
기존 2차원 컨볼루션은 세가지 문제점이 존재한다.
- Expensive Cost
- Dead Channels
- Low Correlation between channels
또한, 영상 내의 객체에 대한 정확한 판단을 위해서는 Contextual Information 이 중요하다. 가령, 객체 주변의 배경은 어떠한 환경인지, 객체 주변의 다른 객체들은 어떤 종류인지 등. Object Detection 이나 Object Segmentation 에서는 충분한 Contextual Information을 확보하기 위해 상대적으로 넓은 Receptive Field 를 고려할 필요가 있다.
일반적으로 CNN에서 Receptive Field 를 확장하기 위해서는 커널 크기를 확장한다던지, 더 많은 컨볼루션 레이어를 쌓는 방법을 생각해 볼 수 있다. 하지만 두 방법 모두 연산량을 크게 증가 시키기 때문에 부적절한 방법이 될 수 있다.
따라서 딥러닝에서는 연산량을 경량화 시키면서, 정보 손실이 일어나지 않게 끔 유의미한 정보만을 추출하기 위해 다양한 Convolution 기법들이 등장하였다! 스압주의
1. Convolution
2. Dilated Convolutions (atrous Deconvolution)
3. Transposed Convolution (Deconvolution or fractionally strided convolution)
4. Separable Convolution
5. Depthwise Convolution
6. Depthwise Separable Convolution
7. Pointwise Convolution
8. Grouped Convolution
9. Deformable Convolution
1. Convolution

가장 기본적인 형태의 컨볼루션 이다. 다양한 컨볼루션 기법들을 소개하기에 앞서, 가장 기본적인 내용은 다음과 같다.
- Kernel Size : 커널 사이즈는 컨볼루션의 View 를 결정한다. 보통 2차원에서 3x3 의 pixel 로 사용한다.
- Stride : 스트라이드는 이미지를 스캔할 때 커널의 스텝 사이즈를 결정하게 된다. 기본 값은 1이지만, 보통 Max Pooling 과 비슷하게 이미지를 다운 샘플링 하기 위해 스트라이드 값을 2로 사용 할 수 있다.
- Padding : 패딩은 샘플 테두리를 어떻게 조절할지를 결정한다. 패딩된 컨볼루션은 입력과 동일한 출력 차원을 유지하지만, 패딩되지 않은 컨볼루션은 커널 사이즈가 1보다 큰 경우 픽셀이 일부 잘려나가는 현상이 생겨버린다.
- Input & Output Channels : 컨볼루션 레이어는 입력 채널의 특정 수(I)를 받아 출력 채널의 특정수(O)로 계산한다. 이런 레이어에서 필요한 파라미터의 수는 I*O*K로 계산할 수 있으며, K는 커널의 수이다.
2. Dilated Convolutions (atrous convolution)
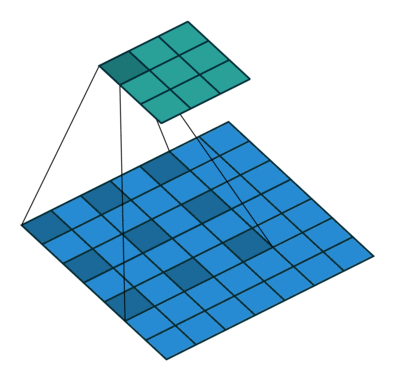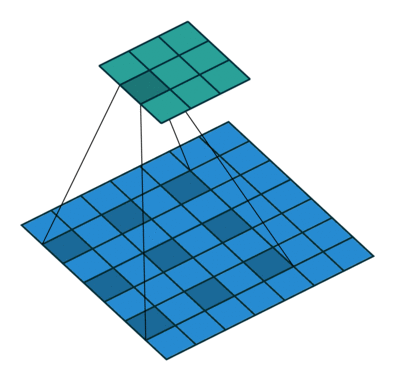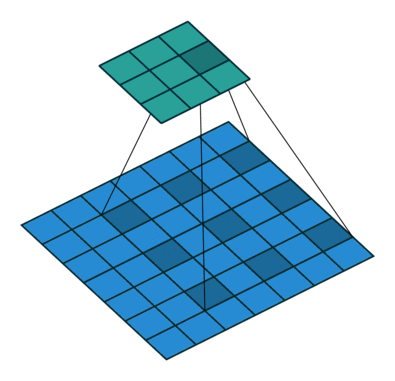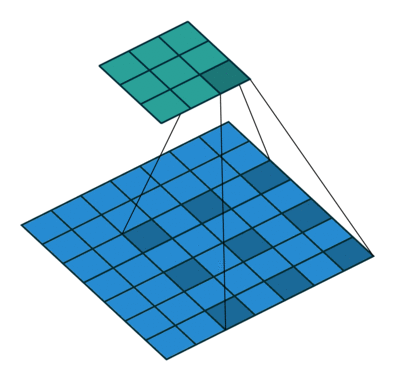
Dliated Convolution은 간단히 말하자면, 기존 컨볼루션 필터가 수용하는 픽셀 사이에 간격을 둔 형태이다. 입력 픽셀 수는 동일하지만, 더 넓은 범위에 대한 입력을 수용할 수 있게 된다.
즉, 컨볼루션 레이어에 또 다른 파라미터인 dilation rate 를 도입했다. dilation rate는 커널 사이의 간격을 정의한다. dilation rate 가 2인 3x3 커널은 9개의 파라미터를 사용하면서, 5x5 커널과 동일한 view 를 가지게 된다.
Dilated convolution 은 특히 real-time segmentation 분야에서 주로 사용된다. 넓은 view 가 필요하고, 여러 컨볼루션이나 큰 커널을 사용할 여유가 없을 때 사용한다. 즉, 적은 계산 비용으로 Receptive Field 를 늘리는 방법이라고 할 수 있다. 이 Dilated convolution 은 필터 내부에 zero padding 을 추가해서 강제로 Receptive Field 를 늘리게 되는데, 위 그림에서 진한 파란색 부분만 weight 가 있고 나머지 부분은 0으로 채워지게 된다. 이 Receptive Field 는 필터가 한번 보는 영역으로 사진의 Feature 를 파악하고, 추출하기 위해서는 넓은 Receptive Field 를 사용하는 것이 좋다. dimension 손실이 적고, 대부분의 weight 가 0 이기 때문에 연산의 효율이 좋다. 공간적 특징을 유지하는 Segmentation 에서 주로 사용되는 이유이다.

위 그림을 참고해서 보면, Segmentation 문제에서 Dilated Convolution 을 통해 이득을 보는 경우를 볼 수 있다.
단순히 Pooling - Convolution 후 Upsampling 하는 것과 Dilated Convolution(Atrous convolution)을 하는 것의 차이를 볼 수 있는데, 전자의 경우에서는 공간적 정보의 손실이 있는 것을 upsampling 하면 해상도가 떨어지게 된다. 하지만 dilated convolution 의 그림을 보면, Receptive field 를 크게 가져가면서 convolution 을 하면 정보의 손실을 최대화 하면서 해상도는 큰 output 을 얻을 수 있다.
또한 Segmenation 뿐만 아니라 Object Detection 분야에서도 이득을 볼 수 있다. 이와 같이 Contextual Information이 중요한 분야에 적용하기 유리하다. 또한 간격을 조절하여 다양한 Scale에 대한 대응이 가능하다.
3. Transposed Convolution
(Deconvolution or fractionally strided convolution)
실제로 Transposed Convolution 보다는 Deconvolution 이라는 이름으로 많이 쓰이는 듯 하다. 하지만 실제로는 Deconvolution이 아니다. 왜냐하면 실제의 Deconvolution 은 convolution의 과정을 되돌리는 작업이다. 일단 실제 진짜의 Deconvolution 과정은 아래 그림과 같은데, 일반 2D Convolution 그림에서 보면 5x5 의 입력 이미지가 있을 때 Stride 는 2, Padding은 없고, Kernel 은 3x3 이 적용되었다. 이 결과 2x2 이미지가 생성된다. 이 과정을 되돌리는 실제 Deconvolution 작업은 역 수학 연산을 위해 입력값의 각 픽셀로부터 9개의 값을 뽑아야 하며, 그 후에 stride 가 2인 출력 이미지를 지나가게 된다. 하지만 이 방법이 실제로 사용되는 경우는 거의 없다고 본다.

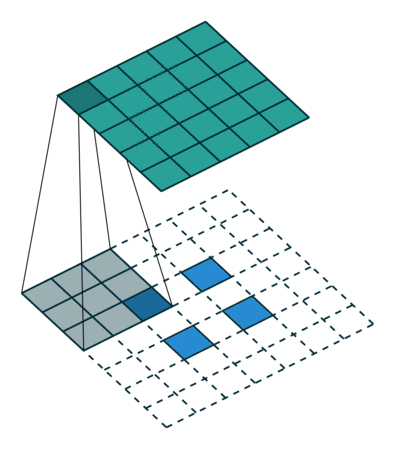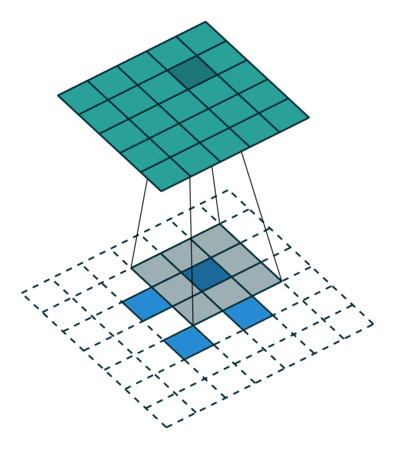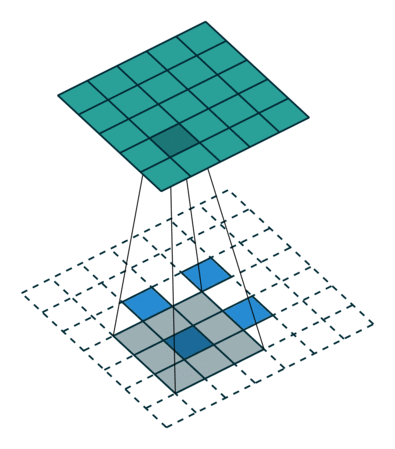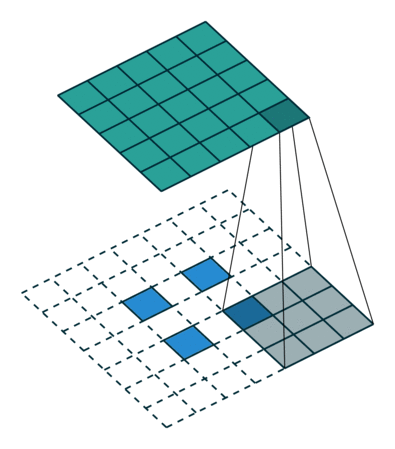
그렇다면 Transposed Convolution은 왜 Deconvolution 이라는 이름이 붙었을까 라는 의문이 들 수 있다. Transposed Convolution은 deconvolutional layer와 동일한 공간 해상도를 생성한다는 점에서 유사하다. 하지만 실제 수행되는 수학 연산은 당연히 다르다 ^^, Transposed convolutional layer 는 정기적인 convolution 을 수행하며 공간의 변환을 수행한다.
일반적인 2차원 컨볼루션의 실제 연산 과정은 다음과 같다.
(아래 그림은 잘못된 부분이 발견 되어 2022년 2월 9일에 아래와 같이 수정 되었습니다.)

Transpose convolution 연산 과정은 다음과 같이, 컨볼루션 과정에서 커널에 대응되는 Sparse Matrix 가 Transpose 된 matrix 와 4 x 1 matrix 의 연산을 통해 16 x 1 matrix를 구해낸다. 즉, Transpose convolution 은 압축된 정보를 또 다른 과정을 통해 Up-sampling 하여 복원한다고 보면 될 것 같다.
(아래 그림은 잘못된 부분이 발견 되어 2022년 2월 9일에 아래와 같이 수정 되었습니다.)

이러한 Transposed Convolution 이 사용되는 모델의 종류는 다양하다. 예를 들면 CNN을 사용한 Encoder-Decoder 구조의 Autoencoder가 있다. Encoder에서 Pooling 등을 통해 이미지를 축소시키면서 데이터를 압축했다면, 그 데이터를 다시 원래의 이미지로 복원하기 위해 이미지를 크게 만들어야(Up-sampling)하는데, 이럴 때 사용되는 방법이다.
그리고 단순히 이미지의 해상도를 높이는 Super resolution 에서도 많이 쓰인다. 이미지의 크기를 복원하는 방법은 Transposed convolution 만 존재하는게 아니다. "보간" 이라는 방법이 존재하는데, Bilinear Upsampling 기법을 많이 사용하기도 한다.
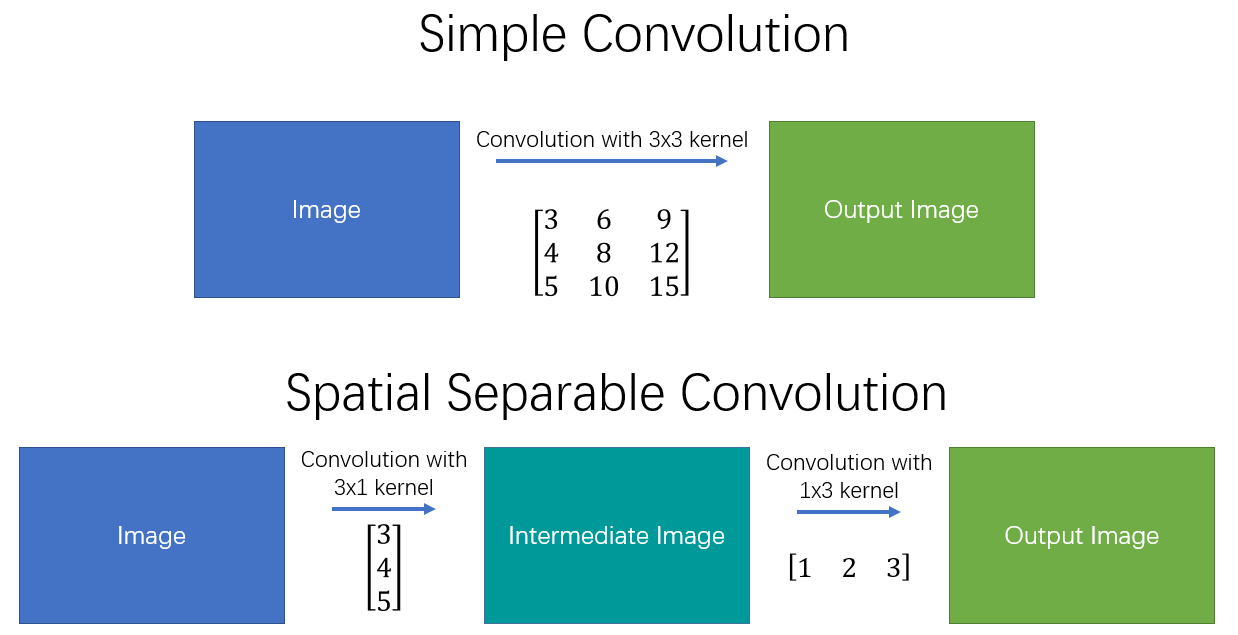
4. Separable Convolution
Separable Convolution 에서는 커널 작업을 여러 단계로 나눌 수 있다. 컨볼루션을 y = conv(x, k)로 표현할 때, x는 입력 이미지, y 는 출력 이미지, k는 커널이다. 그리고 k=k1.dot(k2) 로 계산된다고 가정해 볼 때, 이것은 K와 2D Convolution 을 수행하는 대신 k1 과 k2로 1D Convolution 하는 것과 동일한 결과를 가져오기 때문에 Separable Convolution 이라고 할 수 있다.
즉 Separable Convolution은 단순히 커널을 두 개의 작은 커널로 나눈 뒤에 원래 커널로 작업한 결과물과 동일한 효과(원래는 9번의 곱셈)를 얻기 위하여 각각 3번의 곱셈으로 두 번의 컨볼루션을 수행하게 된다. 곱셈 연산이 적을 수록 계산 복잡성이 줄어들고, 네트워크를 더 빠르게 실행 할 수 있다. 가장 대표적인 Convolution 연산으로는 이미지 프로세싱에서 Sobel Mask 가 있다. 하지만 이러한 방식의 문제점은 모든 커널을 두 개의 작은 커널로 분리 할 수 없다는 문제를 가진다.
5. Depthwise Convolution
일반적인 컨볼루션 필터는 입력 영상의 모든 채널에 영향을 받게 되므로, 완벽히 특정 채널만의 Spatial Feature 를 추출하는 것이 불가능하다. 즉, 다른 채널의 정보가 관여하는 것이 불가피 하기 때문이다. 하지만 Depthwise Convolution은 각 단일 채널에 대해서만 수행되는 필터들을 사용하였다. MobileNet 구조에서는 Depthwise Convolution 을 택하여 연산량을 기하 급수적으로 줄여 실시간에서 동작가능하도록 하였다. 어떻게 연산량을 기하 급수적으로 줄일 수 있었는지 살펴보자.

위 그림과 같이, 8x8x3 matrix 를 Depthwise Convolution 하기 위해서 3x3x3 커널을 사용한 예시이다. 이 때 이 커널은 각 채널 별로 분리 되어 3x3의 2차원 커널을 8x8 크기의 각 분리된 matrix 에 붙어 각 Convolution 을 진행하고 다시 합쳐지는 구조로 되어있다. 즉, 채널 방향의 Convolution 은 진행하지 않고, 공간 방향의 Convolution 만을 진행했다고 보면 된다.
즉, 각 커널들은 하나의 채널에 대해서만 파라미터를 가진다. 그래서 입력 및 출력 채널의 수가 동일한 것이며 각 채널 고유의 Spatial 정보만을 사용하여 필터를 학습하게 된다. 결과적으로 입력 채널 수 만큼 그룹을 나눈 Grouped Convolution과 같아진다. Grouped Convolution 은 아래에서 설명한다.
6. Depthwise Separable Convolution
위의 Depthwise Convolution 과는 달리, 이 Depthwise Separable Convolution은 채널의 출력 값이 하나로 합쳐지는 특징을 가지고 있다. 이는 Spatial Feature 와 Channel-wise Feature 를 모두 고려하여 네트워크를 경량화 하는 방법이다. 기존의 Convolution 연산과 거의 유사하게 동작하지만, 파라미터 수와 연산량은 훨씬 적다.

기존 Depthwise Convolution 을 진행한 결과물에 각 채널을 1개의 채널로 압축 할 수 있는 추가적인 Convolution을 진행하여 결과물이 굉장히 간략하게 나오도록 하였다.
7. Pointwise Convolution
앞서 소개했던 Depthwise Convolution, Depthwise Separable Convolution 들은 공간 방향의 컨볼루션을 진행한 뒤, 채널방향의 컨볼루션을 진행했는가/진행하지 않았는가로 나뉘었다. 하지만 이와는 달리 Pointwise Convolution 은 공간방향의 컨볼루션은 진행하지 않고, 채널 방향의 컨볼루션을 진행하는 것이다. 즉, Channel Reduction 시에 주로 사용된다.
이는 커널 크기가 1x1 로 고정된 컨볼루션 레이어이다. 입력 영상에 대한 Spatial Feature 는 추출하지 않은 상태로, 각 채널들에 대한 연산만을 수행하게 된다.
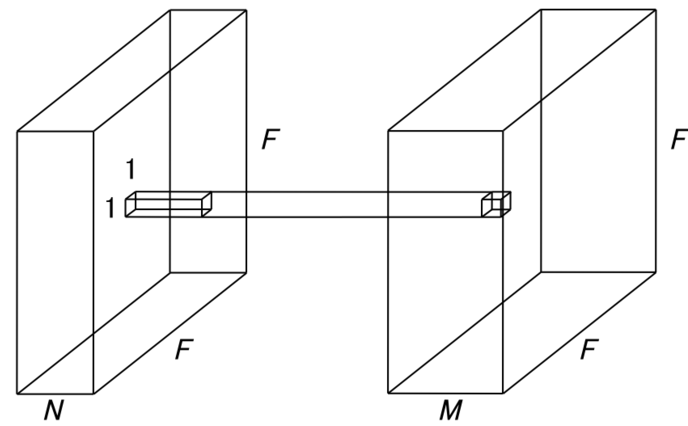
즉, 1x1xC 크기의 커널을 사용하여 입력의 특징을 1개의 채널로 압축 시켜버리는 효과를 가지고 있다. 결국 하나의 필터는 채널 별로 Coefficient 를 가지는 Linear Combination을 표현한다. 이는 채널 단위의 Linear Combination을 통한 채널 수의 변화가 가능하다는 것을 뜻한다. 이는 다채널 입력 영상을 더 적은 채널의 영상으로의 Embedding 하는 것으로 이해 할 수 있다. 출력 채널 수를 줄임으로써 다음 레이어의 계산량과 파라미터를 줄일 수 있는 것이다. 채널에 대한 Linear Combination을 수행할 시 불필요한 채널들이 낮은 Coefficient를 가지며 연산 결과에서 희석 될 수 있다.
이럴 경우 연산 속도가 대폭 향상된다는 장점을 가지지만, 데이터가 압축 되면서 소실되어버리는 문제도 발생한다. 그래서 속도가 중요한지, 정보손실이 중요한지의 trade-off 가 존재한다.
이러한 Pointwise Convolution 기법은 Inception / Xception / SqueezeNet / MobileNet 에 적용되어 경량화와 성능 개선이 가능함이 실험적으로 증명 되었다.
8. Grouped Convolution
Grouped Convolution 은 입력 값의 채널들을 여러 개의 그룹으로 나누어 독립적으로 Convolution 연산을 수행하는 방식이다. 이는 아이디어와 구현 방법이 간단하며, 병렬 처리에 유리하다는 장점이 있다.
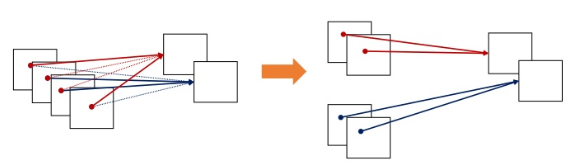
Grouped Convolution 기법은 기존 2D Convolution 보다 낮은 파라미터 수와 연산량을 갖게 되며, 각 그룹에 높은 Correlation을 가지는 채널이 학습 될 수 있다는 장점이 있다.

결과적으로 각 그룹마다 독립적인 필터의 학습을 기대할 수 있다. 또한 그룹 수를 조정해 독립적인 필터 그룹을 조정할 수도 있다. 그룹의 수를 늘리면 파라미터의 수는 줄면서도, 성능 향상이 일어나는 경우가 있다. 하지만 그룹의 수는 Hyper Parameter 라는 단점이 있기 때문에 너무 많은 그룹으로 분할하는 것은 오히려 성능이 더 하락 될 수 있다.

파라미터 수와 연산량 측면에서의 자세한 설명은 다음과 같다.
기존 2D Convolution 의 파라미터 수는 필터의 크기가 K이고 입력의 채널이 C라고 할 때, 하나의 필터가 가지는 크기는 K²C 이고, 하나의 필터에서 나오는 출력은 하나의 채널에 해당되니까 출력을 M개의 채널로 만들어주려면 이러한 필터의 개수가 총 M개 존재해야 하므로 총 파라미터의 수는 K²CM 이 되며, 연산량은 하나의 필터당 총 H x W 번 연산을 해야 출력 채널이 생성되기 때문에 K²CMHW 가 된다.
그렇다면 Grouped Convolution 의 파라미터 수와 연산량은 어떠한지 살펴보자. Grouped Convolution은 입력 채널들을 g개의 그룹으로 나누어 연산을 수행한다. 그렇다면 각 그룹 당 채널 수는 C/g 개가 된다. 그리고 출력의 채널도 각 그룹에서 M/g 개씩 생성된다고 가정하면 한 그룹 당 필터의 파라미터 수는 K²(C/g)(M/g)가 된다. 따라서 총 g개의 그룹이 있으니 (K²CM)/g 가 된다. 연산량은 K²CMHW/g 가 된다.
9. Deformable Convolution
2017년 3월에 공개된 Deformable Convolutional Networks 라는 논문에서 나온 개념이다.
말 그대로 변형이 가능한 CNN이라는 개념인데, 이 논문들의 저자는 기존 CNN(Convolutional Neural Network)에서 사용하는 여러 연산(conv / pooling / roi pooling 등)이 기하학적으로 일정한 패턴을 가정하고 있기 때문에 복잡한 transformation에 유연하게 대처하기 어렵다는 한계가 있음을 지적하였다. 일례로 CNN에서 사용하는 Receptive Field 의 크기가 항상 같고, Object Detection 에서 사용하는 Feature 를 얻기 위해 사람의 작업이 필요한 점을 언급하고 있다. 기존 논문들은 weight 를 구하는 방법에 초점을 맞췄다면, 이 논문은 어떤 데이터 x 를 뽑을 것인지에 초점을 맞췄다는 것이 참신하다는 평가를 받았다고 한다.

Deformable Convolution 은 위 그림에서 convolution 에서 사용하는 sampling grid 에 2D offset 을 더하는 것이다. 그림 (a)에서 초록색 점이 일반적인 convolution 의 sampling grid 라면 (b) (c) (d) 처럼 다양한 패턴으로 변형시켜 사용할 수 있다. sampling grid 의 변형은 스케일, 종횡비, 회전 방식 등이 있다.

위 그림은 3 x 3 deformable convolution 의 예시이다. 위 그림과 같이 deformable convolution 개념에는 기존 conv later 이외에도 초록색 그림의 conv 가 더 존재한다. 이 layer 는 각 입력의 2D offset 을 학습하기 위한 것이다. 이 offset 은 integer 값이 아니라 fractional number 이기 때문에 소수 값이 가능하며, 실제 계산은 linear interpolation 으로 이루어진다. (2차원 이기 떄문에 bilinear interpolation) 즉, filter size 를 학습하여 object 크기에 맞게 변화하도록 한 것이다.
학습(Traning) 과정에서 output feature 를 만드는 convolution kernel 과 offset 을 정하는 convolution kernel 을 동시에 학습 할 수 있다. 아래 그림은 convolution filter 의 sampling 위치를 보여주는 예시이다. 붉은색 점들은 deformable convolution filter 에서 학습한 offset 을 반영한 sampling location 이며, 초록색 사각형은 filter 의 output 위치이다. 일정하게 sampling pattern 이 고정되어있지 않고, 큰 object 에 대해서는 receptive field 가 더 커진 것을 확인 할 수 있다.

참고자료 1 : https://zzsza.github.io/data/2018/02/23/introduction-convolution/
딥러닝에서 사용되는 여러 유형의 Convolution 소개
An Introduction to different Types of Convolutions in Deep Learning을 번역한 글입니다. 개인 공부를 위해 번역해봤으며 이상한 부분은 언제든 알려주세요 :)
zzsza.github.io
참고자료 2 : https://3months.tistory.com/213
Segmentation과 Dilated Convolution
Segmentation classification이 사진에서 어떠한 물체가 '존재하는지' 를 판단하는 것이라면 Segmentation은 이미지에서 픽셀단위로 해당 픽셀이 어떤 Class에 속하는지를 예측하는 태스크로 볼 수 있다. Input
3months.tistory.com
참고자료 3 :
[Part Ⅶ. Semantic Segmentation] 6. DeepLab [1] - 라온피플 머신러닝 아카데미 -
라온피플 머신러닝 아카데미 [Part Ⅶ. Semantic Segmentation]6. DeepLab [1] Semantic Segmentati...
blog.naver.com
참고자료 4 :
depthwise convolution / pointwise convolution
사람의 몸을 detecting하는 Open Pose 라는 논문을 제작하면서, VGG-19 network의 연산량이 매우 많아...
blog.naver.com
참고자료 5 : https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
A Basic Introduction to Separable Convolutions
Explaining spatial separable convolutions, depthwise separable convolutions, and the use of 1x1 kernels in a simple manner.
towardsdatascience.com
참고자료 6 : https://hichoe95.tistory.com/48
Different types of Convolutions (Grouped convolution, depthwise convolution, pointwise convolution, depthwise separable convolut
오늘 정리해 볼 것들은 앞으로 정리할 논문들을 위해 미리 알아두면 좋은 convolution입니다. 각 convolution들에 대한 간단한 특징과 param수, 연산량 등에대해서 알아봅시다 ㅎㅎ 들어가기에 앞서 몇��
hichoe95.tistory.com
참고자료 7 : https://www.slideshare.net/ssuser6135a1/ss-106656779
여러 컨볼루션 레이어 테크닉과 경량화 기법들
[Deprecated] 아래의 URL의 슬라이드로 업데이트 및 대체되었습니다! https://www.slideshare.net/ssuser6135a1/designing-more-efficient-convolution-neural-network
www.slideshare.net
참고자료 8 : https://eehoeskrap.tistory.com/406
[Object Detection] Deformable Convolutional Networks
Paper : https://arxiv.org/abs/1703.06211 Deformable Convolutional Networks Convolutional neural networks (CNNs) are inherently limited to model geometric transformations due to the fixed geometric s..
eehoeskrap.tistory.com
'AI Research Topic > Deep Learning' 카테고리의 다른 글
| [Deep Learning] Activation Function : Swish vs Mish (1) | 2020.06.07 |
|---|---|
| [Deep Learning] MediaPipe (0) | 2020.06.03 |
| [Deep Learning] Batch Normalization (배치 정규화) (9) | 2020.05.16 |
| [Deep Learning] 커널의 의미 (0) | 2019.10.05 |
| [Deep Learning] CNN(Convolutional Neural Network) (1) | 2018.11.01 |