
[Pose Estimation] 3D human pose estimation in video with temporal convolutions and semi-supervised training


이 논문은 Facebook AI Research 에서 나온 논문이며, CVPR 2019에 채택되었다. 3D Human Pose Estimation 분야를 찾아보다가 알게된 논문인데, 현존하는 SOTA 2D Pose Estimation 방법들과 잘 결합하면 비디오 환경에서 좋은 결과를 얻을 수 있을 것으로 예상된다. 관건은 정확도 높은 2D Pose Estimation 이다. 위 gif 들은 아마 2D Pose GT를 이용했기 때문에 3D Pose 가 매우 자연스러워 보인다.
Paper : arxiv.org/pdf/1811.11742.pdf
Github : github.com/facebookresearch/VideoPose3D
facebookresearch/VideoPose3D
Efficient 3D human pose estimation in video using 2D keypoint trajectories - facebookresearch/VideoPose3D
github.com
Project : dariopavllo.github.io/VideoPose3D/
3D human pose estimation in video with temporal convolutions and semi-supervised training
Abstract In this work, we demonstrate that 3D poses in video can be effectively estimated with a fully convolutional model based on dilated temporal convolutions over 2D keypoints. We also introduce back-projection, a simple and effective semi-supervised t
dariopavllo.github.io
이 논문을 발표하신 분의 유튜브 링크도 첨부한다. 요즘은 티스토리에 유튜브 링크를 첨부하면 바로 재생 해서 볼 수 있어서 좋은 것 같다.
Youtube : www.youtube.com/watch?v=LK7gHHDvPCk&feature=youtu.be
Abstract
본 논문에서는 비디오 환경에서 2차원 키포인트에 대해 diated temporal convolution 기반의 fully convolutional model 을 적용하여 효과적으로 3차원 자세 추정을 수행하게 된다. 또한 레이블이 지정되지 않은 비디오 데이터(unlabeled video data)를 활용하는 간단하고 효과적인 semi-supervised 학습 방법인 back-projection 을 소개한다. 레이블이 지정되지 않은 비디오 데이터에 대해 예측된 2차원 키포인트를 시작으로 3차원 자세를 추정하고 마지막으로 입력된 2차원 키포인트를 역투영 하는 방식으로 진행된다.
supervised setting 에서 본 논문의 fully-connectional model 은 Human3.6M 데이터에서 평균 6mm의 mean per-joint position error를 기록하였으며 11% 정도의 상당한 error reduction 을 보였다.
1. Introduction
본 논문에서는 비디오 환경에서 3차원 인간 자세 추정 문제를 다룬다. 이 문제를 2차원 키포인트 탐지와 3차원 자세 추정 방법을 기반으로 풀게 되는데, 이 문제를 분할하게 되면 작업의 난이도가 줄어들 수 있지만 여러 3차원 자세들이 동일한 2차원 키포인트에 매핑 될 수 있기 때문에 본질적으로 모호성이 존재하게 된다. 이전의 작업들은 RNN(Recurrent Neural Network)을 사용하여 시간 정보를 모델링함으로써 모호성을 해결해왔다. 반면, CNN(Convolutional Neural Network)은 음성 인식, 언어 모델링과 같이 전통적으로 RNN으로 처리되었던 작업에서 시간 정보를 모델링하는데 성공적인 결과를 거두었다. 이와 같이 CNN 기반의 모델은 RNN에서 불가능했던 여러 프레임의 병렬 처리를 가능하게 하였다.
본 논문에서는 비디오 환경에서 정확한 3차원 자세를 예측하기 위해 2차원 키포인트에 대해 temporal convolution을 수행하는 fully convolutional 구조를 제시한다. 이러한 접근 방식은 2차원 키포인트 탐지기와 호환되며, 확장된 컨볼루션을 통해 대규모의 컨텍스트(context)를 효과적으로 처리할 수 있다. RNN에 의존하는 접근 방식에 비해 계산 복잡성과 매개 변수 수 측면에서 더 높은 정확도, 단순성 및 효율성을 제공 할 수 있다. 또한 2차원 키포인트 탐지기를 사용하여 레이블이 없는 비디오의 2차원 키포인트를 예측하고 3차원 키포인트를 예측한 다음, 다시 이를 2차원 공간에 매핑한다.
본 논문의 Contribution은 다음과 같다.
- 2차원 키포인트 궤적(trajectory)에서 dilated temporal convolution을 기반으로 비디오에서 3차원 인간 자세 추정을 위한 간단하고 효율적인 접근 방식을 제시하였다는 것
- 이 모델은 계산 복잡성과 모델 매개 변수 수 측면에서 동일한 수준의 정확도에서 RNN 기반 모델보다 더 효율적임을 보여주었음.
- 레이블이 없는 비디오를 활용하고, 레이블이 있는 데이터가 부족할 때 효과적인 semi-supervised 방식을 도입한 것
- 이전의 semi-supervised 접근 방식과 비교할 때 Ground Truth 2D annotation 또는 Camera Intrinsic Prameter 가 있는 multi-view image 보다는 extrinsic camera parameter 만 필요함.
- SOTA 와 비교했을 때 본 논문의 접근 방식은 supervised 및 semi-supervised 방식 모두에서 가장 우수함
- 우리의 supervised model은 학습을 위해 추가로 레이블이 지정된 데이터를 사용하더라도 다른 모델보다 성능이 뛰어남
2. Related work
너무 고전적이고 뻔한 이야기들로 가득하므로 생략한다 ...
중요한 얘기만 간추려 보자면
히트맵을 사용하지 않고 탐지된 키포인트 좌표로 자세를 다루며, 이를 통해 개별적인 히트맵에 대한 2차원 컨볼루션 대신 좌표 시계열(time series)에 대해 효율적인 1차원 컨볼루션을 사용한다. 이러한 접근 방식은 키포인트 공간 해상도와 독립적인 계산 복잡성을 달성 할 수 있다.
또한 다른 모델들과 비교했을 때 시간 차원에서 1차원 컨볼루션을 수행하여 시간 정보를 활용하고, reconstruction error 를 낮추는 몇가지 최적화 방법을 제안한다.
다른 모델들과 달리 seq2seq 모델 대신 deterministic mapping 을 배우게 된다.
그리고 대부분의 2차원 자세 추정 모델들은 two-step 모델들(Stacked hourglass Network)을 사용하지만, 본 논문에서는 Mask R-CNN + CPN(Cascaded pyramid network)를 사용한다.
3. Temporal dilated convolutional model

본 논문에서 제안하는 모델은 2차원 자세 좌표를 입력으로 받아 temporal convolution 을 통해 변환하는 residual connection이 포함된 fully convolutional 구조이다. CNN 모델은 배치 및 시간 차원에서 병렬화를 가능하게 하지만 RNN 모델은 시간에 따라 병렬화를 할 수 없다. 컨볼루션 모델에서 출력과 입력 사이의 기울기 경로(path of the gradient)는 시퀀스 길이에 상관 없이 고정된 길이를 가지기 때문에 RNN에 영향을 주는 vanishing 문제 및 exploding gradient 문제를 완화 시킬 수 있다.
컨볼루션 구조는 temporal receptive field에 대해 precise control를 제공하게 되며 이는 3차원 자세 추정 작업에 대한 시간 종속성(temporal dependency)을 모델링하는 데 유용하다는 것을 발견하였다. 게다가 dilated convolution을 사용하여 장기 종속성(long-term dependency)을 모델링 하는 동시에 효율성을 유지하게 된다. dilated convolution이 있는 구조는 audio generation, semantic sgementation, machine translation에서 성공적인 결과를 얻어냈었다.
입력 레이어(input layer)는 각 프레임에 대한 $ J $ 관절의 연결된 $ (x, y) $ 좌표를 취하게 되고, 커널 크기 $ W $ 및 출력 채널 $ C $와 함께 temporal convolution 을 적용한다. 그 다음 스킵 연결(skip connection)으로 둘러싸인 $ B $ 즉, ResNet-style block이 이어지게 된다. 각 블록은 먼저 커널 크기 $ W $ 및 확장 계수 $ D = W^{B} $ 로 1D Conv 를 수행한 다음 커널 크기 1로 컨볼루션을 수행하게 된다.
컨볼루션(마지막 레이어 제외) 다음에는 배치 정규화(Batch Normalization), ReLU(Rectified Linear Units), Dropout이 이어지게 된다. 각 블록은 receptive field 를 $ W $의 계수 만큼 지수적으로 증가시키는 반면, 매개 변수의 수는 선형으로만 증가하게 된다. 필터 하이퍼파라미터(filter hyperparameters), $ W $ 및 $ D $는 모든 출력 프레임에 대한 receptive field 가 모든 입력 프레임을 덮는 트리를 형성하도록 설정된다. 마지막으로 마지막 레이어는 시간 정보를 활용하기 위해 과거 및 미래 데이터를 모두 사용하여 입력 시퀀스의 모든 프레임에 대한 3차원 자세 예측을 출력하게 된다.

실시간 시나리오를 평가하기 위해 causal convolution 즉 과거 프레임에만 접근 할 수 있는 컨볼루션을 가지고 실험하게 되며, 컨볼루션 이미지 모델은 일반적으로 제로 패딩(zero-padding)을 적용하여 입력 만큼 많은 출력을 얻게 되는데 초기 실험은 왼쪽과 오른쪽의 경계 프레임 복제본으로 입력 시퀀스를 채우면서 패딩 되지 않은 컨볼루션 만 수행할 때 더 나은 결과를 보여주었다고 한다. 그림 2에서는 $ B = 4 $ 블록인 243 프레임의 receptive field 크기에 대한 구조의 인스턴스화를 보여준다. 컨볼루션 레이어에 경우 $ C = 1024 $ 출력 채널로 $ W = 3 $을 설정하고 Dropout 비율 $ p = 0.25 $ 를 사용하였다.
4. Semi-supervised approach

본 논문에서는 공개되어있는 비디오를 2치원 키포인트 탐지기와 결합하여 back-projection loss term 으로 supervised loss function을 확장한다. 레이블이 지정되지 않은 데이터에 대한 자동 인코딩 문제를 해결하며, 인코더(자세 추정기)는 2차원 관절 좌표에서 3차원 자세를 추정하고 디코더(projection layer)는 3차원 자세를 2차원 관절 좌표로 다시 투영하게 된다. 디코더의 2차원 관절 좌표가 원래 입력에서 멀리 떨어져 있는 경우 학습되는 동안 패널티를 부여받는다. 그림 3에서는 supervised component 와 정규화 역할을 수행하는 unsupervised component 를 결합하는 방법을 나타낸다.
두 가지 목표는 레이블이 지정된 데이터가 배치의 전반부를 차지하고, 레이블이 지정되지 않은 데이터가 후반부를 차지하도록 공동으로 최적화 시킨다. 레이블이 지정된 데이터의 경우 GT 3차원 자세를 대상으로 사용하고 supervised loss 를 학습한다. 레이블이 지정되지 않은 데이터는 예측된 3차원 자세가 2차원으로 다시 투영된 다음 입력과의 일관성을 확인하는 오토인코더(autoencoder) 손실을 구현하는데 사용된다.
Trajectory model
perspective projection으로 인해 화면의 2차원 자세는 궤적(trajectory)과(i.e. the global position of the human root joint) 3차원 자세(the position of all joints with respect to the root joint)에 따라 달라진다. 즉 투영 과정으로 인하여 2차원 자세가 궤적 및 3차원 자세에 따라 달라진다는 것이다. 전역적인 위치(global position)가 없으면 피사체는 항상 고정된 배율로 화면 중앙에 재투영된다. 따라서 사람의 3차원 궤적을 회귀(regression)하여 2차원으로써의 역투영을 올바르게 수행할 수 있다.
이를 위해 카메라 공간에서 글로벌 궤적을 회귀하는 두번째 신경망을 최적화한다. 후자는 2차원으로 다시 투영하기 전에 자세가 추가된다. 두 신경망은 동일한 구조를 가지고 있지만 다중 작업 방식으로 학습 될 때 서로 부정적인 영향을 미친다는 사실을 확인했기 때문에 가중치를 공유하지 않는다.
피사체가 카메라에서 멀어지면 정확한 궤적을 회귀하기가 어려워지므로 궤적에 대해 WMPJPE(a weighted mean per-joint position error) 손실함수를 최적화 한다.
$ E = \frac{1}{y_{z}}\left \| f(x) - y \right \| $
즉, 카메라 공간에서 Ground-truth depth($ y_{z}$)의 역(inverse)을 사용하여 각 샘플에 가중치를 부여한다. 해당 2차원 키포인트가 작은 영역에 집중되는 경향이 있기 때문에 멀리 있는 피사체에 대한 정확한 궤적을 회귀하는 것은 본 논문에서 필요치 않다.
Bone length L2 Loss
입력을 복사하는 대신 그럴듯한 3차원 자세의 예측을 고려하기 위해 레이블이 없는 배치에 존재하는 대상체의 평균 뼈 길이(mean bone lenth)를 레이블이 붙어있는 배치에 존재하는 대상체에 대략적으로 일치시키는 소프트 제약 조건(soft constraint)을 추가하는 것이 효과적임을 발견하였다. "Bone length L2 loss" 이라는 용어는 self-supervision에서 중요한 역할을 수행한다.
Discussion
본 논문의 방법은 상업용 카메라에 자주 사용되는 카메라 고유 매개변수만을 필요로 한다. 이 접근 방식은 특정 신경망 구조와 관련이 없으며 2차원 키포인트를 입력으로 사용하는 모든 3차원 자세 추정기에 적용할 수 있다. 우리의 실험에서는 2차원 자세를 3차원에 매핑하게 된다. 이렇듯 3차원 자세를 2차원으로 투영하기 위해 선형 매개 변수(focal length, principal point)와 비선형 렌즈 왜곡 계수(tangential, radial)를 고려하는 간단한 투영 계층을 사용한다. Human3.6M에서 사용된 카메라의 렌즈 왜곡은 자세 추정 메트릭에 미미한 영향을 미쳤지만, 이는 항상 실제 카메라 투영보다 정확한 모델링을 제공하기 때문에 포함되었다.
5. Experimental setup
5.1 Dataset and Evaluation
Human3.6M 및 HumanEva-I의 두 가지 모션 캡쳐 데이터 세트를 평가한다. Human3.6M에는 11개의 subject 에 대한 360만개의 비디오 프레임이 포함되어 있으며, 그 중 7개는 3차원 자세로 주석이 달려있다. 각 subject는 50Hz 에서 4개의 동기화 된 카메라를 사용하여 기록된 15가지 동작을 수행한다. 이전 연구에 이어 17개의 관절 골격을 채택하고 5개의 subject(S1, S5, S6, S7, S8)에 대해 학습하고 2개의 subject(S9, S11)에 대해 테스트한다.
모든 행동에 대해 단일 모델을 훈련하게 되며, HumanEva-I는 60Hz 에서 3개의 카메라 뷰에서 기록된 3개의 Subject가 있는 훨씬 작은 데이터 세트이며, 각 동작(single action, SA)에 대해 서로 다른 모델을 학습하여 세 가지 동작(Walk, Jog, Box)을 평가한다. 또한 이전 연구에서와 같이 모든 동작(multi action, MA)에 대해 하나의 모델을 학습할 때 결과를 보고한다. 15개의 관절 골격을 채택하였으며 데이터 세트에서 제공하는 train / test split 을 사용한다.
본 논문의 실험에서는 세 가지 평가 프로토콜이 존재한다.
- Protocol 1
- 밀리미터(mm) 단위의 평균 관절 위치 오차(MPJPE, mean per-joint position error)로 예상 관절 위치와 GT 관절 위치 사이의 평균 유클리디안 거리(Euclidean distance)를 사용한다.
- Protocol 2
- 변환(translation), 회전(rotation), 스케일(scale) 즉 P-MPJPE 에서 GT와 정렬한 후의 오류를 사용한다.
- Protocol 3
- semi-supervised 실험을 위해 예측된 자세를 스케일 관점에서만 GT와 일치시킨 것(N-MPJPE)을 사용한다.
5.2 implementation details for 2D pose estimation
대부분의 이전 연구들에서는 GT 바운딩 박스로부터 대상을 추출한 다음 Stacked Hourglass Detector 를 적용하여 GT 바운딩 박스 내의 2차원 키포인트 위치를 예측하였다. 본 논문에서는 특징 2차원 키포인트 탐지기에 의존하지 않는다. 따라서 우리는 야생(wild)에서 우리의 설정을 사용할 수 있는 GT box 에 의존하지 않는 몇 가지 2차원 검출기를 조사하였다. SH 모듈 외에도 Detectron의 참조 구현과 FPN의 확장판인 CPN(Cascaded Pyramid Network)을 사용하여 ResNet-101-FPN 백본이 있는 Mask R-CNN을 살펴보았다.
CPN 구현에는 외부에서 제공되는 바운딩 박스가 필요하다. 우리는 Mask R-CNN 상자를 사용하였다. Mask R-CNN과 CPN 모두 COCO에 대한 사전 훈련된 모델로 시작하여 COCO의 키포인트가 Human3.6M과 다르기 때문에 Human3.6M의 2차원 투영에 대한 탐지기를 미세 조정(fine-tuning)한다.
ablation에서는 Human3.6M의 3차원 관절을 추정하기 위해 사전 훈련된 2차원 COCO 키포인트에 대해 3차원 자세 추정기를 직접 적용하는 실험도 수행한다.
Mask R-CNN의 경우 "stretched 1x" 스케쥴로 학습된 ResNet-101 을 백본으로 채택한다. Human3.6M에서 모델을 미세 조정할 때 새로운 키포인트 세트를 학습하기 위해 히트맵을 회귀하는 deconv 레이어 뿐만 아니라 키포인트 신경망의 마지막 레이어를 다시 초기화 한다. a step-wise decaying learning rate 로 4개의 GPU에서 학습하였으며, 60k 의 반복(iteration)의 경우 1e-3, 10k 반복의 경우 1e-4, 그 다음 10k 반복의 경우 1e-5를 사용하였다. 추론(inference)과정에서 히트맵에 소프트맥스(softmax)를 적용하고 2차원 분포(soft-argmax)의 예상 값을 추출한다. 따라서 hard-argmax 보다 더 부드럽고 정확한 예측이 가능하다.
CPN의 경우 384 x 288 해상도의 ResNet-50 백본을 사용한다. 미세 조정을 위해 GlobalNet 및 RefineNet의 최종 계층을 다시 초기화 하는 과정을 거친다. 그 다음 하나의 GPU에서 32개의 이미지 배치와 a step-wise decaying learning rate 로 학습한다. 6k 반복의 경우 5e-5(초기 값의 1/10 정도), 4k 반복의 경우 5e-6, 마지막으로 2k 반복의 경우 5e-7로 학습한다. 미세 조정하는 동안 배치 정규화를 계속 활성화 한다. GT 바운딩 박스로 훈련하고 미세 조정된 Mask R-CNN 모델에 의해 예측된 경게 상자를 사용하여 테스트 한다.
5.3 Implementation details for 3D pose estimation
다른 연구들과의 일관성을 위해 global trajectory 를 사용하지 않고 카메라 변환에 따라 실제 자세를 회전 및 변환하여 카메라 공간에서 3차원 자세를 학습하고 평가한다. optimizer는 Amsgrad 를 사용하였고 80 epoch 동안 학습하였다. Human3.6M의 경우 $η$ = 0.001 부터 시작하여 각 epoch에 적용되는 shrink facter α = 0.95로 기하 급수적으로 감소하는 학습률을 사용한다. 모든 temporal model 즉 receptive field 가 1보다 큰 모델은 자세 시퀀스에서 샘플에 상관관계에 민감하다. 이것은 독립적인 표본을 가정하는 배치 정규화에 대한 편향된 통계를 초래하기 때문에 실험에서는 학습 중에 많은 수의 인접 프레임을 예측하면 임시 정보를 사용하지 않는 모델 보다 더 나쁜 결과가 나온 다는 것을 발견하였다. 다른 비디오 세그먼트에서 학습 클립을 선택하여 학습 샘플의 상관 관계를 줄인다. 클립 세트 크기는 모델이 학습 클립 당 단일 3차원 자세를 예측할 수 있도록 the width of the receptive field 로 설정된다. 이것은 일반화에 있어 중요하다.
dilated convolution을 stride가 dilation factor 로 설정되어 있는 strided convolution으로 대체함으로써 단일 프레임 설정을 최적화 할 수 있다. 이렇게 사용하면 사용되지 않는 컴퓨팅 상태를 피하고 학습 중에만 최적화를 적용하게 된다. 추론 시 전체 시퀀스를 처리하고 다른 3차원 프레임의 중간 상태를 재사용하여 더 빠른 추론을 수행할 수 있다. 이것은 모델이 시간 차원에 걸쳐 어떠한 형태의 풀링도 사용하지 않기 때문에 가능한 것이다. 프레임이 유효한 컨볼루션으로 손실되는 것을 방지하기 위해 복제(replication)로 패딩하지만 시퀀스의 입력 경계에서만 패딩한다.
배치정규화의 기본 하이퍼 파라미터가 테스트 오류(± 1 mm)의 큰 변동과 추론을 위한 실행 추정의 변동을 유발하는 것을 관찰하였다. 보다 안정적인 통계를 얻기 위해 배치 정규화 모멘텀 β 에 대한 스케쥴을 사용한다. β = 0.1 에서 시작하여 지수적으로 감소하여 마지막 epoch에서 β=0.001에 도달하도록 한다.
마지막으로 우리는 학습 및 테스트 시간에 horizontal filp augmentation을 수행한다.
HumanEva의 경우 N = 128, α = 0.996을 사용하고 27 프레임의 receptive field를 사용하여 1000 epoch 동안 학습한다. HumanEva의 일부 프레임은 sensor dropout으로 인해 손상되었으며 손상된 비디오를 유효한 연속 청크(chunk)로 분할하고 독립적인 비디오로 취급한다.
6. Results
6.1 Temporal dilated convolutional model Table

다음 표 1에서는 두 평가 프로토콜에 대해 B = 4 개의 블록과 243개의 receptive field를 사용하는 컨볼루션 모델의 결과를 보여준다. 이 모델은 두 프로토콜 모두에서 다른 접근 방식들 보다 평균 오류가 낮으며 프로토콜 1에서 이전의 SOTA 결과 보다 평균 6mm 더 우수한 성능을 보여 11% 오류 감소를 이뤄냈다. 특히나 SOTA의 방법은 GT를 사용하였지만 본 논문의 모델은 GT를 사용하지 않았다는 점이 인상적이다.

모든 컨볼루션 커널의 너비를 $ W = 1 $ 로 설정한 단일 프레임 기준(baseline)에 비해 프로토콜 1의 오류가 평균 약 5mm 더 높기 때문에 모델은 시간 정보를 활용한다는 것을 분명하게 나타난다. "Walk" (6.7 mm) 및 "Walk Together" (8.8 mm)와 같이 동적인 동작의 경우 간격이 더 크다. GT 바운딩 박스와 Mask R-CNN을 사용하여 예측된 바운딩 박스와 유사한 성능을 나타낸다. 이는 예측이 단일 주제 시나리오에서 완벽하다는 것을 뜻한다.
다음으로 2차원 키포인트 검출기가 최종 결과에 미치는 영향을 평가하였는데 아래 표3과 같이 GT 2D 자세, SH, Detectron 및 CPN에 대한 프로토콜 평가 결과는 아래와 같다.

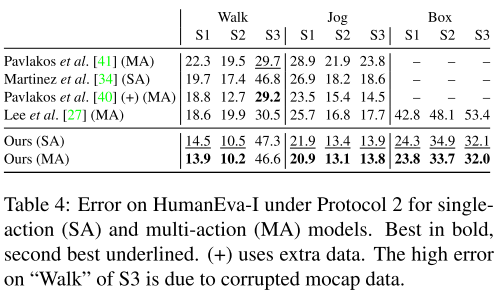
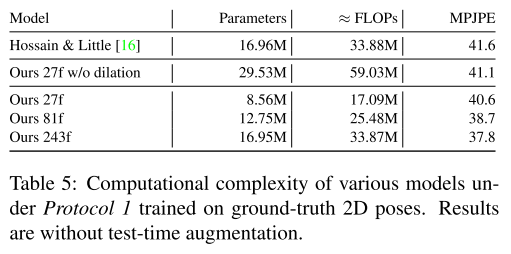
또한 3차원 자세 시퀀스의 1차 도함수의 MPJPE에 해당하는 관절 속도 오류(MPJVE, measure joint velocity error)를 측정한다. 표 2는 본 논문의 모델이 단일 프레임 기준의 MPJVE를 평균적으로 76% 감소 시켜 훨씬 더 부드러운 자세 추정 결과를 제공한다는 것을 보여준다. 또한 표 4에서는 HumanEva-I의 결과와 모델이 더 작은 데이터 세트로 일반화 되었음을 보여준다. 결과는 사전 훈련된 Mask R-CNN 2차원 탐지를 기반으로 한다. 이 모델은 SOTA를 능가하며, 마지막으로 표 5에서는 복잡도 측면에서 이전 연구(LSTM)와 컨볼루션 모델을 비교한다.
6.2. Semi-supervised approach
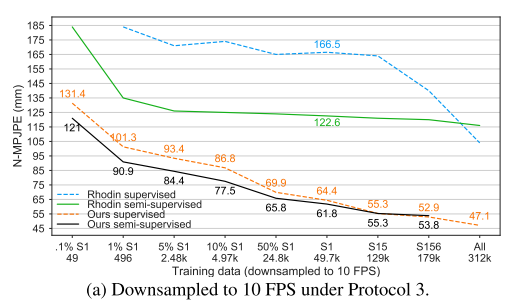
Human3.6M 학습 세트의 다양한 하위 집합을 레이블이 지정된 데이터로 간주하고 나머지 샘플은 레이블이 없는 데이터로 사용한다. 일반적으로 모든 데이터를 50 FPS에서 10 FPS로 다운 샘플링한다. 레이블이 지정된 하위 집합은 먼저 subject 를 줄인 다음 subset 1 을 다운 샘플링하여 생성한다. 데이터 세트가 다운 샘플링되었으므로, 업 샘플링된 45 프레임에 해당하는 9 프레임의 receptive field 를 사용한다. S1 의 1% 및 5%라는 매우 작은 하위 집합의 경우 3개의 프레임을 사용하고, S1의 0.1%에 대해 49개의 프레임만 사용할 수 있는 단일 프레임 모델을 사용한다.
레이블이 지정된 데이터에서만 CPN을 미세 조정하고 몇 epoch(>=S1의 경우 1 epoch, 더 작은 부분 집합의 경우 20 epoch) 동안 레이블 된 데이터에 대해서만 반복하여 학습을 워밍업 한다. 그림 5a는 레이블이 지정된 데이터의 양이 감소함에 따라 semi-supervised 방식이 더 효과적이라는 것을 보여준다. 레이블이 5k 미만인 설정의 경우, 우리의 접근 방식은 supervised 방식 기준보다 약 9-10.4mm N-MPJPE의 개선을 달성한다.
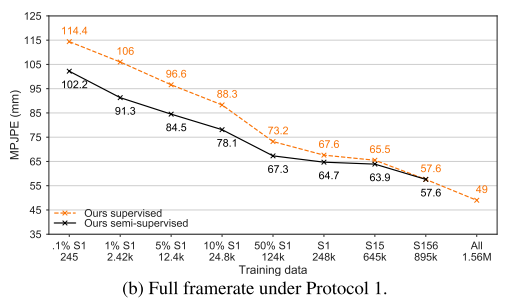
5b는 다운샘플링 되지 않은 데이터 세트 버전(50 FPS)에 대해 일반적인 프로토콜 1에 따른 결과를 보여준다. 이러한 설정은 비디오에서 전체 시간 정보를 활용할 수 있기 때문에 우리의 접근방식에 더 적합하다. 여기서 27개의 프레임의 receptive field 를 사용한다. 단, 9개 프레임을 사용하는 S1 의 1%와 하나의 프레임을 사용하는 S1의 0.1%를 제외하고서를 말한다. semi-supervised 접근방식은 supervised 기준에서 최대 14.7mm MPJPE를 얻는다.
아래 그림 5c는 더 나은 2차원 키포인트 검출기로 더 나은 성능을 발휘할 수 있는지 알아보기 위해 2D GT 정보를 CPN 2D 키포인트로 전환하여 실험하였다. 이 경우 최대 22.6mm MPJPE (S1의 1 %)까지 개선 될 수 있으며, 이는 더 나은 2D 감지가 성능을 향상시킬 수 있음을 확인 하였다.

7. Conclusion
본 논문에서는 비디오 환경에서 3차원 인간 자세 추정을 위해 간단한 fully convolutional model 을 도입하였다. 이러한 구조는 2차원 키포인트 궤적에 걸쳐 dilated convolution 으로 시간 정보를 추출한다. 또한 레이블이 있는 데이터가 부족할 때 성능을 향상시킬 수 있는 semi-supervised 방법인 back-projection이 주된 기여점이다. 이 방법은 레이블이 지정되지 않은 비디오와 함께 작동하며 내장 카메라 매개변수(intrinsic camera parameter)만 필요하므로 모션 캡처가 어려운 시나리오에서 실용적이다.
또한 Human3.6M 데이터 세트의 SOTA 결과보다 6mm 정도로 11% 정도 오류를 개선하였으며, HumanEva-I에서도 개선을 보였다. back-projection은 5k 이하의 주석이 달린 프레임을 사용할 수 있을 때 약 10mm N-MPJPE(15mm MPJPE)까지 3차원 자세 추정 정확도를 향상 시킬 수 있다.