

한빛미디어에서 출간된 머신러닝 실무 프로젝트(2판) 책은 기존 내용에 MLOps 및 슬롯머신 알고리즘을 활용한 강화학습 등의 내용을 추가하여 2판을 출간했다고 한다. 1장에서는 머신러닝을 어떻게 프로젝트에 적용하는지에 대해 배우며, 머신러닝 프로젝트 진행과정을 다음과 같이 명료하게 나누어 두었다.
1. 비즈니스 문제를 머신러닝 문제로 정의
2. 논문을 중심으로 유사한 문제들을 조사
3. 머신러닝을 사용하지 않는 방법은 없는지 검토
4. 시스템 설계를 고려
5. 특징량, 훈련 데이터와 로그를 설계
6. 실제 데이터를 수집하고 전처리
7. 탐색적 데이터 분석과 알고리즘을 설정
8. 실제 데이터를 수집하고 전처리
9. 시스템 통합
10. 예측 정확도, 비즈니스 지표 모니터링
머신러닝 엔지니어들은 이미 머신러닝이 도입되어야 한다고 정의되어있는 문제라면 데이터 파이프라인을 구축하고, 전처리, 모델 서빙 등을 해야한다. 인공지능 업계에서 유명한 사람들 중 하나인 Andrew Ng은 최근 온라인 컨퍼런스에서 MLOps의 중요성에 대해 설명하면서, 이제는 모델 중심적 사고에서 벗어나서 MLOps와 Data에 집중해야된다고 하였다. 그만큼 머신러닝에 있어서 문제를 잘 정의하고, 알고리즘을 잘 설계하는 것도 중요하지만, 데이터도 그만큼 중요하다고 생각된다.
이러한 관점에서 "머신러닝 실무 프로젝트" 책은 머신러닝으로 할 수 있는 일에 대해 명료하게 알려주는 것 부터 시작하여, 머신러닝과 관련된 다양한 개념들, 평가 방법, 기존 시스템에 머신러닝을 통합하는 과정, 학습 리소스 수집하는 방법, 지속적인 머신러닝 활용을 위해 기반을 구축하는 방법, 머신러닝 기반 정책 성과를 판단하는 방법 등을 배우며 실전에 필요한 갖가지 방법들에 대해 배울 수 있게 도와준다.
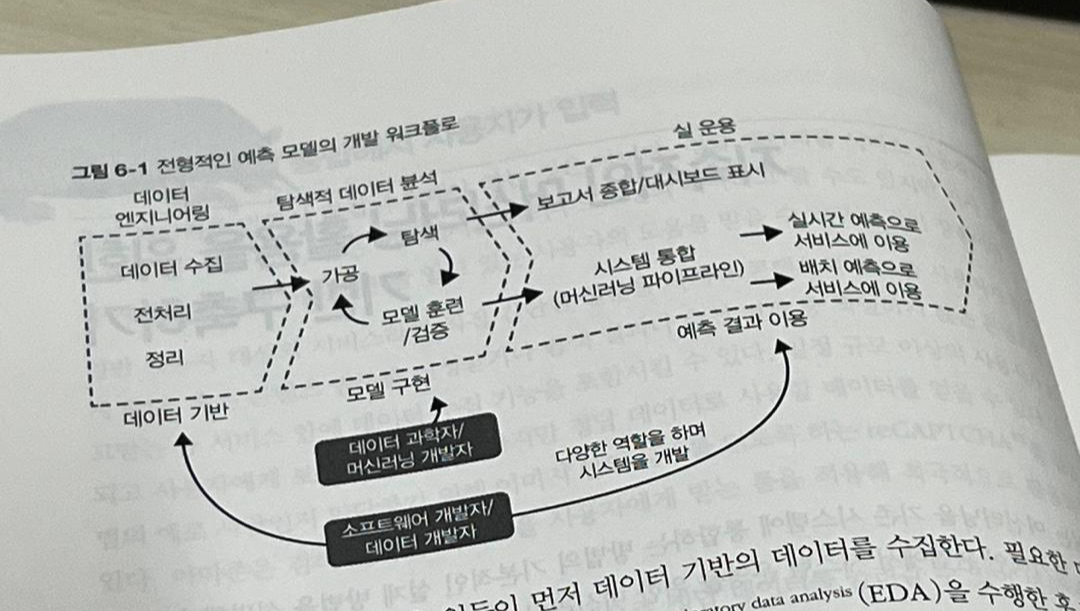
이 책에서 가장 흥미로웠던 내용은 장기적인 관점에서 시스템 운영을 위한 머신러닝 인프라를 구현해야할 때 고려사항이였다. 머신러닝 시스템을 개발할때 어려움은 크게 세가지가 있는데 그 중 첫번째인 "데이터 과학자 vs. 소프트웨어 개발자"와 관련된 내용이 눈길이 제일 먼저 갔다. 전형적인 예측 모델의 개발 워크플로 그림을 보면, 데이터 과학자 또는 머신러닝 개발자가 모델 개발 영역을 담당하며, 개발 및 운영은 소프트웨어 개발자나 데이터 과학자가 담당하게 된다. 이와 같이 머신러닝 업무에서는 데이터 과학자와 소프트웨어 개발자가 함께 작업하게 되는데 관련된 내용은 아래와 같다.
또한 데이터 과학자는 분석가 또는 연구원 출신이기 때문에 소프트웨어 개발 지식이나 경험이 많지 않다. 데이터 과학자는 파이썬이나 R 같은 스크립트 언어를 선호하며 깃을 사용한 버전 관리나 단위 테스트에는 익숙하지 않다. 또한 데이터 과학자의 KPI는 분석 결과에서 도출한 후 액션이나 높은 정확도의 예측 모델을 사용한 매출 개선 등이며, 익숙한 도구를 자유롭게 사용하여 가장 짧은 기간에 결과를 내는 것이며, 빠른 반복 주기의 시행착오를 중시하는 반면 유지보수성이나 재사용성이 높은 코드를 만드는 것은 우선순위가 낮다고 한다.
반면 소프트웨어 개발자는 시스템이 운영환경에서 잘 운영되도록 개발하는 것을 중시한다. 데이터 과학자가 만든 예측 모델에서 얻은 결과를 안정적으로 서빙하고 시스템이 고장나지 않는 것이 우선순위가 높다. 머신러닝 개발 과정 중 생성되는 모델이나 데이터가 많은데, 이를 안전하게 배포하려면 복잡한 파이프라인 관리나 학습 완료된 모델의 검증을 해야한다. 만들어진 예측 모델이 100%의 정확도를 가지고 안정적으로 예측 결과를 반환할 가능성은 없다. 따라서 시스템에는 어떤 방식으로든 사람이 개입하게 되어 소프트웨어 개발자는 플랫폼에서 동작하는 예측 모델을 사람이 확인하기 쉽도록 설계하는 것 역시 중요하다고 한다.
이 글을 읽으면서 개인적으로 든 생각은 데이터 엔지니어링, 예측 결과를 이용한 실 운용 부분은 소프트웨어 개발자나 데이터 개발자가 담당해주고, 모델을 가공하고, 학습하는 일들은 데이터 과학자나 머신러닝 개발자가 담당해준다면 정말 효율적으로 머신러닝 모델을 개발할 수 있을 것 같다. 각자 자신이 잘 할 수 있는 일을 집중해서 하는 것이 가장 중요하다고 생각한다. 또한 머신러닝 개발자가 소프트웨어 지식을 어느정도 갖추고 있거나, 소프트웨어 개발자가 머신러닝에 관련된 지식을 조금 갖추고 있으면 베스트 일 것 같다. 과연 국내에 이런 체계를 갖추고 머신러닝 모델을 만드는 회사는 과연 몇이나 될까 궁금하다.
머신러닝 시스템을 개발할 때 어려운 문제중 두번째 문제는 동일한 결과를 예측하기 어렵다는 것이다. 머신러닝 예측 모델은 주어지는 데이터에 따라 변화한다. 데이터도 끊임없이 변한다. 그렇기 때문에 머신러닝 시스템에서는 조금이라도 변경되면 시스템 전체의 행동이 바뀌는데 이 특성을 CACE(change anything, change everything) 원칙이라고 한다. 이에 적극 동의하는 바이다. 많은 사람들이 이 책을 보고 데이터가 많으면 많을 수록 당연히 정확도가 높아질 것이라고 생각하지 않았으면 좋겠다.
세번째 문제는 지속적인 학습과 서빙의 필요성이라고 한다. 학습이 완료된 모델을 계속 사용하려면 학습 시와 예측 시의 입력 데이터 분포가 크게 달라지지 않아야 하며, 입력 데이터에서 사용할 수 있는 특징량이 일치하며 그 양도 충분하다는 가정이 필요하다. 하지만 장기간 이용하는 머신러닝 시스템은 대부분 두 가지 가정을 만족하지 못한다. 새로운 데이털를 활용해 예측 모델을 지속적으로 업데이트 해야한다. 따라서 자동으로 재학습을 하여 제공하는 지속적인 학습(Continuous Training)이 중요하다고 한다.
이 책은 머신러닝 프로젝트를 수행하기 위해 알아야할 기본 지식, 머신러닝으로 할 수 있는 일과 다양한 알고리즘, 컴퓨터 시스템에 머신러닝 구조를 통합하는 주요 패턴, MLOps, 업리프트 모델링을 사용하여 효과적인 마케팅을 수행하는 방법 등의 내용을 담고 있다. 즉, 한마디로 말하자면 머신러닝 프로젝트를 성공적으로 수행하기 위한 실무적인 모든 것을 담고있으므로 머신러닝 프로젝트를 수행하는 사람이라면 한번쯤 정독하면 좋을 것 같다!
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
'Book Review' 카테고리의 다른 글
| [Book Review] 똑똑한 코드 작성을 위한 실전 알고리즘 (0) | 2022.06.26 |
|---|---|
| [Book Review] MLOps 도입 가이드 (0) | 2022.05.26 |
| [Book Review] fastai와 파이토치가 만나 꽃피운 딥러닝 (0) | 2022.03.27 |
| [Book Review] 비전 시스템을 위한 딥러닝 (0) | 2022.02.23 |
| [Book Review] 딥러닝을 위한 파이토치 입문 (2) | 2022.01.31 |