[Pose Estimation] Exemplar Fine-Tuning for 3D Human Pose Fitting Towards In-the-Wild 3D Human Pose Estimation
연구를 하다보면 좋아하는 저자가 한 두명씩 생기곤 하는데, 그 중 하나가 Facebook AI Research 에서 일하고 계신, OpenPose 저자인 Hanbyul Joo 님이다. 2D, 3D Human Pose Estimation 부터 Hand Keypoint Detection, 3D Deformation Model, Tracking 분야까지 다양한 연구를 하고 계신 분이다. 많은 연구들 중에서 최근에 나온 연구는 아래 논문이다.
Joo, Hanbyul, Natalia Neverova, and Andrea Vedaldi, "Exemplar Fine-Tuning for 3D Human Pose Fitting Towards In-the-Wild 3D Human Pose Estimation", arXiv preprint arXiv:2004.03686 (2020).
https://arxiv.org/abs/2004.03686
Exemplar Fine-Tuning for 3D Human Pose Fitting Towards In-the-Wild 3D Human Pose Estimation
We propose a method for building large collections of human poses with full 3D annotations captured `in the wild', for which specialized capture equipment cannot be used. We start with a dataset with 2D keypoint annotations such as COCO and MPII and genera
arxiv.org

이 논문은 'wild' 환경의 3차원 포즈 주석을 이용하여 3차원 파라메트릭 모델(3D parametric model)을 2차원 영상 및 관절에 fitting 하는 방법을 제안하였다. 이는 COCO 및 MPII 와 같은 2차원 키포인트 데이터 세트로 부터 3차원 포즈 데이터를 생성한다. 이는 3차원 파라메트릭 모델 을 2차원 키포인트에 fitting 하는 EFT(Exemplar Fine-tuning) 알고리즘을 통해 수행된다.
본 논문에 의하면 EFT는 2차원 포즈 값만 사용하여 3차원 포즈를 생성할 때 발생하는 depth reconstruction ambiguity 를 해결하기 위하여 데이터 기반 포즈(data-driven pose)를 활용 하여 accuracy 를 보장하였다. 이를 통해 wild 환경에서 그럴듯하고 정확한 3차원 포즈 주석 데이터들을 생성하게 된다. 그 다음 이 데이터를 사용하여 3차원 포즈 회귀 신경망(3D pose regression network)를 학습하여 wild 에서 수집된 데이터를 포함하여 표준 벤치 마크에서 최신 결과를 얻게 된다. 이 신경망은 extremely challenging internet video 에서 최적의 포즈 추정 품질을 달성한다고 한다.
1. Introduction
인간의 행동들을 완전하게 이해하려면 인간의 포즈를 3차원으로 재구성(Reconstruction)하는 일이 필요하다. 최근 2차원 키포인트 주석이 달린 데이터 세트들을 신경망으로 학습시킴으로써 3차원으로 포즈를 추정하는 분야가 크게 발전하였다. 이러한 "2D Human Pose Estimation" 분야는 사람의 움직임을 완전히 이해하는데 충분하지 않다는 단점을 가진다. 즉, 실제 인간의 포즈는 카메라 시점에 큰 영향을 받으며, 깊이(depth) 방향에 따라 발생하는 모션들을 충분히 이해 할 수 없다.
단일 이미지에서 3차원으로 사람의 포즈를 추정하는 방법도 3차원 키포인트 데이터 세트를 이용하여 "3D Human Pose Estimation" 분야가 크게 발전을 하였지만, 이러한 3차원 키포인트 데이터 세트들은 대부분 실내이거나 실험실 내부에서 촬영된 것이므로 굉장히 제한적인 조건에서 촬영이 된 데이터들이다. 따라서 저자는 wild 환경에서 촬영된 2차원 키포인트를 3차원으로 확장시킴으로써 3차원 키포인트 데이터 세트들을 생성하여 3차원 포즈 추정을 수행하였다.
따라서 이 논문에서는 이러한 데이터 세트들을 어떻게 구성할 것인가에 대한 문제를 고려하였다. wild 환경에서 촬영된 2차원 키포인트 주석들은 이미 존재한다. 이러한 주석을 3차원으로 확장하면 wild 환경에서의 3차원 포즈 추정 주석 데이터 세트가 생기는 것이다. 3차원 포즈 추정이라는 분야 자체가 expert human annotator 가 있어도, 추정이 어려운 경우가 많기도 하고, 3차원 포즈 추정 데이터를 만드는 일이 여간 쉽지가 않은 문제이다. 그래서 본 논문에서는 기존의 2차원 키포인트의 주석을 3차원으로 끌어 올리는(lifting) 알고리즘을 개발하였다. 2차원 키포인트 정보가 이미 알려져 있더라도 이러한 2차원 정보는 depth ambiguity 가 존재하기 때문에 이 알고리즘은 두 가지 목표를 가진다.
1. depth ambiguity 에도 불구하고 자연스럽고 사실적인 느낌의 3차원 포즈를 예측하는 것
2. 3차원 포즈는 2차원 키포인트 주석과 일치하며, 정확하게 투영(re-projection) 되어야 한다는 것
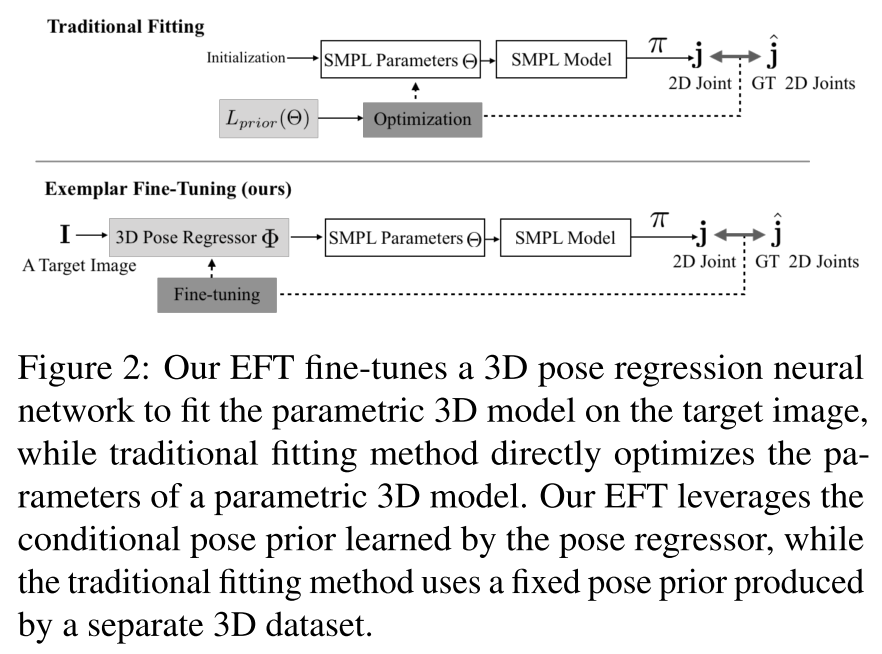
본 논문에서는 기존에 존재하는 2차원 키포인트 주석과 인간의 3차원 파라메트릭 모델을 정확하게 맞추기 위하여 EFT 알고리즘을 개발하였다. 이는 2차원 입력을 3차원 모델의 매개변수에 매핑하기 위해 학습된 3차원 포즈 회귀 분석기를 사용하여 각 테스트 예제에서 개별적으로 회귀자(regressor) 를 fine-tuning 한다. 이 방법은 최적화를 통해 파라 메트릭 모델을 2차원 주석에 맞추는 기존의 방법들과는 다르다. 실제로 최적화 알고리즘은 3차원 모델의 매개 변수를 직접 업데이트하여 2차원 데이터에 더 잘 맞도록 투영 오류(re-projection error)를 최소화 한다. EFT는 이러한 투영 오류를 최소화 하지만, 매개 변수를 직접 변경하는 대신, 3차원 모델의 매개 변수를 생성하는 회귀 신경망을 fine tuning 하여 3차원 포즈를 추정하게 된다.
또한, EFT 는 보이지 않는 데이터(unseen)를 더 잘 맞추기 위해, 신경망을 조정하는 것이 아니라, 각 이미 정해진? 알려진! input example 에 3차원 모델을 최대한 적합하게 맞추는 것이 목표이기 때문에 일반적으로 회귀 방식으로 3차원 포즈 추정을 위해 학습되는 것과는 다르다. 실제로 EFT 는 3차원 모델의 파라미터를 single example 에 맞추기 전에 사전 훈련된 3차원 포즈 추정 신경망 모델을 사용한다. 이렇게 하는 이유는 회귀 신경망이 3차원 GT(Ground Truth) supervision 와 함께 많은 포즈 데이터 세트들을 사용하여 먼저 훈련되고, 그 과정에서 파라 메트릭 모델 자체가 캡쳐한 것보다 더 나은 포즈를 배울 수 있다는 것이다. 중요한 장점은, 정의 상 2차원 입력을 관찰하여 사전 조건(conditional prior)들을 학습한다는 것이다. 따라서 이 사전 조건은 이전의 접근법에서 사용된 일반적인 포즈들의 분포 보다 3차원 포즈를 예측하는데 더 유용한 조건이어야한다. 이 논문은 수 많은 실험을 통해 EFT 가 기존의 방법들 보다 초기화(initialization)에 덜 민감하고, 누락된 2차원 키포인트에 대해 더 강건하며, 더 적절한 결과를 생성한다.
EFT 를 사용하여 wild 환경에서 촬영된 COCO 및 MPII 와 같은 표준 2차원 포즈 데이터 세트들을 augment 하여 2차원 데이터와 쌍으로 3차원 포즈 데이터 세트들을 생성한다. 이는 약 100K 개로 이루어져있다. 엄청 유용한 정보가 될 듯 하다. 본 논문에서는 이 데이터들을 사용하여 SOTA 를 달성하는 신경망을 선보인다. 또한 potentilally crop 되거나 heavily occlusion 된 경우들도 테스트를 수행하였다. 또한 3차원 데이터 세트들을 augmentation 하여 occlusion 을 simulation 하고, 포즈 회귀자(pose regressor)를 학습한다.
Our dataset will be made publicly available.
이러한 데이터 세트는 공개적으로 제공 될 것이다.
본 논문에서는 실내 데이터에서 촬영된 3차원 포즈 데이터와 wild 환경에서 촬영된 2차원 포즈 데이터들을 결합하고, 일부 방법은 3차원 키포인트를 직접 예측하기도 하고, 다른 일부는 3차원 인체 모델(body model)의 매개 변수를 예측하고, 다른 방법은 신체 관절에 대한 volumetric heatmap 을 사용하여 각기 다른 출력들을 가질 수 있다.
2. Preliminaries
2.1 Parametric 3D Models of Humans
파라메트릭 모델은 좌우 대칭 및 몸체의 비율과 같은 중요한 속성을 나타내면서 적은 수의 매개 변수를 통해 다양한 사람의 형상과 포즈들을 나타 낼 수 있다. 이 논문에서 우리는 SMPL 모델을 인간이 포함된 이미지에 맞추는 문제를 고려한다.
SMPL 의 파라미터 Θ = (θ,β) 는 다음과 같이 구성된다.
부모 파라미터에 대한 24개의 바디 조인트의 회전을 제어하는 포즈 파라미터 θ ∈ R^(24x3) 와 PCA 를 이용하여 학습된 10가지 주요 변형 방향(direction)을 통해 형상을 제어하는 파라미터 β ∈ R^10 로 구성된다.
SMPL 모델의 나머지 포즈에서 관절 위치는 β 에 의해 모양을 shape deformation 을 적용한 후 vertice 에 의해 회귀되며, final joint loacation 과 posed mesh vertice 는 골격 계층에 따라 계산된 변환을 통해 얻어진다. 3차원 바디 관절의 위치에 초점을 맞추면, SMPL 은 아래와 같이 나타내며, 여기서 J ∈ R^(24×3) 은 관절의 3차원 위치를 뜻한다.

2.2 Optimizing vs Regressing 3D Pose
사람의 이미지 I 가 주어지면 피사체의 포즈와 일치하는 SMPL 의 매개변수 Θ 를 찾는 것을 목표로 한다. 최적화 기반 접근법은 joint, silhouette, part label 과 같은 image 2D cue 들을 추출하고, 모델 매개 변수를 이에 맞게 최적화 한다. 특히 신체 관절의 2차원 위치 j ∈ R^(24×2) 가 주어지면 아래와 같은 식으로 매개변수를 구할 수 있다.
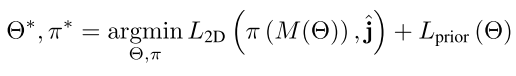
이 때, M() 함수는 식 1의 함수를 뜻하며, π 는 3차원 관절을 2차원 위치에 매핑하는 camera projection function 으로서 공동으로(jointly) 최적화 되며, L2D 는 이것들과 입력된 2차원 위치들간의 re-projection error 를 뜻한다.
depth ambiguity 로 인하여 손실함수 L 2D 를 최적화 하는 것은 포즈 파라미터 Θ 를 고유하게 복구하는데 불충분하다는 단점이 있다. 이러한 ambiguity 를 줄이기 위해 L prior 라는 것을 손실 함수에 추가하였다. SMPL 에서는 형상 및 포즈 매개 변수에 대한 우선순위가 제공된다.
SMPL과 같은 3차원 모델은 일반적으로 2차원 주석을 정확하게 맞출 수 있을 정도로 충분한 degrees of freedom 을 가지고 있다. (이는 SMPL 데이터는 어린 아동이나 옷을 많이 껴입은 사람에 적용이 힘들다) 그러나 최적화는 국부적인(local) 것에 불과하기 때문에, 최종적인 3차원 출력 결과는 the quality of the initialization 에 영향을 많이 받게 된다. 또한 re-projection loss 의 균형을 맞추기 어렵고, 너무 특징이 강한 이전(prior) 결과들은 2D evidence 를 무시한 "mean" 포즈가 나올 수 있으며, 너무 특징이 약한 이전 결과들은 신뢰 할 수 없거나 왜곡된 포즈들을 내뱉을 수 있다. 또한 local minima 는 여러 단계에서 최적화를 중단해야할 수 있으며, 먼저 몸통(torso) 부분을 먼저 rigid transform 으로 align 시킨 다음, 팔다리(limbs) 를 최적화 해야한다.

회귀 기반 접근 방식은 2차원 cue 인 I 에서 SMPL 매개변수 파라미터를 직접 예측하며, 이 cue 는 raw images, 2D joints , dense 2D points 가 될 수 있다. cue 에 3차원 SMPL 모델을 매핑하는 것은 대규모 데이터 세트를 통해 훈련된 신경망 Θ = Φ(I) 에 의해 구현되며, 흔히 3차원 실내 데이터 세트와 2차원 실외 데이터 세트를 결합하여 얻을 수 있다. 학습 시 손실 함수는 다음과 같이 정의된다.

이와 같은 손실 함수는 2D re-projection loss 인 L 2D 손실과 3D joint reconstruction loss 인 L j 와 SMPL parameter reconstruction loss L Θ 손실을 합친 것이다. 이 식에서 매개변수 ji 는 2차원 관절에 대한 GT 를 뜻하며, Ji 는 3차원 관절에 대한 GT 를 뜻하고, Θi 는 SMPL parameter 를 뜻한다. 여기서 i 는 i 번째 학습 샘플들에 대한 loss-balancing coeffients 를 뜻하고, 3차원 주석이 없는 샘플의 경우 0으로 설정 할 수 있다. camera projection function π 에 대한 매개변수는 신경망 Φ 의 추가적인 출력으로서 예측 할 수 있다.
대부분의 경우 학습 기반 접근법의 목표는 일반화가 잘되는 모델을 unseen data 에 맞게 학습시키는 것 이므로, 평가를 위한 학습과 테스트 데이터의 엄격한 분리가 필요하다. 그러나 이 논문의 경우 2차원 주석을 3차원으로 끌어올려서 두 세트가 일치하는 것을 목표로 하고있는데, 구체적으로 3차원 데이터와 2차원 데이터를 결합하여 포즈를 미리 학습하는데, 이 과정은 3차원 데이터 세트와 2차원 데이터 세트를 결합하여 회귀하는 것과 같다. 그러자 2차원 wild 데이터 세트에는 3차원 주석을 달고 싶은 샘플들이 포함된다. 결합된 데이터를 통해 신경망을 최적화함으로써, 2차원 주석이 달린 것을 포함하여 모든 샘플에 대한 3차원 포즈의 추정치를 얻는다. 그러나 이러한 3차원 포즈는 feed-forward neural network regressor 에 의해 생성되기 떄문에 2차원 주석에 반드시 정확한 방식으로 정렬 될 필요는 없다.
3. Exemplar Fine-Turning
3차원 인간 모델의 매개변수를 2차원 관절 위치에 맞추기 위해 Exemplar Fine-Turning 을 소개한다. 모델 파라미터를 직접 변경하는 기존의 최적화 기반 fitting 방식과는 달리, 3D pose regressor network 를 개별 테스트 샘플에 fine-turning 하여 fitting 하는 과정을 거친다. 이 논문의 목표는 strong 3D pose prior 를 구축하는 것이다. 다음 그림과 같이, 기존의 전통적인 방식은 3차원 파라메트릭 모델의 매개변수를 직접 최적화하며, 별도의 3차원 데이터 세트로 생성된 fixed pose prior 를 사용하지만, EFT 는 3차원 포즈 회귀 신경망을 fine-turning 하여 대상 이미지에 따라 3차원 파라메트릭 모델을 fitting 하는 방식이며, 포즈에 대한 회귀자가 이전에 배운 조건부 포즈를 활용하게 된다.
이러한 EFT 는 아래와 같은 손실 함수를 통해 신경망 모델 Φ 를 최적화 하게 된다.
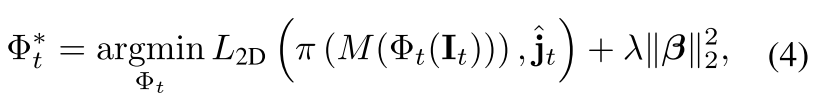
여기서 It는 현재 타겟 이미지를 뜻하며, 형상 파라미터를 제어하는 regularizer 이다. 식 4에서 EFT 에서 사용 가능한 cue 는 2차원 관절 위치 뿐만 아니라, 3차원 스켈레톤에 SMPL 모델을 fitting 할 때 DensePose, 2D face keypoints, 3D keypoints 등을 포함한 모든 2차원 3차원 키포인트에 적용 할 수 있다. SMPLify 와 같은 전통적인 최적화 기반 방법과 마찬가지로 EFT 는 각 표본에 대한 최적화 문제를 독립적으로 해결하지만, 전통적인 방식과 큰 차이점은 기존의 방식은 오로지 초기화 할 때만 신경망을 사용하지만, EFT 는 최적화 되는 동안 pose prior 가 유지된다는 것이다. EFT 에서 occlusion 이나 비정상적인 포즈로 인해 초기화를 할 수 없는 포즈에서도 3차원 포즈의 타당성을 유지하면서, re-projection error 를 최소화 하는 것을 볼 수 있었다고 한다.
Implementation Details
SOTA 의 SPIN 신경망을 사용하였으며, 각 샘플에 대해 EFT 는 신경망을 사전 훈련된 초기 상태로 다시 학습 시킨 다음 식 4 를 만족하게끔 최적화를 수행한다. 기본 Pytorch 파라미터와 10^-6 의 학습률로 Adam 을 사용하여 20회 반복하여 학습 시켰다. fine turning 을 위해 배치 정규화 및 드롭 아웃 레이어를 제거하였고, human annotator 가 엉덩이 포인트 및 발목 포인트에 주석을 달 때 종종 부정확한 경우가 있을 수 있으며, 신체의 왼쪽과 오른쪽을 혼란스럽게 할 수 있음을 발견하였고, 이러한 noise 들은 3차원 fitting 품질에 악영향을 줄 수 있다. 예를 들어 팔다리가 예상했던 것 보다 짧게 나타난 경우 predictor 는 3차원 공간에서 팔다리를 tilt 하여 compensate 할 수 있다. 따라서 식 4에서는 엉덩이와 발목을 무시하도록 수정되었으며, 대신 다리의 2차원 방향과 일치하도록 term 을 추가하였다고 한다.
4. Learning a robust 3D regressor
EFT 를 사용하여 2차원 주석을 3차원으로 lift 함으로써 wild 환경에서 완전한 3차원 주석을 가진 데이터 세트들을 사용하고, 이를 사용하여 3차원 포즈 추정을 위한 SOTA neural netowkr regressor 를 stronly-supervise 하게 된다. 또한 weak supervision 으로 2차원 주석을 사용할 수도 있다.
Augmentation by Extreme Cropping
이전의 포즈 추정 방법의 단점은 대부분의 신체 모습이 입력 이미지에서 보인다고 가정하는 것이다. 그러나 실제 비디오로 캡쳐한 사람은 종종 잘려나가거나(?) 가려져서 상체 또는 얼굴만 보일 수 있다는 점이 문제다. 이 경우 depth 뿐만 아니라 occlustion 은 포즈를 재구성하는데 있어서 ambiguity 를 극적으로 증가시키게 된다. 따라서 reconsturction 의 품질은 pose prior 의 품질에 의존적이다. 이러한 어려운 경우를 처리할 수 있는 모델을 학습 시키는 것이 목적이기 때문에 극단적인 cropping 으로 학습 데이터를 augmentation 함으로써 이러한 문제를 해결한다. 왜냐면 이미 완전한 3차원 주석을 가지고 있기 때문이고, 학습 데이터를 무작위로 cropping 하기만 하면 된다. 먼저, 상반신을 엉덩이 까지, 얼굴과 어깨를 팔꿈치 까지 자르고 나서, 이 crop bounding box 의 80% ~ 120% 에 해당하는 크기로 crop 을 또 수행하여 random bounding box 를 생성해낸다. 이를 통해 입력 영상이 crop 되는 동안 신경망으로 하여금 full 2D/3D body joint supervision 을 유지하여 occlusion 이 일어난 신체 부위들을 그럴듯하게 재구성하는 방법을 학습하도록 한다.
Learning from Difficult In-the-wild Sample:
이전 까지의 접근 방식들은 2차원 주석을 사용하더라도 신경망을 학습하기 위해서는 어려운 표본을 사용하는 것을 피해왔다. COCO 와 같은 표준 데이터 세트에서는 심한 occlusion 이나 low resolution 으로 인해 샘플이 폐기 될 수 있었다. 이 논문에서 2차원 주석을 통해 생성된 3차원 주석들로 이루어진 데이터들은 이러한 어려운 표본을 처리하는 방법을 학습하는데 매우 가치가 있다고 주장한다. occlusion 에 매우 강력한 새로 학습된 모델을 고려해 볼 때 EFT 방법을 사용하여 어려운 표본에 대해 3차원 주석 데이터 들을 생성함으로 이러한 문제점을 해결할 수 있다. 3차원 주석을 사용할 수 있게 되면 모델을 re-train 하여 robust 하게 만들 수 있다. 그러나 이미지에서 보이지 않는 관절의 3차원 reconstruction 은 매우 ambiguous 하기 때문에 이러한 특정 관절은 학습 손실에서 무시된다. 또한 위에서 설명한 cropping augmentation 전략의 경우에는 이는 해당하지 않는다. 이 경우 모든 관절이 보일 때 자르기를 적용하기 전에 3D reconstruction 이 얻어지기 때문이다.
5. Results
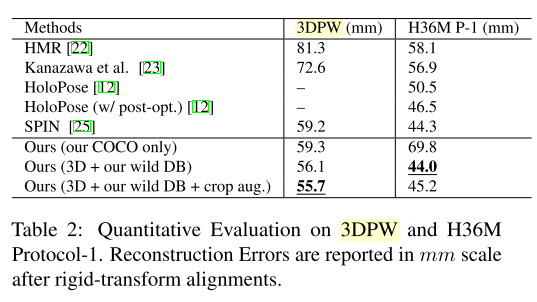
본 논문은 기존 3차원 주석 데이터들이 실내에서만 촬영되어 실 세계에 적용하기 어렵다는 문제점을 해결하기 위해 wild 환경에서의 2차원 포즈 주석을 통해 약 100K 개의 3차원 포즈 주석을 생성하였다. 이 데이터는 비교할 수 있는 3차원 포즈가 제공되지 않기 때문에 다른 방식으로 EFT 를 평가한다. 먼저 Amazon Mechanical Truck(AMT) 의 human annotator 에게 EFT 와 SMPLify 사이에 가장 적합한 것을 선택하도록 요청하여 EFT 와 기존의 최적화 기반 회귀자를 질적으로 비교한다. 그 다음 EFT 에서 개별 샘플에 대한 fine-turning 의 효과를 조사하여 validation set 에서 fine-turning 된 신경망의 성능을 재평가한다. 그리고 2차원 주석이 포함된 Open Dataset 에 EFT 를 적용하여 대규모 3차원 포즈 데이터 세트를 생성하고, 이 데이터를 사용하여 3D human pose regressor 를 full 3D supervision 으로 학습하는 이점을 보여준다. 특히 이는 standard outdoor 3d human pose benchmark 에서 SOTA 성능을 달성한다. 그 다음 challenging real-world video 에 이를 테스트 한다.
EFT 의 핵심 아이디어는 신경망 회귀를 개별 샘플에 맞게 fine-turning 하여 2d fit 을 개선시키는 것인데, 단 하나의 샘플로 신경망을 fine-turning 하게 되면 overfitting 으로 인해 신경망 모델의 정상적인 동작이 변경되거나 중단 될 수 있다.


참고자료 1 : https://arxiv.org/abs/2004.03686
Exemplar Fine-Tuning for 3D Human Pose Fitting Towards In-the-Wild 3D Human Pose Estimation
We propose a method for building large collections of human poses with full 3D annotations captured `in the wild', for which specialized capture equipment cannot be used. We start with a dataset with 2D keypoint annotations such as COCO and MPII and genera
arxiv.org
참고자료 2 : https://jhugestar.github.io/
Hanbyul Joo | Academic Website
I am a Research Scientist at Facebook AI Research (FAIR), Menlo Park. I finished my Ph.D. in the Robotics Institute at Carnegie Mellon University, where I worked with Yaser Sheikh. During my PhD, I interned at Facebook Reality Labs, Pittsburgh (Summer and
jhugestar.github.io
참고자료 3 : https://nneverova.github.io/
Natalia Neverova
Exemplar Fine-Tuning for 3D Human Pose Fitting Towards In-the-Wild 3D Human Pose Estimation Hanbyul Joo, Natalia Neverova, Andrea Vedaldi arXiv preprint PDF Bibtex @inproceedings{Joo2020eft, year={2020}, booktitle={arXiv preprint: 2004.03686}, title={Exemp
nneverova.github.io
'AI Research Topic > 3D Pose and Shape' 카테고리의 다른 글
| [Paper Review] HuMMan, Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling (0) | 2022.11.07 |
|---|---|
| [Paper Review] Recovering 3D Human Mesh from Monocular Images : A Survey (0) | 2022.06.10 |
| [3D Reconstruction] 3차원 주석 데이터에 비의존적으로 3차원 모델을 재구성 하는 방법들 (0) | 2020.06.02 |
| [3D Reconstruction] Deep Structured Implicit Functions (0) | 2019.12.15 |
| [Pose Estimation] SMPL eXpressive (2) | 2019.11.02 |