
[Paper Review] The PASCAL Visual Object Classes (VOC) Challenge
커스텀 데이터 세트를 구축하다가 과연 이 문제에 대해서 오픈 데이터 세트를 만드는 사람들은 고민을 안했을까? 당연히 했겠지? 🤯 그럼 논문을 읽어보자 해서 급 읽게 된 논문 The PASCAL Visual Object Classes (VOC) 챌린지에 대한 리뷰입니다. VOC 데이터 세트는 Object Detection 분야에서 주로 사용이 되고 있고, 워낙 나온지 오래된 데이터 세트라서 논문 인용수가 13k 건 정도 되네요.
우선 PASCAL VOC(Visual Object Classes) 챌린지는 object category recognition 및 detection 의 벤치마크로 vision 및 machne learning 커뮤니티에 image 및 annotation의 standard evaluation procedure 을 제공합니다. 2005년 부터 현재까지 매년 챌린지 및 관련 데이터 세트는 object detection 의 벤치마크로 받아들여져 왔습니다. 논문에서는 데이터 세트와 평가 절차가 어떻게 되는지 상세히 설명합니다.
Introduction
PASCAL VOC 챌린지는 다음 두 가지로 구성됩니다.
1. standardised evaluation software 와 함께 공개적으로 사용 가능한 image 및 annotation 데이터 세트
2. annual competition 및 workshop
VOC2007 데이터 세트는 flicker 웹사이트에서 수집한 annotation 이 달린 consumer photograph 로 구성됩니다. 2006년 부터 해마다 ground truth annotation 이 포함된 새로운 데이터 세트가 릴리즈 되고 있습니다. 현재는 2012년도까지 진행이 된 것으로 확인이 되네요.
데이터 세트에서 챌린지는 매년 개최되고 그 해의 결과와 방법을 비교하고 논의하기 위해 워크숍을 개최한다고 합니다. 또한 데이터 세트와 관련 주석 및 소프트웨어는 이후에 릴리즈 되어 언제든지 사용할 수 있다고 하네요. 덕분에 쉽게 데이터 세트들을 사용할 수 있는 듯 합니다. 이러한 챌린지의 목표는 표준 평가 방법론과 함께 이미지와 고품질 주석을 제공하는 것과 "plug and play" 방식의 train 및 test 도구를 통해 알고리즘의 성능을 비교할 수 있도록 하며, 매년 SOTA 급 기술의 성능을 측정하도록 합니다.
Challenge Tasks
1. Classification
“does the image contain any instances of a particular object class?”
이미지에 특정 객체 클래스의 인스턴스가 포함되어 있습니까? (여기서 객체 클래스에는 자동차, 사람, 개 등이 포함됨)
20개의 객체 클래스 각각에 대해 테스트 이미지에서 해당 클래스의 객체가 하나 이상 존재하는지 부재하는지를 예측합니다. 참가자들은 precision / recall 곡선을 그릴 수 있도록 이미지에 대해 물체의 존재에 대한 실제 값의 신뢰도를 제공합니다. 또한 "cars only" 또는 "motorbikes and cars" 와 같이 객체 클래스의 전체 또는 일부를 다루도록 선택이 가능 합니다.
2. Detection
“where are the instances of a particular object class in the image (if any)?”
이미지에서 특정 객체 클래스의 인스턴스는 어디에 있습니까?
20개의 클래스 각각에 대해 GT 신뢰도와 함께 테스트 이미지에서 해당 클래스의 각 객체의 경계 상자를 예측합니다. 참가자들은 객체 클래스의 전체 또는 일부를 처리할 수 있도록 선택할 수 있습니다. Classification 챌린지 방법과 유사합니다.
3. pixel-level segmentation
“tasters” : 각 픽셀에 클래스 레이블을 할당하고
“person layout” : 이미지에서 사람의 머리, 손, 발을 localization 합니다.
Segmentation Taster
각 테스트 이미지에 대해 각 픽셀의 객체 클래스를 예측 하거나 객체가 지정된 20개 클래스 중 하나에 속하지 않는 경우 "background"를 예측합니다. Classification 및 Detection 챌린지와는 달리 학습 데이터가 챌린지에서 제공하는 데이터로 제한되는 하나의 챌린지만 있습니다.
Person Layout Taster
테스트 이미지의 각 "person" 객체에 대해 사람을 검출하고 사람의 경계 상자, 그리고 각 머리/손/발 유무 및 해당 신체 부위의 경계 상자를 예측합니다. 각 사람 검출 상자는 연관된 실제 confidence 로 출력되어야 합니다.
Datasets
VOC 챌린지의 목표는 광범위한 natural image 에 대한 인식 방법의 성능을 조사하는 것 입니다. 이를 위해 VOC 데이터 세트는 객체 크기, 방향, 포즈, 조명, 위치 및 폐색 측면에서 상당한 가변성을 포함해야 합니다. 데이터 세트가 예를 들어 중앙에 객체가 있거나 좋은 조명이 있는 이미지를 선호하는 등의 체계적인 편향을 나타내지 않는 것도 중요합니다. 마찬가지로 정확한 학습과 평가를 보장하기 위해 이미지 주석이 지정된 클래스에 대해 일관되고 정확해야하며 철저해야합니다.
개인적으로 이 내용을 읽고 어떠한 데이터 세트를 구축할 때 이 데이터 세트로 모델의 성능을 객관적으로 평가한다고 생각하고 대상 객체에 대해 다양한 데이터가 포함되어있는 데이터를 만들면 좋을 것 같다는 생각이 듭니다. 평가 측면에서 또는 학습 측면에서 데이터 세트를 만들 때 다양한 데이터들을 주입 시켜주는 것은 역시나 동일한 맥락이 아닐까 싶습니다. 🙋
VOC 데이터 세트의 이미지 수집은 flicker 라는 사진 공유 웹사이트에서 여러 관련 키워드를 쿼리하여 수집되었다고 합니다. 비전 또는 머신러닝 연구자가 촬영하지 않은 사진 즉 다른 개인이 촬영한 사진을 사용하면 특정 목적을 염두해두고 찍은 것이 아니기 때문에 "편향되지 않은" 데이터 세트가 생성될 수 있기에 이러한 방법을 채택했다고 합니다.
제가 예전에 구글 이미지를 크롤링 할 때 특정 키워드를 고정해놓고 크롤링 했던 것이 생각이 나네요. 키워드를 잘 설정하는 것도 데이터 수집을 위한 팁 같습니다. 그런 측면에서 구글의 연관 검색어 추천은 키워드를 설정하는데 많은 도움이 되었던 기억이 납니다.
이 논문에서도 의자, 소파, 테이블 등이 포함된 쿼리 또는 자동차, 오토바이, 보행자 등의 포함된 장면을 반환하는 쿼리를 작성하기 위해서 "town center" 나 "party" 라는 키워드를 사용했다고 합니다. 저 같으면 "IKEA" 를 검색할 것 같습니다. 🤩 그리고 중복 및 중복에 가까운 이미지들을 제거하고, annotator 에게 500,000장의 이미지가 주어졌으며, annotation event 동안 44,269장의 이미지에 대해 주석이 달렸다고 합니다.

또한 이미지 수집 과정에서 한 가지 작은 편향이 발견되었는데 "recency" 순으로 순위가 매겨진 쿼리 결과를 사용했는데, 그 당시 2007년 1월에 수집이 진행되어 크리스마스 트리가 포함된 겨울 이미지 수가 많았다고 합니다. VOC2008에서는 이러한 편향을 피하기 위해 키워드와 함께 임의의 날짜를 포함하는 쿼리를 이용하여 이미지를 검색했다고 합니다. 상당히 흥미롭네요. 우리나라에서 이미지를 수집 할 때는 사계절 별로 나눠서 수집하면 좋을 듯 합니다.
Choice of Classes
다음 그림 2는 VOC2007 데이터 세트에서 20개의 클래스를 보여줍니다. 그림에서 볼 수 있듯 클래스는 vehicles, animals, household objects 및 peoples 의 네 가지 주요 객체로 나눠집니다.
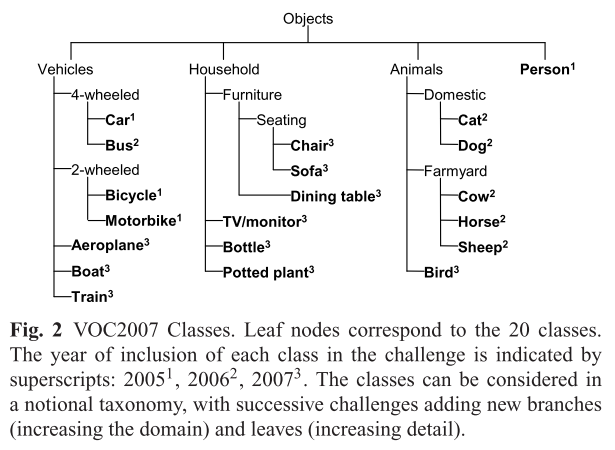
또한 특정 클래스가 포함된 챌린지 연도를 보여주기도 하네요. VOC2005 챌린지에서는 4가지 클래스(자동차, 오토바이, 자전거 및 사람)에 주석이 추가되었고, VOC2006에는 클래스의 수가 10으로 VOC2007에는 20으로 증가했다고 합니다. 추후 데이터 세트는 더 미세하게 "sub-classes"가 추가 되었습니다. sub classs를 나누는데 있어서 먼저 "semantic"한 요소를 고려했다고 합니다. 예를 들면 다양한 유형의 차량을 인식하는 것과 같이 자동차/오토바이(시각적으로 유사하지 않을 수 있음), 시각적으로 유사한 것으로 간주될 수 있는 객체(e.g. cat 과 dog)를 포함하여 recognition 의 작업 난이도를 높였습니다. 그 다음으로는 notional taxonomy를 고려하여 나누었다고 합니다. VOC2006 에서는 animals 이 추가되었고, VOC2007에서는 household objects 가 추가되었다고 합니다.
Annotated Attributes
분류 및 검출 문제를 평가하기 위해 이미지 주석에는 대상 객체 클래스 세트의 모든 객체에 대해 다음 속성이 포함됩니다.
- class one of : aeroplane, bird, bicycle, boat, bottle, bus, car, cat, chair, cow, dining table, dog, horse, motorbike, person, potted plant, sheep, sofa, train, tv/monitor
- bounding box : an axis-aligned bounding box surrounding the extent of the object visible in the image.
그리고 train 에서는 고려될 수 있지만 evaluation 에서 필요하지 않은 요소는 다음과 같습니다.
- viewpoint : 앞, 뒤, 왼쪽, 오른쪽, 지정되지 않음 중 하나
- truncation : 이미지의 경계 상자 영역이 객체의 전체 범위와 일치하지 않을 때, 즉 잘린 경우.
VOC2008 챌린지에서는 폐색(occlusion)이 있는 경우 "occluded" 라는 주석이 포함되어 있다고 합니다. 또한 difficult 라는 주석이 포함되기도 합니다. 평가에서 그러한 객체는 폐기 되지만 detection 에 대한 페널티는 발생하지 않는다고 하네요.
- difficult : 작은 크기, 조명, 이미지 품질 또는 중요한 맥락 정보를 사용해야 하기 때문에 검출이 어려운 대상이라고 판단될 경우 difficult 레이블을 지정하게 됩니다. difficult 예시는 아래 사진과 같습니다.

Image Annotation Procedure
주석을 지정하기 위해서는 클래스를 정의하고, 경계상자 배치를 어떻게 할 것인지 결정하고, Viewpoint 및 truncation 을 어떻게 정의할 것인지 결정하여 이미지의 주석이 일관되도록 합니다. "accurate" 및 "exhausitive" 하게 주석을 만듭니다. 또한 주석을 만드는데 있어서 주석의 정확성을 보장하기 위해 식별이 어렵다고 판단되는 사물에는 "difficult" 라벨을 달았다고 합니다.
Dataset Statistics
다음 표는 VOC2007 데이터 세트의 통계를 요약해두었습니다.
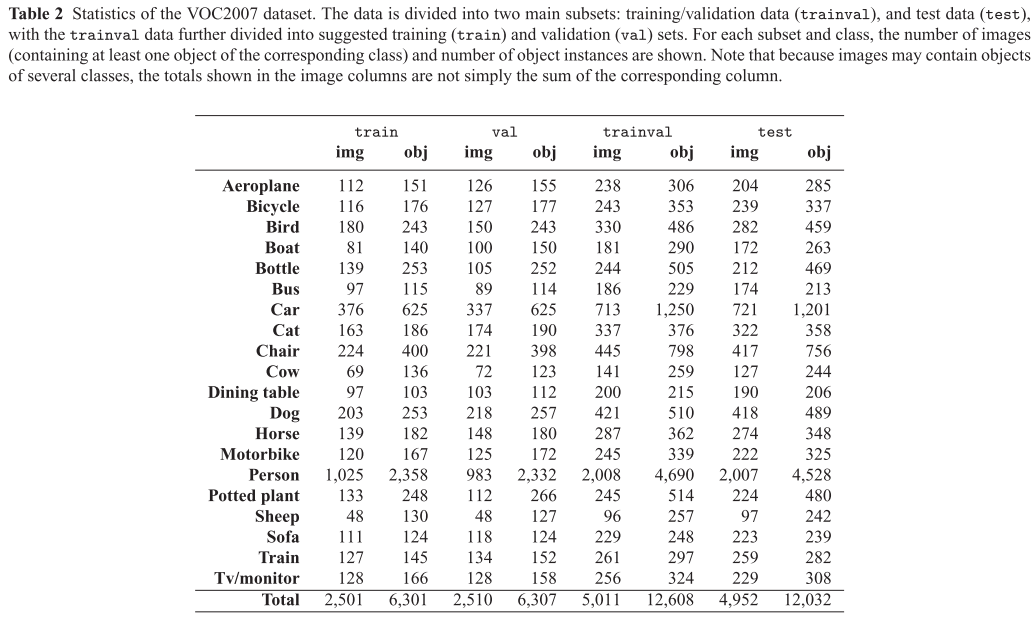
챌린지를 위해 데이터는 train/valid = tranval 와 테스트(test) 데이터 두 가지로 나뉩니다. 주석이 달린 이미지의 총 수는 9,963개로 VOC2006 데이터의 양인 5,304장 보다 약 2배 정도 라고 합니다. 주석이 달린 객체의 수도 9,507개에서 24,640개로 증가했다고 합니다. 클래스가 10개에서 20개로 두배로 늘었기 때문에 각 클래스의 평균 객체 수는 951개에서 1,232개로 약간 증가했으며 주석이 있는 사람의 수는 4배 증가했다고 합니다. (데이터세트를 만들 때 각 클래스 당 객체 수를 일정하게 맞추는 것도 참 중요한 것 같습니다.) person 클래스는 9,218개의 인스턴스가 있는 반면 dining table 같은 경우 421개 정도, 자동차는 2,421개 정도라고 합니다. person 클래스를 학습 시키기에는 좋은 데이터 세트 같습니다. flickr 통해서 이미지를 수집할 당시 "sheep" 및 "bus" 클래스는 이미지 부족으로 인해 수집이 어려웠다고 합니다.
Taster Competitions
Segmentation 챌린지를 위해 주요 데이터 세트의 이미지 하위 집합에 포함된 모든 객체의 visible region 에 대해 pixel-level segmentation으로 주석을 달았습니다. 이러한 segmentation은 bounding box를 개선하는 역할을 하여 정확한 shape 및 localization 정보를 제공하게 됩니다. 완벽한 픽셀을 따서 주석을 만드는 것은 매우 시간이 많이 드는 작업이기 때문에 이러한 점을 고려하여 픽셀에 객체도 배경도 아닌 레이블이 지정된 각 객체 주변에 5픽셀 너비의 테두리 영역이 허용되었다고 합니다. 그림 5a 에 설명되어 있습니다.
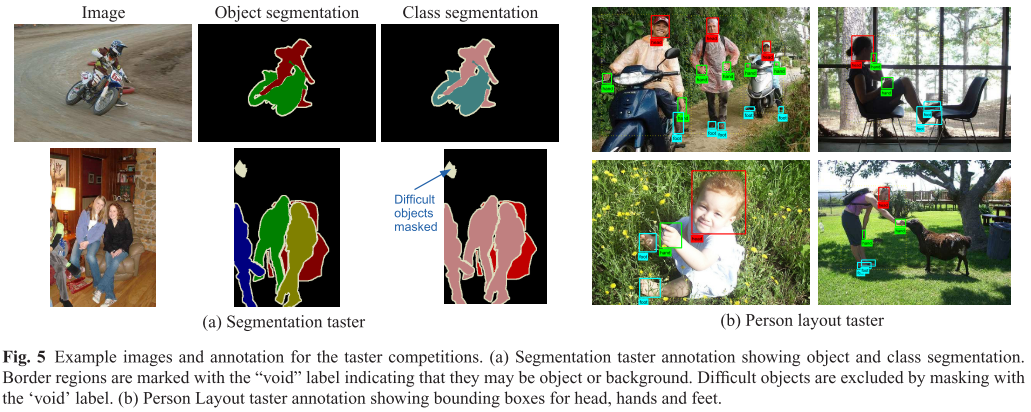
Person layout
person layout 챌린지의 경우 각 주요 데이터 세트에 있는 "person" 객체의 하위 집합에 사람의 2D 포즈 또는 "layout"에 대한 정보가 주석이 됩니다. 각 사람에 대해 머리, 손, 발 세가지 유형의 "part"에 경계 상자가 추가 됩니다. 그림 5b 를 보시면 됩니다. 이는 사람의 전반적인 자세에 대한 좋은 근사치를 제공하기 위해 선택되었다고 합니다.
Submission and Evaluation
VOC2007 챌린지의 실행은 두 단계로 구성됩니다. 챌린지가 시작될 때 참가자들은 주석이 포함된 train/val 이미지로 구성된 development kit 와 주석을 사용할 수 있는 MATLAB 소프트웨어를 참가자에게 제공한다고 합니다. LabelMe와 함께 평가 측정을 계산하고 각 competition 에 대한 간단한 구현들을 포함합니다. 두번째 단계에서는 주석이 없는 test 이미지가 배포됩니다. 그 다음 참가자들은 테스트 데이터에 대한 방법들을 실행하고 섹션에 정의된 대로 결과를 제출해야 한다고 합니다.
Evaluation of Results
VOC2007과 같은 multi-class dataset 에 대한 평가는 classification 과 같은 경우 이미지에는 multi-class 의 인스턴스가 포함되므로 이 이미지에 포함된 m개의 클래스 중 하나는 무엇인가에 대한 물음이 제기될 수 있습니다. 또한 클래스에 대한 사전 분포가 상당히 균일하지 않기에 간단한 정확도 측정이 적절하지 않습니다.
classification 및 detection은 모두 20개의 독립적인 작업 세트로 평가 됩니다. 분류에 대해서는 "이미지에 자동차가 있느냐?" 그리고 검출 문제에 대해서는 "이미지에 자동차가 어디에 있느냐?"를 평가하게 됩니다. 각 클래스에 대해 별도의 "score"가 계산되며 분류 작업의 경우 참가자들은 각 이미지와 각 클래스에 대한 confidence level의 형태로 결과를 제출하며, 값이 클수록 이미지에 관심 대상이 포함되어있다는 confidence 가 크다는 것을 말합니다. 검출 작업의 경우 참가자들은 각 검출에 대한 경계 상자들을 제출하며, 각 경계 상자에 대한 confidence 들을 제출합니다. 이러한 score 들은 false positives 및 false negatives 간의 trade-off 를 평가할 수 있도록 계산됩니다.
바로 흔히들 알고 계시는 AP(Average Precision) 입니다. VOC2007 챌린지의 경우 interpolated average precision을 사용하여 평가한다고 합니다. 무엇인지는 넘어가도록 하겠습니다. 또한 경계 상자를 평가함에 있어서 GT 상자와 예측된 상자의 중첩 영역을 계산하여 평가하게 됩니다.
Evaluation of the segmentation taster
segmentation과 같은 경우는 올바르게 레이블이 지정된 픽셀의 백분율을 계산하여 평가하게 됩니다.

Evaluation of the person layout taster
person layout 같은 경우는 AP 측정을 사용하여 모든 part 들에 대해 올바르게 경계 상자 영역이 설정되어 있는지를 평가하게 됩니다.
Method & Results
이 섹션 같은 경우는 결과를 참고만 하는 것이 좋을 것 같다고 판단되어 간략히만 읽었습니다. 🙂

Discussion and the Future
마지막으로 이 논문에서 주장하고 있었던 여러 Discussion 및 향후 고려해야할 것들에 대해 말하고 있었는데요, 향후 고려해야할 점에서 언급했던 것들 중 가장 인상적이었던것은 다음과 같습니다.
More object classes
VOC 데이터 세트를 확장시키기 위해서는 주석이 달린 객체 클래스를 늘려야합니다. 여기서 주요 목표는 확정성 문제에 더 중점을 두는 것입니다. 객체 클래스가 있는 만큼 검출기를 만드는 것이 가장 많이 접근하고 있는 방식이지만 추후에는 그렇지 않을 수 있습니다. 예를 들어 클래스 간에 feature 를 공유하거나 여러 "parent" 클래스의 속성을 이용하는 등 detection schemes의 다양한 측면이 중요해질 수 있습니다. 더 많은 클래스들을 도입하면 시각적으로 더 유사한 클래스 간의 구별에 대한 연구와 클래스 간의 의미론적인 관계를 활용하는 연구도 촉진될 것입니다.
그러나 클래스 수를 늘리는 것은 VOC 챌린지에 어려움을 야기할 수도 있습니다. 먼저 클래스 당 충분한 데이터를 수집하는 것이 어렵습니다. 객체에 정확하게 주석을 달 때 "van" 이나 "truck"으로 레이블을 지정하는 것에 대해 주관적으로 라벨링을 할 수 있기 때문입니다. 또한 recognition 에 대한 평가는 더 유연해야합니다. 예를 들어 hatchback, car, vehicle의 클래스를 할당하고 정확도 또는 세부적인 수준에 따라 다양한 "scores"를 할당할 수 있습니다.
Object parts.
VOC2007은 객체의 위치 보다 더 자세한 body parts를 도입했습니다. 이와 같이 객체의 부분을 보다 자세하게 표시하는 것은 추후 추구해야할 중요한 방향입니다. (물론 이 당시에 적용되는 말 같습니다.) 추후 객체 탐지와 인식의 목적은 객체와의 상호작용을 지원하는 것입니다. 객체의 위치를 잘 이해하는 것은 사물 인식을 실용적으로 사용하는데 필요하기 때문에 평가 체계의 구성요소에 통합되어야 된다고 생각합니다. 지금까지 VOC는 "discrete" 객체를 식별할 수 있는 객체 클래스 및 주석으로 제한되어왔습니다. segmentation 의 taster 의 도입으로 "stuff" 클래스(잔디, 하늘 등)도 포함하고 추가로 "stuff"로 나타날 수 있는 클래스의 주석을 고려하는 것은 자연스러운 듯 합니다. 또한 "person" vs "crowd" 이러한 모호성을 포함하는 이미지는 VOC 데이터세트에서는 고려하지 않습니다.
Beyond nouns.
점점 더 비전 연구자들은 텍스트 분석 결과를 연결하고 WordNet 과 같은 영역에서 나오는 도구들을 활용하고 있습니다. 이러한 방향은 장면에 대한 텍스트 설명을 활용 또는 생성할 수 있는 비전 시스템을 구축하기 위함입니다. 이러한 방향을 위해서는 actions(verbs) 및 attributes(adjectives and adverbs)과 관련하여 object(nouns)를 가져오는 것을 수반하게 됩니다. 즉 "명사 + 위치" 조합의 출력 보다 장면에 대해 더 풍부한 텍스트 설명을 생성하는 방법에 대해 벤치마크를 도입하는 것이 적절할 것입니다.
Scene dynamics.
지금까지 VOC의 문제는 still images 에서 객체를 분류하고 감지하는데 전적으로 초점을 맞추었습니다. 비디오 클립을 포함하면 다음과 같은 여러가지 방법으로 문제를 확장 할 수 있습니다.
1. training data로 3D 또는 multi-aspect 과 같은 더 풍부한 객체 모델 학습을 지원 할 수 있습니다.
2. test data로 비디오의 객체 인식 및 동작 인식과 같은 새로운 task 를 평가할 수 있습니다.
Alternative annotation methods.
수동으로 주석을 다는 것은 시간과 비용이 들게 됩니다. 특히 비디오 task가 추가되는 경우 주석을 다는 방법은 주석 자체와 함께 발전해야 합니다.
The future is bright.
지난 10년 간 객체 클래스 인식에 엄청난 발전이 있어왔습니다. millennium으로 접어들었을 때 자전거, 소, 양과 같은 다양한 객체 클래스에 대한 분류 및 검출 모두에서 인상적인 성능을 발휘할거라고 꿈꿨던 사람은 거의 없을 것 같습니다. VOC 챌린지는 이러한 발전에 중요한 역할을 했으며 앞으로도 계속 그렇게 되기를 바랍니다.


무려 references를 제외하고도 33 페이지나 되는 논문을 읽어보았습니다. 모든 내용을 읽어보지는 못했지만, VOC 데이터세트를 만들었던 사람들이 그간 얼마나 고생했는지와 얼마나 데이터 세트를 만드는데 고심했을지 고스란히 느껴졌던 논문이였습니다. 이러한 휼륭한 데이터 세트들이 오픈되어 있기 때문에 기술이 발전하는게 아닌가 싶습니다. 새삼 또 감사히 느껴집니다. ☺️
Paper : https://homepages.inf.ed.ac.uk/ckiw/postscript/ijcv_voc09.pdf
Project page : http://host.robots.ox.ac.uk/pascal/VOC/
The PASCAL Visual Object Classes Homepage
2006 10 classes: bicycle, bus, car, cat, cow, dog, horse, motorbike, person, sheep. Train/validation/test: 2618 images containing 4754 annotated objects. Images from flickr and from Microsoft Research Cambridge (MSRC) dataset The MSRC images were easier th
host.robots.ox.ac.uk