정할 수 있기 떄문에 결과적으로 빠른 학습 가능함, 즉, 기존 방법에서 learning rate 를 높게 잡을 경우 gradient 가 vanish/explode 하거나 local minima 에 빠지는 경향이 있었는데 이는 scale 때문이었으며, 배치 정규화를 사용할 경우 propagation 시 파라미터의 scale 에 영향을 받지 않게 되기 때문에 learning rate 를 높게 설정할 수 있는 것임
- regularization 효과가 있기 때문에 dropout 등의 기법을 사용하지 않아도 됨 (효과가 같기 때문)
- 학습 시 Deterministic 하지 않은 결과 생성
- Learning Rate Decay 를 더 느리게 설정 가능
- 입력의 범위가 고정되기 때문에 saturating 한 함수를 활성화 함수로 써도 saturation 문제가 일어나지 않음, 여기서 saturation 문제란 가중치의 업데이트가 없어지는 현상임
참고자료 1 : https://ydseo.tistory.com/41
Vanishing gradient problem이란 무엇인가?
2015년 12월 Quora 글 https://www.quora.com/What-is-the-vanishing-gradient-problem 의 번역 글쓴이 Nikhil Garg - Quora 엔지니어링 매니저 Vanishing Gradient Problem(기울기값이 사라지는 문제)는 인공신경..
ydseo.tistory.com
참고자료 2 : https://blog.naver.com/PostView.nhn?blogId=laonple&logNo=220808903260
[Part Ⅵ. CNN 핵심 요소 기술] 1. Batch Normalization [1] - 라온피플 머신러닝 아카데미 -
Part I. Machine Learning Part V. Best CNN Architecture Part VII. Semantic ...
blog.naver.com
참고자료 3 : https://sacko.tistory.com/44
문과생도 이해하는 딥러닝 (10) - 배치 정규화
2017/09/27 - 문과생도 이해하는 딥러닝 (1) - 퍼셉트론 Perceptron 2017/10/18 - 문과생도 이해하는 딥러닝 (2) - 신경망 Neural Network 2017/10/25 - 문과생도 이해하는 딥러닝 (3) - 오차 역전파, 경사하강법..
sacko.tistory.com
참고자료 3 : https://light-tree.tistory.com/139
딥러닝 용어정리, Batch Normalization, 배치 정규화 설명
제가 공부한 내용을 정리하는 글입니다. 작성의 편의를 위해 아래는 반말로 작성하였습니다. 잘못된 내용이 있다면 지적 부탁드립니다. 감사합니다. Batch Normalization 배치 정규화의 목적 Batch norma
light-tree.tistory.com
참고자료 4 : https://light-tree.tistory.com/132
딥러닝 용어 정리, Normalization(정규화) 설명
제가 공부한 내용을 정리한 글입니다. 제가 나중에 다시 볼려고 작성한 글이다보니 편의상 반말로 작성했습니다. 잘못된 내용이 있다면 지적 부탁드립니다. 감사합니다. Normalization Data Normalizatio
light-tree.tistory.com
참고자료 5 : https://wegonnamakeit.tistory.com/47
[PyTorch로 시작하는 딥러닝 기초] 09-4 Batch-Normalization
edwith의 [부스트코스] 파이토치로 시작하는 딥러닝 기초 강의를 정리한 내용입니다. [LECTURE] Lab-09-4 Batch Normalization : edwith 학습목표 Batch Normalization 에 대해 알..
wegonnamakeit.tistory.com
참고자료 6 : https://hcnoh.github.io/2018-11-27-batch-normalization
[Deep Learning] Batch Normalization 개념 정리
이번 포스팅은 다음의 논문을 스터디하여 정리하였다: 링크1
hcnoh.github.io
참고자료 7 : https://m.blog.naver.com/laonple/220808903260
[Part Ⅵ. CNN 핵심 요소 기술] 1. Batch Normalization [1] - 라온피플 머신러닝 아카데미 -
Part I. Machine Learning Part V. Best CNN Architecture Part VII. Semantic ...
blog.naver.com
참고자료 8 : https://nittaku.tistory.com/267
8. activation function - saturation현상 / zigzag현상 / ReLU의 등장
파이썬 코드로 짠 M.L.N.N.의 코드를 하나하나 살펴보자. 위에는 Multi-Layer Neural Network(fully-connected N.N.)의 prototype이다. 여기서 하나하나의 요소를 개선해서 성능을 높일 수 있다. activation funct..
nittaku.tistory.com
참고자료 9 : https://wwiiiii.tistory.com/entry/Batch-Normalization
Batch Normalization
Batch Normalization 이 글은 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift을 읽고 정리한 것이다. 네트워크 학습에 많이 쓰이는 SGD의 경우 각 파라미터의 기..
wwiiiii.tistory.com
Batch Normalization 설명 및 구현
NIPS (Neural Information Processing Systems) 는 머신러닝 관련 학회에서 가장 권위있는 학회들 중 하나이다. 이 학회에서는 매년 컨퍼런스를 개최하고, 작년 12월에도 NIPS 2015라는 이름으로 러시아에서 컨��
shuuki4.wordpress.com
참고자료 11 : https://nittaku.tistory.com/271
11. Optimization - local optima / plateau / zigzag현상의 등장
지난시간까지는 weight 초기화하는 방법에 대해 배웠다. activation func에 따라 다른 weight초기화 방법을 썼었다. 그렇게 하면 Layer를 더 쌓더라도 activation value(output)의 평균과 표준편차가 일정하게 유
nittaku.tistory.com
'AI Research Topic > Deep Learning' 카테고리의 다른 글
| [Deep Learning] MediaPipe (0) | 2020.06.03 |
|---|---|
| [Deep Learning] 딥러닝에서 사용되는 다양한 Convolution 기법들 (4) | 2020.05.18 |
| [Deep Learning] 커널의 의미 (0) | 2019.10.05 |
| [Deep Learning] CNN(Convolutional Neural Network) (1) | 2018.11.01 |
| [Deep Learning] 손글씨 인식 (MNIST) (1) | 2017.08.25 |