[Pose Estimation] 자세 추정 결과를 정제 하는 방법 (PoseFix : Model-agnostic General Human Pose Refinement Network)
본 포스팅은 아래 유튜브를 보다가 Pose Refinement 와 관련된 논문을 알게 되어 자세 추정 결과를 정제하는 방법에 대해 정리해본다. 논문은 참고로 서울대 문경식님의 논문이다.
Moon, Gyeongsik, Ju Yong Chang, and Kyoung Mu Lee. "Posefix: Model-agnostic general human pose refinement network."
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
나중에 적용해봐야겠따. 또한 참고로 유튜브 링크는 아래와 같으며, Human Pose Estimation 을 처음 접하는 사람들에게 도움이 될만한 좋은 자료이다.
[AI 콜로퀴움] Human Pose Estimation 기술의 발전과 미래 (이경무 교수)
www.youtube.com/watch?v=GBpnsFfLt2Q
Paper
PoseFix: Model-agnostic General Human Pose Refinement Network
Multi-person pose estimation from a 2D image is an essential technique for human behavior understanding. In this paper, we propose a human pose refinement network that estimates a refined pose from a tuple of an input image and input pose. The pose refinem
arxiv.org
Github
github.com/mks0601/PoseFix_RELEASE
mks0601/PoseFix_RELEASE
Official TensorFlow implementation of "PoseFix: Model-agnostic General Human Pose Refinement Network", CVPR 2019 - mks0601/PoseFix_RELEASE
github.com
Abstract
2차원 영상에서 multi person pose estimation 은 인간의 행동을 이해하기 위한 필수적인 기술이다. 본 논문에서는 입력 이미지와 입력 자세의 튜플에서 정제된 자세를 추정하는 Human Pose Refinement Network 를 제안한다. Pose Refinement 는 주로 이전 학습 방법에서 학습 가능한 end-to-end tranable multi-stage architecture 를 통해 수행되었다. 그러나 이는 자세 추정 모델에 크게 의존하기 때문에 모델을 신중하게 설계하는 것이 필요했었다. 이와는 달리 본 논문에서는 모델 구조에 구애받지 않는 Pose Refinement 방법을 제시한다. 최근 연구된 2차원 인간 자세 추정 방법들은 similar error distribution 을 가지고 있다. 이 error 의 통계를 사전정보로 활용하여 synthetic pose 를 생성하고, synthesized pose 를 이용하여 모델을 훈련한다. 테스트 단계에서는 다른 방법의 자세 추정 결과에 본 논문에서 제안된 방법을 사용하여 Refinement 할 수 있다. 또한 제안된 모델은 다른 방법에 대한 코드나 지식이 필요하지 않으므로 후처리 단계(post-processing)에서 쉽게 사용 할 수 있다.
1. Introduction
인간 자세 추정의 목표는 인체의 semantic keypoints 를 localization 하는 것이다. 이는 인간의 행동을 이해하거나 인간-컴퓨터 간 상호작용을 위해 필수적인 기술이다. 최근 많은 방법들에서 CNN을 활용하여 성능 향상을 달성하고 있다. 또한 MS COCO keypoint detection challenge 에서 performance limit 을 update 하고 있다. 본 논문에서는 입력 이미지와 자세의 튜플에서 정제된 자세를 추정하는 human pose refinement network 를 제안한다.
전통적으로 자세 추정 결과를 정제하는 것은 주로 muti-stage architecture 에 의해 수행되곤 했었다. 즉, 첫번째 단계에서 생성된 초기 자세와 이미지 특징은 후속 단계를 거쳐 각 단계가 정제된 자세를 출력하는 과정을 거쳤으며 이러한 구조는 일반적으로 end-to-end 방식으로 학습된다. 이러한 방법은 자세 추정 모델에 크게 의존하게 되며, 성공적인 정제를 위해 신중한 설계가 필요하다는 단점을 가지고 있다.
따라서 본 논문에서는 자세 추정 모델에 의존적이지 않은 model-agnostic pose refinement 방법을 제안한다.
Fonchi et al. 의 연구에 따르면 일반적인 모델에 구애받지 않는 mose refiner 를 설계하는 방법을 발표하였다. 이는 새로운 자세 추정 평가 지표 즉 키포인트 유사성(KS, Keypoint Similarity) 및 객체 키포인트 유사성(OKS, Object Keypoint Similarity)을 사용하여 MS COCO 2016 Keypoint Detection Challenge 우승자의 결과를 분석하였다. 그들은 자세 추정 오류를 jitter, inversion, swap, miss 와 같은 여러 유형으로 분류하고, 이러한 오류가 발생하는 빈도와 성능에 부정적인 영향을 미칠 수 있는 정도를 설명하였다. 우승자들을 보면 각기 다 다른 접근방식을 사용하였지만 자세 추정 오류 분포들은 매우 유사했기 때문에 여기서 공통적인 문제가 있음을 보여준다.
본 논문에서는 이러한 오류 통계를 사전 정보로 활용하여 synthetic pose 를 생성하고 synthesized pose 를 사용하여 제안된 pose fefinement model 즉 PoseFix 를 학습하는 것이다. 모델을 학습시키기 위해 Ronchi et al. 연구에서 나온 오류 분포를 기반으로 각 유형의 오류(i.e., jitter, inversion, swap, and miss) 를 생성하고 다양하고 사실적인 자세들을 구성한다. 생성된 입력 자세는 입력 이미지와 함께 PoseFix 에 공급되고, PoseFix 는 자세를 다듬는 방법에 대해 학습하게 된다. PoseFix 는 대략적인 coarse-to-fine estimation 방법으로 single-stage architecture 로 설계된다.
입력된 자세를 coarse form 으로 취하고, finer form 으로 정제된 자세를 추정한다. 이렇게 coarse input pose 를 사용하게 되면 제안된 모델이 입력 자세의 정확한 위치 뿐만 아니라 그 주변에도 초점을 맞출 수 있기 때문에 모델이 입력 자세의 오류를 수정하도록 할 수 있다. 또한 출력 자세의 finer form 은 제안된 모델이 기존 방법에 비해 위치를 더 정확하게 파악할 수 있도록 한다. 학습 후 PoseFix 는 모든 single or multi-person pose estimation 결과에 적용이 가능하다.

본 논문의 Contribution 은 다음과 같다.
- 모델에 구애받지 않는 Pose Refinement 가 가능함을 보여주며, PoseFix 는 자세 추정 모델과 독립적으로 학습된다. 대신 경험적인 분석을 통해 얻은 오류 통계를 기반으로 한다.
- PoseFix 는 모든 pose detection 방법의 pose estimation 결과를 입력으로 사용할 수 있다. PoseFix 는 다른 방법에 대한 코드나 지식이 필요하지 않기 때문에 우리의 모델은 매우 높은 유연성과 접근성을 가지고 있다.
- PoseFix를 coarse-to-fine estimation 시스템으로 설계한다. 우리는 이 coarse-to-fine 파이프라인이 성공적인 자세 정제에 중요하다는 것을 관찰하였다.
- PoseFix 는 기존의 multi-stage architecture 기반 정제 방법보다 더 나은 결과를 얻는다. 또한 PoseFix 는 일반적으로 사용되는 벤치마크에서 다양한 stage-of-the-arts pose estimation 의 성능을 지속적으로 향상 시킨다.
2. Related works 는 생략
3. Overview of the proposed model
PoseFix의 목표는 입력 이미지에 있는 모든 사람의 human body keypoints 의 2D coordinates 를 수정하는 것이다. 이러한 문제를 해결하기 위하여 우리의 시스템은 여러 사람을 포함한 전체 이미지를 처리하는 대신 cropped human image 의 tuple 과 해당되는 사람의 주어진 pose estimation result 를 처리하는 top-down pipeline 을 기반으로 구성된다. 학습 단계에서 입력 자세는 사실적 포즈를 기반으로 현실적이고 다양하게 합성된다. 테스트 단계에서 다른 방법의 자세 추정 결과는 시스템에 대한 입력 자세가 될 수 있다. 전체적인 pipeline 은 다음 그림과 같다.
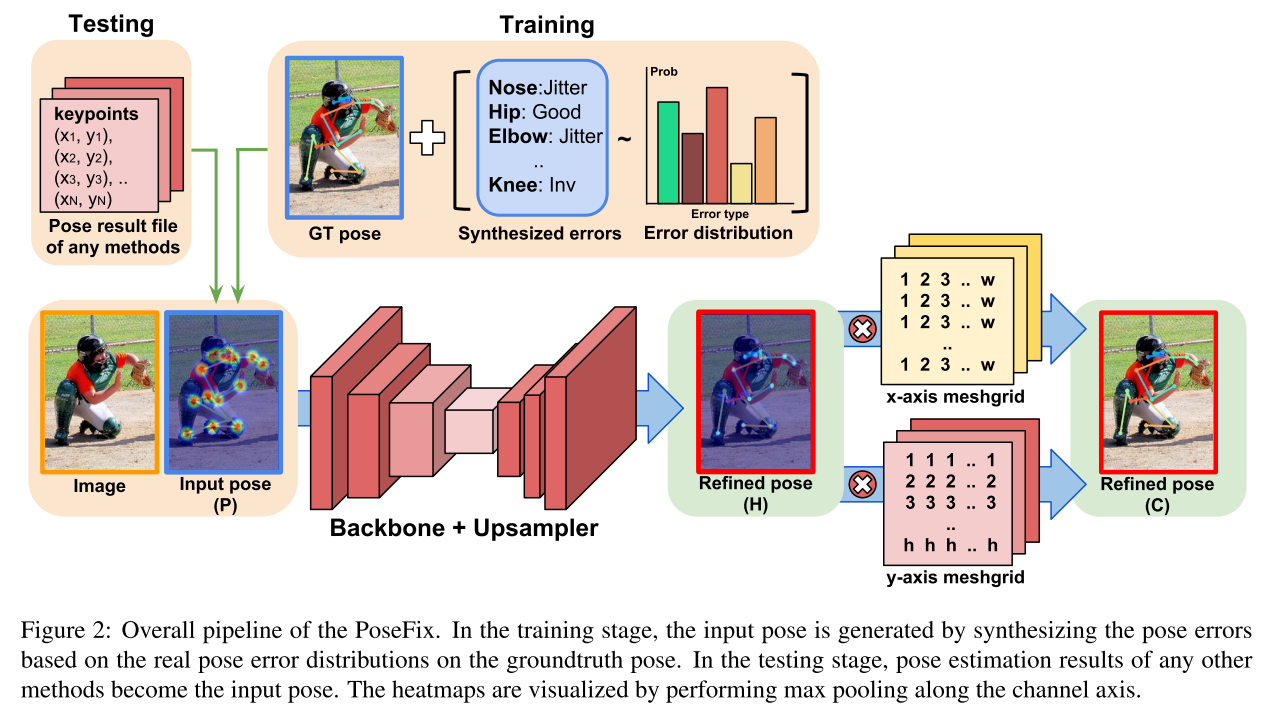
4. Synthesizing poses for training
PoseFix 를 학습하기 위해 우리는 ground truth 자세를 사용항 합성된 포즈를 생성한다. PoseFix 는 테스트 단계의 다양한 방법에서 얻은 다양한 자세 추정 결과를 다뤄야함으로 합성된 자세는 다양하고 사실적이어야한다. 이러한 특성을 만족시키기 위해서 실제 자세의 오차 분포를 기반으로 무작위로 합성된 자세를 생성한다. 이러한 분포에는 joint type, number of visible keypoints, oberlap in the input image 에 따른 각 자세의 오류 빈도 jitter, inversion, swap, miss 등이 포함된다.
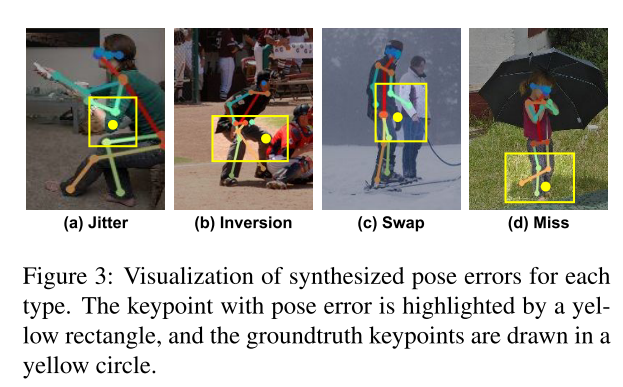
- Good
- Good status 는 GT keypoint 로부터 아주 작은 변위(very small displacement)가 있는 것을 말한다.
- Jitter
- jitter error 는 GT keypoint 에서 작은 변위(small displacement)가 있는 것을 말한다.
- Inversion
- Inversion error 는 left / right body part confusion 을 말한다.
- Swap
- Swap error 는 다른 사람에게 속한(belong to)하여 같거나 또는 유사한 자세의 confusion 을 나타낸다.
- Miss
- Miss error 는 GT keypoint 위치에서 큰 변위(a large displacement)가 있는 것을 말한다.
이렇게 합성된 자세들은 아래와 같다.

5. Architecture and learning of PoseFix
5.1 Model design
그림 2와 같이 입력 이미지와 입력 자세의 튜플에서 정제된 자세를 직접 추정하도록 PoseFix 를 설계한다. 입력 이미지와 입력 자세는 가각 상황 및 구조화 된 정보를 PoseFix 에 제공하며 PoseFix 는 이러한 정보를 사용하여 입력 자세의 오류를 수정하는 방법을 학습하게 된다. 입력 자세의 대부분의 키포인트는 양호한 상태이거나 GT 자세에서 작은 변위를 포함하는 jitter error 가 있다. 이러한 대략적으로 구조화 된 정보는 PoseFix 가 인체에 초점을 맞출 위치를 알려주는 attention 과 같은 역할을 수행한다. 입력 자세에서 자세 오류를 수정하는 방법을 학습함으로써 PoseFix가 아래 그림과 같이 인체에 초점을 맞출 위치(그러니까 정상적인 자세 데이터로)를 학습하는 것을 관찰하였다.

5.2 Coarse-to-fine estimation
이러한 error 에 대해 더 강건하게 모델을 생성하기 위해 제안된 PoseFix 를 Coarse-to-fine 하도록 설계한다. 자세를 표현할 때 불확실성의 정도에 따라 "coarse" and "fine" 이라는 용어를 사용한다. 예를 들어, 자세를 구성하는 각 관절의 위치를 나타낼 때 Gaussian blob 은 표준 편차의 그 크기 만큼 불확실성이 높다. 반면 One-hot vercotr 는 양자화 된 grid 크기까지 상대적으로 낮은 불확실성을 가지고 있다. 키포인트의 좌표는 위치 자체에 대한 정확한 정보를 제공하기 때문에 불확실성이 가장 적이다.
따라서 Gaussian blob 으로 표현되는 coarse input pose $ P = \left \{ P_{n} \right \}_{n=1}^{N} $ 가 신경망에 공급되어 One-hot verctor $ H = \left \{ H_{n} \right \}_{n=1}^{N} $ 의 형태로 더 finer pose 를 생성한 다음 키포인트 좌표의 관점에서 finest pose $ C = \left \{ C_{n} \right \}_{n=1}^{N} $ 를 그림 2와 같이 최종 출력하게 된다. 여기서 N 은 키포인트 수를 나타낸다.
입력 자세는 다음과 같이 single mode Gaussian heatmap representation 에 의해 coarse 형태로 구성된다.
$ P_{n}\left ( i, j \right ) = exp\left ( - \frac{\left ( i-i_{n} \right )^{^{2}} + \left ( j - j_{n} \right )^{^{2}}} {2\sigma ^{2}} \right ) $
여기서 $ P_{n} $ 과 $ i_{n}, j_{n}\left ( i_{n}, j_{n} \right ) $ 은 각 n 번째 키포인트의 입력 Heatmap 과 2D coordinates 이며, $ \sigma $ 는 Gaussian peak 의 표준 편차이다. 생성된 입력 자세는 입력 이미지와 연결되어 PoseFix 에 제공된다.
Gaussian hetmap representation 은 입력 이미지와 픽셀 단위로 정렬되기 때문에 subsequent convolutional operation 에 적합하다. 또한 입력 자세에 오류가 있을 수 있으므로 blob 주변의 0 이 아닌 값을 사용하여 PoseFix 가 입력 자세의 정확한 위치 뿐만 아니라 그 주변에도 집중할 수 있도록 할 수 있다.
대략적인 형태의 input Gaussian heatmap 으로부터 제안된 신경망은 히트맵 $ H_{n} $ 과 n 번째 키포인트에 대한 키포인트 좌표 $ C_{n} $ 을 순차적으로 생성한다. $ H_{n} $ 을 더 미세한 형태로 만들기 위해 One-hot vector 를 사용하여 supervise 한다. 그 다음 soft-argmax 연산을 $ H_{n} $ 에 적용하여 미분 가능한 방식으로 $ C_{n} $ 를 생성한다. Soft-argmax 는 그림 2와 같이 입력 히트맵과 meshgrid 사이의 element-wise 로 정의되며 그 뒤에 summation 하게 된다. $ H_{n} $ 로부터 $ C_{n} $ 은 다음과 같이 정의된다.
$ C_{n} = \left ( \sum_{i=1}^{w}\sum_{j=1}^{h} iH_{n}\left ( i, j \right ), \sum_{i=1}^{w}\sum_{j=1}^{h} jH_{n}\left ( i, j \right )\right ) ^{^{T}} $
여기서 w, h 는 $ H_{n} $ 의 width, height 를 뜻하며, 아래와 같이 cross entropy based integral loss 에 의해 학습된다.
$ L = L_{H} + L_{C} $
여기서 $ L_{H} $ 및 $ L_{C} $ 은 다음과 같이 정의된다.
$ L_{H} = -\frac{1}{N}\sum_{n=1}^{N}\sum_{i, j}^{}H_{n}^{*}\left ( i, j \right )log H_{n}\left ( i, j \right )
$
여기서 $ H_{n}^{*} $ 및 $ H_{n} $ 은 softmax 가 적용된 GT 및 estimated heatmap 이며, GT heatmap 인 $ H_{n}^{*} $ 은 키포인트 좌표가 정수일 때 One-hot vector 이다. 그렇지 않으면 각 x 및 y 축에 대한 두 개의 grid 가 floor and ceil 에 의해 선택되고 선형 추정에 의해 확률로 채워진다.
$ L_{C} = \frac{1}{N}\sum_{n=1}^{N}\left \| C_{n}^{*}-C_{n} \right \|
_{1} $
$ L_{C} $ 는 L1 loss 의 합계로 표현된다. 여기서 $ C_{n}^{*} $ 은 n 번째 키포인트를 위한 GT coordinates vector 이며, $ L_{H} $ 는 PoseFix 가 추정된 히트맵에서 single grid point 를 선택하도록 강제하고, 이를 사용하면 양자화 오류가 없는 연속 공간에서 계산되기 때문에 PoseFix 가 키포인트를 보다 정확하게 localization 할 수 있다.
5.3 Network architecture
우리는 Xial et al. 의 구조를 사용하였으며, 이는 deep backbone network (i.e., ResNet) 및 여러 upsampling layer 로 구성된다. final upsampling layer는 softmax function 을 적용한 후 heatmaps (H)가 된다. soft-argmax 연산은 히트맵에서 좌표 C를 추출하고, 이는 PoseFix 의 최종 추정 값이 된다.
6. Implementation details
생략
7. Experiment
실험결과는 다음과 같다.
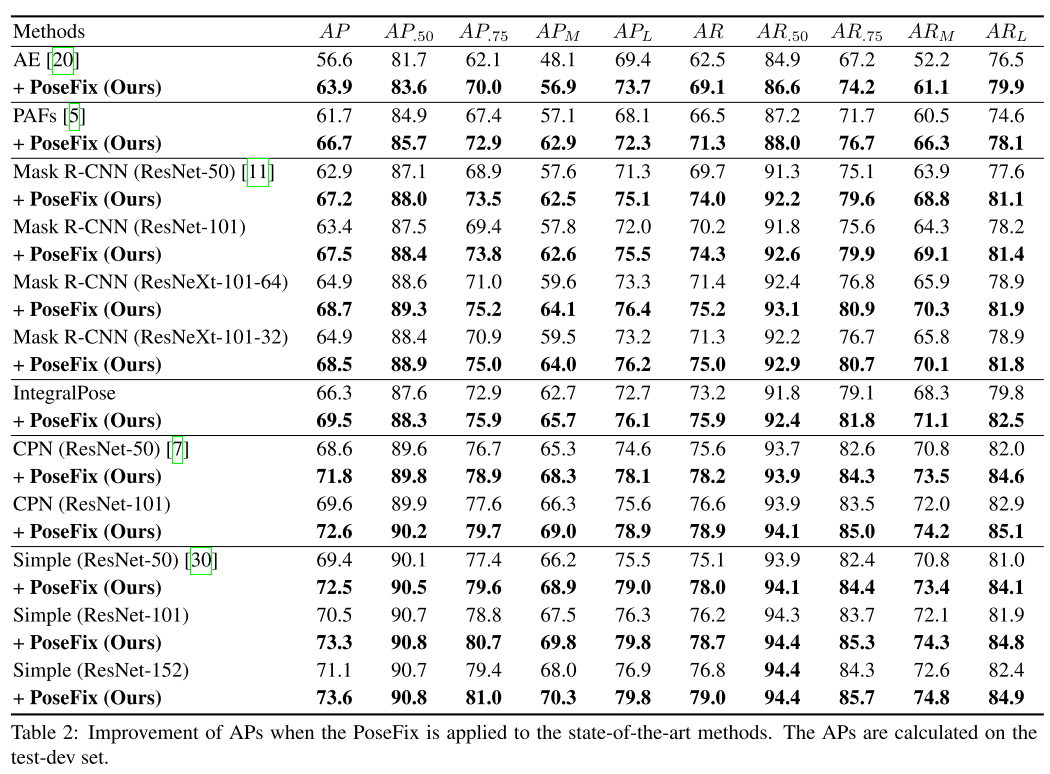
추가적으로 HRNet 에 대해 실험한 결과는 아래와 같다.

결과 영상은 아래와 같다.

