[Pose Estimation] Google Research의 MoveNet API

Google Research에서 TensorFlow.js 로 경량화된 자세 추정 모델인 MoveNet의 API를 공개하였습니다. 랩탑 환경에서도 30FPS 이상 달성한다고 합니다. 참고로 이를 기반으로 홈트레이닝 분야에 적용을 한 국내 논문 "딥러닝 기반 영상처리 기법 및 표준 운동 프로그램을 활용한 비대면 온라인 홈트레이닝 어플리케이션 연구"도 있네요.
MoveNet은 17개의 keypoint를 감지하는 모델이며, 정확도에 초점을 맞춘 Thunder 버전과 속도에 초점을 맞춘 Lightning 버전을 제공하고 있습니다. 또한 JS 모델과 TF모델 및 TFLite모델(+ float16, int8)들을 제공하고 있습니다. 서버 호출 없이도 TensorFlow.js를 사용하는 브라우저에서 모델을 실행할 수 있다고 합니다. 라이브 데모를 한번 실행해보았습니다.
https://storage.googleapis.com/tfjs-models/demos/pose-detection/index.html?model=movenet
https://storage.googleapis.com/tfjs-models/demos/pose-detection/index.html?model=movenet
storage.googleapis.com




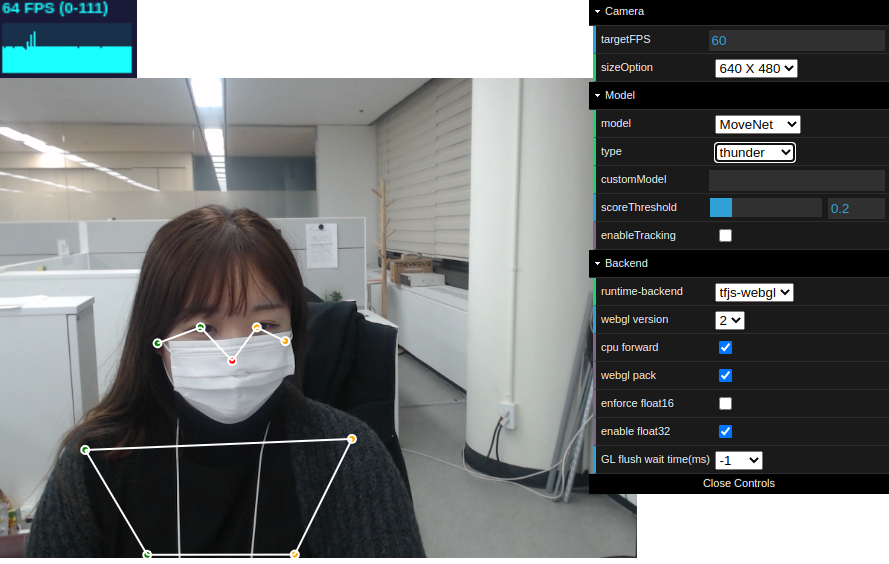

Lightning 버전은 Occlusion 발생하기 쉽게 앉아있으면 포즈 값이 이리저리 튀는 현상이 있습니다. RTX 2080 환경에서 64~81 FPS 정도 달성하네요. 매우 빠르지만 정확도는 낮은편 입니다. Thunder 버전은 Occlusion 발생하기 쉽도록 앉아있어도 포즈 값이 정확하게 검출되는 결과를 보이고 있습니다. 포즈 값이 튀는 것도 Lightning 버전 보다는 적구요. FPS는 60~65 정도네요. Multipose 모드도 있었는데 사무실에서 혼자 테스트 하고 있었어서 테스트는 제대로 못했습니다. Pose 관련된 API를 이용하여 활용할 수 있는 영역은 무궁무진 한 듯 합니다.
MoveNet은 Bottom-up 방식의 포즈 추정 모델이라, 사람 검출기가 필요하지 않습니다. Step 하나를 줄이니 속도 측면에서도 이득이 많았을 듯 합니다. 모델은 feature extractor 와 prediction heads 로 구성됩니다. CenterNet을 루즈하게 따른다고 하네요. 특징맵 추출은 FPN으로 수행하고 백본은 MobileNet v2 라고 합니다. 4개의 prediction head 는 사람 중심을 나타내는 히트맵, keypoint regression하는 부분, keypoint heatmap, keypoint 별 Local 2D Offset을 예측한다고 합니다.
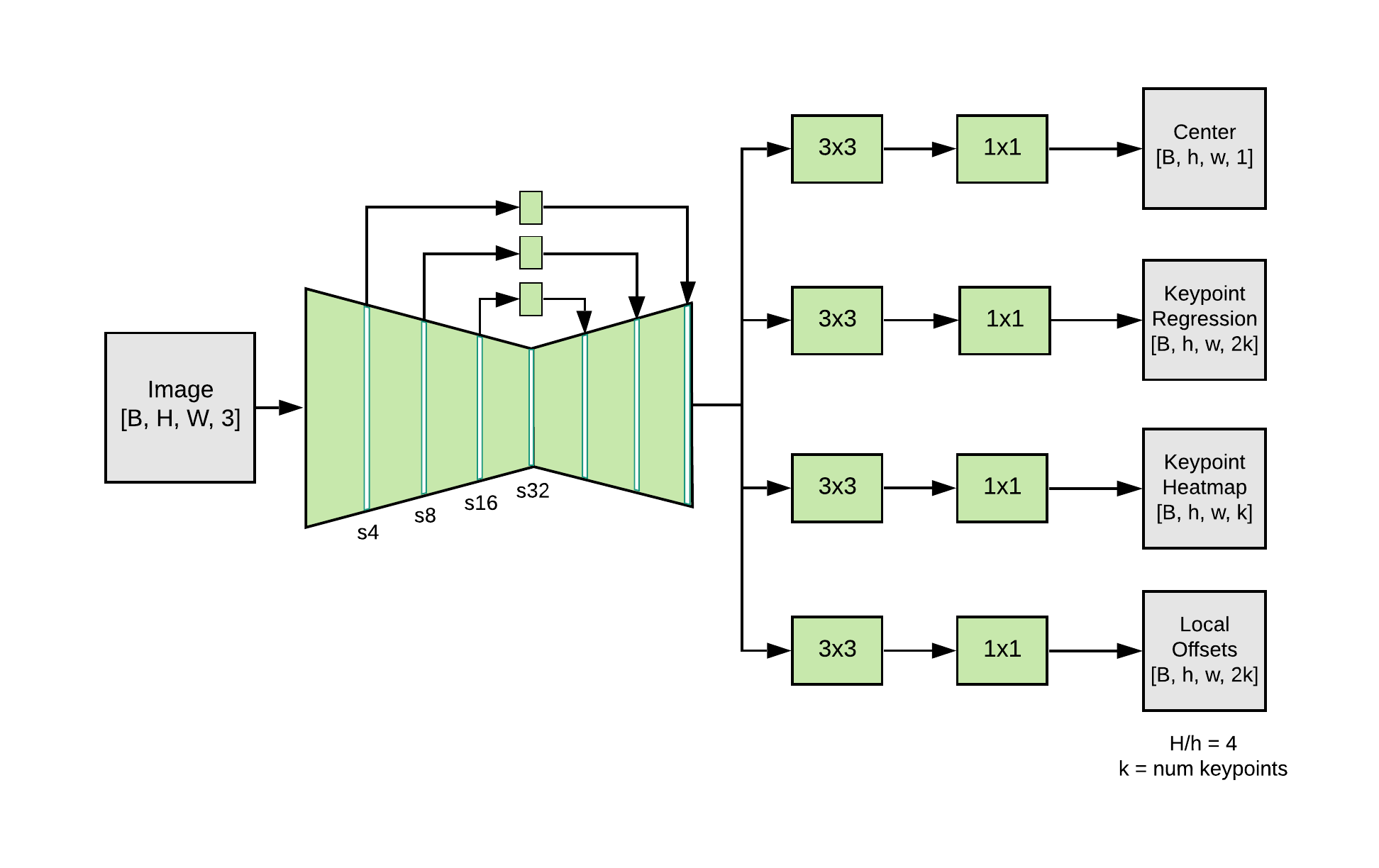
MoveNet은 아래와 같이 진행된다고 합니다.
1. person center heatmap은 프레임에 있는 object의 중심 부분을 식별하는데 사용되며, 사람에 속한 모든 keypoint의 산술평균(the arithmetic mean)로 정의된다. 프레임 중심으로부터 inverse-distance가 가중되어 히트맵에서 가장 높은 score에 있는 지점(peak)을 localization 하게 됩니다.
2. peak center location 에서 keypoint regression vector 를 slice 하여 초기 keypoint 세트를 생성합니다. 이 때는 서로 다른 scale 에서 center prediction이 수행되기 때문에 품질이 정확하지 않습니다. 대략적인 추출이라고 보시면 됩니다.
3. keypoint heatmap의 각 픽셀에 회귀된 keypoint로부터 거리에 반비례하는 가중치를 곱합니다. 이렇게 하는 이유는 background에 있는 사람들로부터 keypoint를 추출하지 않기 위함입니다. 회귀된 keypoint에 그들이 근접해 있지 않기 때문에 이는 low resulting scores를 달성합니다.
4. 각 keypoint channel로 부터 추출된 maximum heatmap values의 좌표들을 추출하여 최종 keypoint를 산출하게 됩니다. 그 다음 local 2D offset prediction이 이러한 좌표에 추가되어 정제된 결과를 제공하게 됩니다.

MoveNet은 COCO와 Active 라는 내부 데이터 세트에서 학습되었다고 합니다. COCO는 표준 벤치마크 데이터세트이긴 하지만 challenging poses and significant motion blur 가 포함되어있기 때문에 피트니스나 댄스 어플리케이션에는 적합하지 않다고 하네요. 매우 동감하는 바입니다. Active 라는 데이터세트는 유튜브의 요가, 피트니스, 댄스 영상에 키포인트를 라벨링하여 제작했다고 합니다. 장면과 개인의 다양성을 보장하기 위해 각 비디오에서 3개 이하의 프레임만 선택하여 학습했다고 합니다. 대단하네요. 아래 그림은 Active keypoint Dataset 입니다. 이제 각 기업에서 특정 서비스(도메인)을 위해 생성한 데이터세트는 정말 고유하고 소중한 자산인 듯 합니다.

이를 최적화 하기 위해서 Depthwise separable conv는 MobileNet v2에서 첫번째 레이어를 제외하고 네트워크 전체에서 사용되었다고 합니다. 또한 tf.math.argmax로 tf.math.top_k가 대체되었다고 합니다. 가장 중요한 속도향상 요인은 192x192 입력을 사용하는 것 이라고 합니다. Thunder의 경우 256x256이라고 하네요. 이전 프레임으로부터 intelligent cropping based on detections 을 적용하였다고 합니다. 이는 주요 객체에 대해 attention 효과를 지닌다고 합니다. (background의 영향을 줄이기 위함) 이런 디테일한 요소까지 공개하고 있는 것을 보니 친절하고 감사하네요.
또한 Temporal Filtering을 수행하여 키포인트 추정 결과를 스무딩 시켰다고 합니다. 저도 비슷한 스무딩을 적용시켜본 경험이 있는데 이게 가시적인 결과를 더 부드럽게 만들어줘서 자연스러운 포즈 추정이 가능하게 되더라구요.
그리고 웹 환경에서 구동하기 위해서 WebGL을 사용했다고 합니다. WebAssembly 기반인듯 합니다. 사실 이 최적화가 없었다면 웹에서 이정도 성능으로 구동하는게 불가능했을 듯 합니다. WebGL은 필수인 듯 합니다. 또한 depthwise conv 를 WebGL에서 구동하기 위한 커널 함수는 포즈 추정 아닌 분야에서도 유용하게 사용될 듯 합니다.
참고자료 1 : https://smilegate.ai/2021/05/20/movenet-a-javascript-pose-estimator/
MoveNet: A JavaScript pose estimator | Smilegate.AI
Pose estimation은 시각 처리 기술 중 하나로 영상 내 등장인물의 움직임을 추적하는 기술입니다. 보통 facial landmark와 유사한 방식인 body landmark를 추출하고 이들을 연결함으로써 몸 전체의 자세를 묘
smilegate.ai
Next-Generation Pose Detection with MoveNet and TensorFlow.js
MoveNet is a human pose detection architecture developed at Google that is ultra fast and accurate. It was designed to detect difficult poses
blog.tensorflow.org