[TensorRT] NVIDIA TensorRT 개념, 설치방법, 사용하기
1. TensorRT 란?
2. TensorRT 설치하기
3. 여러 프레임워크에서 TensorRT 사용하기
1. TensorRT 란?
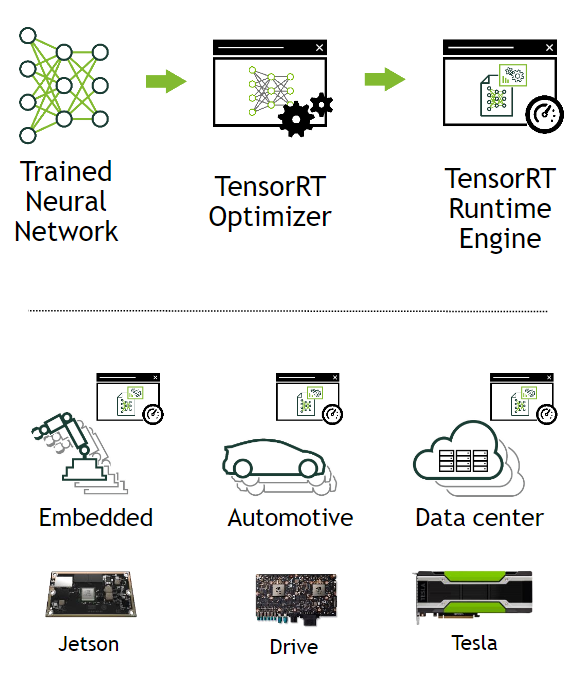
TensorRT는 학습된 딥러닝 모델을 최적화하여 NVIDIA GPU 상에서의 추론 속도를 수배 ~ 수십배 까지 향상시켜 딥러닝 서비스를 개선하는데 도움을 줄 수 있는 모델 최적화 엔진이다. 흔히들 우리가 접하는 Caffe, Pytorch, TensorFlow, PaddlePaddle 등의 딥러닝 프레임워크를 통해 짜여진 딥러닝 모델을 TensorRT를 통해 모델을 최적화하여 TESLA T4 , JETSON TX2, TESLA V100 등의 NVIDIA GPU 플랫폼에 아름답게 싣는 것이다.
또한, TensorRT는 NVIDIA GPU 연산에 적합한 최적화 기법들을 이용하여 모델을 최적화하는 Optimizer 와 다양한 GPU에서 모델 연산을 수행하는 Runtime Engine 을 포함한다. TensorRT는 대부분의 딥러닝 프레임워크에서 학습된 모델을 지원하며, 최적의 딥러닝 모델 가속화를 지원한다.
TensorRT의 장점은 C++ 및 Python 을 API 레벨에서 지원하고 있기 때문에 GPU 프로그래밍인 CUDA 지식이 별로 없어도 딥러닝 분야의 개발자들이 쉽게 사용할 수 있다. 또한 GPU가 지원하는 활용 가능한 최적의 연산 자원을 자동으로 사용할 수 있도록 Runtime binary 를 빌드해주기 때문에 Latency 및 Throughput 을 쉽게 향상시킬 수 있고, 이를 통해 딥러닝 응용프로그램 및 서비스의 효율적인 실행이 가능하다. 또한 흔히들 알고있는 Convolution Layer, ReLU 등의 Layer 뿐 만 아니라 다양한 Layer 및 연산에 대하여 Customization 할 수 있는 방법론을 제공(다소 어려운 감이 있지만 ...)하여 개발자들이 유연하게 TensorRT를 활용할 수 있도록 하고 있다.
TensorRT는 NVIDIA 플랫폼에서 최적의 추론 성능을 낼 수 있도록 Network compression, Network optimization, GPU 최적화 기술들을 딥러닝 모델에 자동 적용해준다. 딥러닝 가속화 기법들은 다음과 같다.
- Quantization & Precision Calibration (양자화 및 정밀도 캘리브레이션)
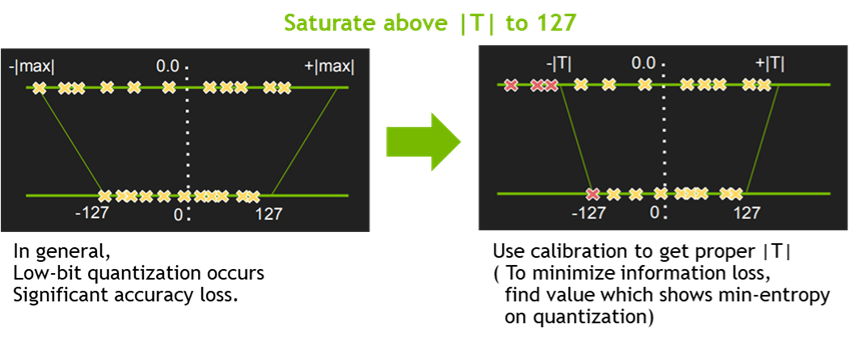
딥러닝의 학습 및 추론에서 정밀도(Precision)를 낮추는 일은 거의 일반적인 방법이 되었다. 낮은 정밀도를 가지는 신경망일수록 데이터의 크기 및 가중치들의 bit 수가 작기 때문에 더 빠르고 효율적인 연산이 가능하다. 이를 위한 양자화 기법중 TensorRT는 Symmetric Linear Quantization 을 사용하고 있으며, 이를 통하여 딥러닝 프레임워크의 일반적인 FP32의 데이터를 FP16 및 INT8 의 데이터 타입으로 정밀도를 낮출 수 있다.

일반적으로 FP16 의 데이터 타입으로 정밀도를 낮추는 것은 모델 정확도에 큰 영향을 주지는 않지만, INT8의 데이터 타입으로 정밀도를 낮추는 것은 모델 정확도에 영향을 주기 때문에 추가적으로 캘리브레이션 작업이 필요하다. 이를 위해 TensorRT 에서는 EntropyCalibrator, EntropyCalibrator2, MinMaxCalibrator 를 지원하고 있으며, 이를 활용하여 양자화 시 가중치 및 intermediate tensor 들의 정보의 손실을 최소화 할 수 있다.
- Graph Optimization (그래프 최적화)
일반적으로 그래프 최적화는 딥러닝 신경망에서 사용되는 Primitive 연산 형태, Compound 연산 형태의 그래프 노드들을 각 플랫폼에 최적화된 코드들로 구성하기 위하여 사용된다. TensorRT 에서는 이를 기반으로 Layer Fusion 방식과 Tensor Fusion 방식을 동시에 적용하고 있다. Layer Fusion은 Vertical Layer Fusion, Horizontal Layer Fusion이 적용되고,또한 Tensor Fusion이 적용되어 모델 그래프를 단순화 시켜주어 모델의 Layer 수가 크게 감소하게 된다. 실제로 TensorRT를 사용하여 ResNet, MobileNet 과 같은 백본 신경망들을 최적화 하면 기존 노드 수가 몇 십배 까지 줄어드는 효과를 보았었다.

- Kernel Auto-tuning (커널 자동 튜닝)
TensorRT 는 NVIDIA의 다양한 플랫폼 및 아키텍쳐에 맞는 Runtime 생성을 도와준다. 각 제품들은 CUDA engine 의 갯수, 아키텍쳐, 메모리 그리고 Serialized engine 포함 여부에 따라 최적화 된 커널이 다르기 때문에 이를 TensorRT Runtime engine build 시 선택적으로 수행하여 최적의 engine binary 생성을 돕게된다.
- Dynamic Tensor Memory & Multi-stream execution (동적 텐서 메모리 및 멀티 스트림 실행)
그 외에도 메모리 관리를 통하여 footprint 를 줄여 재사용 할 수 있도록 도와주는 Dynamic tensor memory 기능이 존재하며, CUDA Stream 기술을 이용하여 multiple input stream 의 스케쥴링을 통해 병렬 효율을 그대화 할 수 있는 Multi-stream execution 기능도 존재한다.
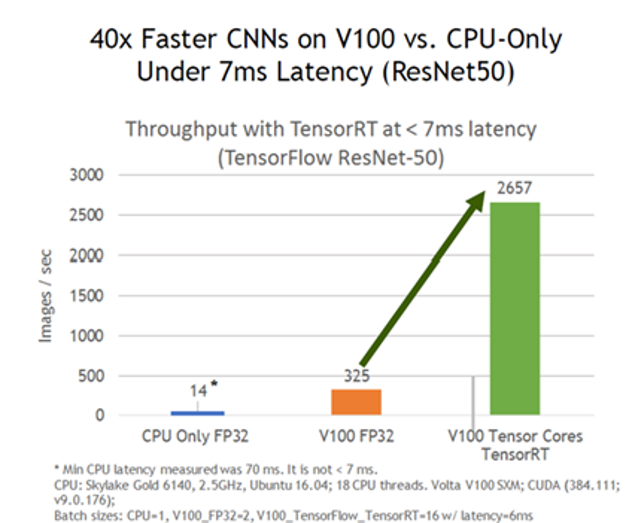
이러한 가속화 기술들을 이용하여 TensorRT는 "속도 향상" 이라는 결과를 얻을 수 있게 된다. 기본적으로 ResNet50 기준으로 볼 때 동일한 GPU 에서 TensorRT 를 사용하는 것만으로도 대략 8배 이상의 성능 향상 효과가 있다고 한다. 필자도 실제로 모델을 최적화 시켰을 때 Pytorch 나 TensorFlow 모델의 추론 속도에 비해 TensorRT Engine 화 하였을 때의 모델 추론 속도가 적게는 5배에서 많게는 10배 까지 속도 향상 결과를 맛봤다. 모델 백본에 따라 성능 차이는 있겠지만 딥러닝 서비스를 배포하기 위해 속도 측면에서 TensorRT가 핵심적인 역할을 수행할 수 있었다.
2. TensorRT 설치하기
TensorRT 는 필자의 오래전 경험에 의하면 Anaconda 에서는 실행하기 힘들다. Anaconda 와 같은 가상환경을 사용할 경우 TensorRT 가 설치된 곳을 제어할 수 없기 때문에 Anaconda 에서 TensorRT 의 실행은 지양한다.
보통 Nvidia Docker 에서 TensorRT Container 를 사용하거나, 그냥 쌩 로컬 환경에 TensorRT를 설치하는 것을 추천한다. 설치법은 이미 많은 분들이 포스팅 했을 거라고 생각한다... 하지만 간략히 써보도록 하겠다. 어렵진 않다. 도커를 사용한다면 문제 없겠지만, 로컬환경에 설치할 때 제일 중요한 건 환경 셋팅 인 듯 하다. 주요 포스팅은 다음을 참고하길 바란다. 아래 2.1 절과 2.2 에서는 간략히만 설명한다.
- (Linux) Docker Container 를 이용한 TensorRT 설치하기
- (Linux) 로컬 환경에 TensorRT 설치하기
- (Windows) 로컬환경에 TensorRT 설치하기
2.1 NVIDIA Docker 이용하여 TensorRT 설치하기
사실 이게 제일 깔끔한 방법이다. 자신의 CUDA 환경을 확인하여 적절한 컨테이너를 선정하여 설치하기 바란다.
NVIDIA Docker 가 우선적으로 설치되어야한다.
TensorRT Container Release Notes :
https://docs.nvidia.com/deeplearning/sdk/tensorrt-container-release-notes/running.html
* nvidia-docker 명령어 중 --rm 이라는 명령어는 도커 컨테이너를 종료하게 되면 생성한 컨테이너도 삭제되므로 주의
2.2 로컬환경에 TensorRT 설치하기
Linux 환경에서 TensorRT 7.0.0 (.tar)기준 설치 방법은 다음과 같다.
Requirements
- PyCUDA 설치
pip install 'pycuda>=2019.1.1'
* TensorRT 예제 실행 도중 PyCUDA 관련 에러가 날 경우, pip uninstall pycuda 를 통해 삭제하고 위와 같이 다시 다운할 것
- CUDA 9.0 / 10.0 / 10.2
- cuDNN 7.6.5
- TensorFlow 1.14.0 (이 버전으로 예제 코드가 테스트 되었다고 한다.)
- Pytorch 1.3.0 (1.2.0 도 가능)
2.2.1 TensorRT 7.0.0 다운로드 (.tar) :
https://developer.nvidia.com/tensorrt
2.2.2 압축풀기
tar xzvf TensorRT-7.x.x.x ~~~
2.2.3 환경 변수 추가
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:<다운로드경로/TensorRT_폴더이름/lib>
2.2.4 python 패키지 설치 (python2.x 이면 pip2 ~ python3.x 이면 pip3 ~)
cd TensorRT-${version}/python
sudo pip2 install tensorrt-*-cp27-none-linux_x86_64.whl
sudo pip3 install tensorrt-*-cp3x-none-linux_x86_64.whl
2.2.5 UFF 패키지 설치 (python2.x 이면 pip2 ~ python3.x 이면 pip3 ~)
cd TensorRT-${version}/uff
sudo pip2 install uff-0.6.5-py2.py3-none-any.whl
sudo pip3 install uff-0.6.5-py2.py3-none-any.whl
아래와 같이 입력했을 때 경로가 뜨면 성공
which convert-to-uff
2.2.6 graphsurgeon 패키지 설치 (python2.x 이면 pip2 ~ python3.x 이면 pip3 ~)
cd TensorRT-${version}/graphsurgeon
sudo pip2 install graphsurgeon-0.4.1-py2.py3-none-any.whl
sudo pip3 install graphsurgeon-0.4.1-py2.py3-none-any.whl
3. 여러 프레임워크에서 TensorRT 사용하기
TensorRT는 Keras 모델을 이용하여 TensorFlow pb 를 만들고 Freeze 시켜 TensorRT 엔진을 생성할 수도 있고, TensorFlow 모델을 이용하여 Freeze 된 pb 파일을 만든 뒤 uff parser 를 통해 TensorRT 엔진을 생성할 수 도 있고, Caffe 모델을 이용하여 TensorRT 엔진을 만들 수도 있고, Pytorch 모델을 Onnx 모델로 만든 뒤 TensorRT 엔진을 생성할 수도 있다. 이렇듯 다양한 여러 프레임워크에서 TensorRT 를 이용하여 최적화가 가능하다. 본 포스팅에서는 TensorFlow 를 이용한 TensorRT, Pytorch 를 이용한 TensorRT 만을 다룬다.
- TensorFlow 를 이용한 TensorRT 사용하기
TensorRT 자체를 이용하여 엔진을 만들 수도 있지만 TensorFlow 1.7 버전 부터 포함된 TensorRT(TF-TRT)를 사용하여 엔진을 만들 수도 있다. 이 때 모델을 최적화 할 때 지원하지 않는 레이어가 있다면 TensorRT 에서는 에러를 내뿜고 더이상 최적화를 진행하지 않지만, TensorFlow에 내장된 TF-TRT 는 지원되지 않는 레이어가 있다 한들, 그를 무시하고 나머지를 최적화 시켜버리기 때문에 TensorRT 효과를 제대로 누릴 수 없다는 점이 있다. (TensorFlow 1.14 기준! / 2.0 버전은 바뀌었을지도 모른다는 생각이...) 그래서 본 포스팅에서는 TF-TRT 는 다루지 않는다.


1. ckpt + pbtxt 를 이용한 pb 파일 생성하기
def main():
freeze_graph.freeze_graph('/graph.pbtxt', "", False,
'/checkpoint.ckpt', 'output_node_name',
"save/restore_all", "save/Const",
'frozen.pb', True, "")
print('done.')
if __name__ == '__main__':
main()TensorFlow 모델을 TensorRT Engine 화 하기 위해서는 ckpt + pbtxt 의 조합을 통해 freeze 된 pb 파일을 생성할 수 있다. 이 때 ckpt 는 학습이 완료된 가중치여야 하며, pbtxt 는 pb 를 읽을 수 있는 이진파일을 뜻한다. 이밖에도 학습된 pb 를 TensorFlow 에 내장되어있는 freeze_graph 를 이용하여 frozen pb 를 생성할 수도 있다.
또한 output_node_name 을 적어주는 것이 중요하다. 자신이 만든 모델이라면 output name 을 지정하여 모델을 생성 할 수 있지만, 타인이 만든 모델이라면 output name 이 지정되어있지 않을 수도 있어서 output shape 을 보고 추론하거나, graph viewer 를 보고 일일이 추론해야하기 때문에 어려움이 존재한다. 어디서부터 어디까지 freeze 할 것 인지가 관건이기 때문에 output node 를 찾는 것은 중요하다.
* graph viewer 는 TensorBoard 또는 netron 을 추천한다. https://lutzroeder.github.io/netron/
[TensorRT] 마지막 노드 찾기
이 포스팅은 Tensorflow 에서 이미 만들어진 ckpt 파일을 가지고 TensorRT로 변환하는 과정에서 마지막 노드를 찾기 위하여 겪게 된 삽질들을 적어두었다 ^^ Tensorflow에서 이미 만들어진 ckpt 파일만 가지고 pb..
eehoeskrap.tistory.com
[TensorFlow] .ckpt vs .pb vs .pbtxt 차이점
간단하게 말하자면 아래와 같다. ckpt 파일 모델의 변수(가중치)인 체크포인트 파일 pb 파일 모델의 변수 + 구조 (즉, 전체 그래프) 로 이루어진 바이너리 파일 pbtxt 파일 pb 파일을 읽을 수 있는 텍스트 파일,..
eehoeskrap.tistory.com
2. uff parser 를 이용하여 TensorRT Engine 을 생성할 수 있도록 uff 파일 만들기
TensorRT 설치 할 때 같이 설치했던 convert-to-uff 패키지를 이용하여 uff 파일을 만들 수 있다.
정상적으로 output node 를 인식하여 freeze 된 pb 파일을 만들었으며, 모두 TensorRT 7.0 버전에서 지원되는 레이어만을 그래프가 포함하고 있다면 문제없이 uff 파일이 생성될 것이다.
convert-to-uff frozen_inference_graph.pb
변환 이전에 인식된 노드를 확인하고 싶다면 아래와 같이 입력
convert-to-uff frozen_inference_graph.pb -l
3. uff 파일을 TensorRT engine 파일로 변환
model_file = "frozen.uff"
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.UffParser() as parser:
parser.register_input("input", (B, H, W, C))
parser.register_output("output")
parser.parse(model_file, network)
4. engine build (Python or C++)
https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#python_topics
TensorRT Developer Guide :: NVIDIA Deep Learning SDK Documentation
To optimize your model for inference, TensorRT takes your network definition, performs optimizations including platform-specific optimizations, and generates the inference engine. This process is referred to as the build phase. The build phase can take con
docs.nvidia.com
- Pytorch 모델을 Onnx로 변환하고 TensorRT 사용하기
Pytorch 프레임워크를 통하여 학습된 모델을 Onnx로 변환하고, Onnx 모델을 TensorRT Engine 으로 변환하는 방법에 대해 다룬다. Onnx 를 통해 TensorRT Engine 으로 변환할 수도 있지만 바로 Torch to TensorRT 로도 갈 수 있다. 아래 링크를 참고하길 바란다.
https://github.com/NVIDIA-AI-IOT/torch2trt
NVIDIA-AI-IOT/torch2trt
An easy to use PyTorch to TensorRT converter. Contribute to NVIDIA-AI-IOT/torch2trt development by creating an account on GitHub.
github.com
1. Onnx 생성하기
Onnx 모델을 생성할 때는 Pytorch 모델에 입력되는 input shape 과 동일해야한다. shape 만 맞춰준다면 어떠한 랜덤 값이 들어가도 무방하다. torch.onnx.export 시 중요한 것은 파이토치 모델, 입력 값 만 있으면 Onnx 모델을 만들 수 있다. torch.onnx.export 함수는 기본적으로 scripting 이 아닌 tracing 을 사용하기 때문에 example input 을 넣어주어야 한다.
때에 따라 필요한 옵션을 추가하여 Onnx 모델을 생성 할 수 있다. 이 때 verbose=False 라는 옵션을 추가하면, 어떤 노드들이 Onnx 모델을 위해 인식되었는지 로그를 띄울 수 있다.
import io
import numpy as np
from torch import nn
import torch.utils.model_zoo as model_zoo
import torch.onnx
import torch.nn as nn
import torch.nn.init as init
batch_size = 1
model.load_state_dict(torch.load(PATH))
torch_model.eval()
x = torch.randn(batch_size, 1, 224, 224, requires_grad=True)
torch_out = torch_model(x)
torch.onnx.export(torch_model, # 실행될 모델
x, # 모델 입력값 (튜플 또는 여러 입력값들도 가능)
"super_resolution.onnx", # 모델 저장 경로 (파일 또는 파일과 유사한 객체 모두 가능)
export_params=True, # 모델 파일 안에 학습된 모델 가중치를 저장할지의 여부
opset_version=10, # 모델을 변환할 때 사용할 ONNX 버전
do_constant_folding=True, # 최적하시 상수폴딩을 사용할지의 여부
input_names = ['input'], # 모델의 입력값을 가리키는 이름
output_names = ['output'], # 모델의 출력값을 가리키는 이름
dynamic_axes={'input' : {0 : 'batch_size'}, # 가변적인 길이를 가진 차원
'output' : {0 : 'batch_size'}})
2. Onnx 를 이용하여 TensorRT Engine 생성하기
TensorRT Sample 에 포함된 onnx_to_tensorrt.py 예제이다. 이보다 확실한 코드는 못봤다. build_engine 함수에서 내뿜는 engine 을 리턴받아 engine 을 build 하기만 하면 된다.
def get_engine(onnx_file_path, engine_file_path=""):
def build_engine():
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 1 << 30 # 1GB
builder.max_batch_size = 1
if not os.path.exists(onnx_file_path):
print('ONNX file {} not found, please run yolov3_to_onnx.py first to generate it.'.format(onnx_file_path))
exit(0)
print('Loading ONNX file from path {}...'.format(onnx_file_path))
with open(onnx_file_path, 'rb') as model:
print('Beginning ONNX file parsing')
parser.parse(model.read())
print('Completed parsing of ONNX file')
print('Building an engine from file {}; this may take a while...'.format(onnx_file_path))
engine = builder.build_cuda_engine(network)
print("Completed creating Engine")
with open(engine_file_path, "wb") as f:
f.write(engine.serialize())
return engine
if os.path.exists(engine_file_path):
# If a serialized engine exists, use it instead of building an engine.
print("Reading engine from file {}".format(engine_file_path))
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
else:
return build_engine()
* 혹시라도 잘못된 정보나 고칠 사항이 있다면 언제든지 댓글 부탁드립니다.
참고자료 1 : https://blogs.nvidia.co.kr/2020/02/19/nvidia-tensor-rt/
NVIDIA TensorRT – Inference 최적화 및 가속화를 위한 NVIDIA의 Toolkit - 엔비디아 공식 블로그
엔비디아 텐서(Tensor)RT는 다양한 딥 러닝 프레임워크로 사전 트레이닝된 뉴럴 네트워크들이 엔비디아 GPU 플랫폼에서 효과적으로 추론을 할 수 있게 돕는 툴 킷 혹은 라이브러리입니다. 텐서 RT의 다양한 기능들이 궁금하다면 본문을 읽어보세요!
blogs.nvidia.co.kr
참고자료 2 : https://hiseon.me/data-analytics/tensorflow/tensorflow-tensorrt/
텐서플로우에서 TensorRT 사용 방법 - HiSEON
텐서플로우에서 TensorRT 사용 방법 Tensorflow에서 TensorRT를 사용하는 방법에 대해서 설명드립니다. TensorRT를 설치하는 방법과 기존 모델에서 어떻게 TensorRT를 사용하여 그래프를 최적화 하는지 예제 소스코드와 함께 설명드립니다.
hiseon.me
참고자료 3 : https://gusrb.tistory.com/21
[TensorFlow] 모델 체크포인트 변환 .ckpt to .pb (inception-resnet-v2)
시작 (수정 중) Converting the TensorFlow model checkpoint file. .ckpt -> .pb Inception-v3 , Inception-Resnet-v2 예제를 활용하여 학습 시키면 결과로 .ckpt 파일을 생성한다. Inception-Resnet-v2로 학습한..
gusrb.tistory.com
참고자료 4 : https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#python_topics
TensorRT Developer Guide :: NVIDIA Deep Learning SDK Documentation
To optimize your model for inference, TensorRT takes your network definition, performs optimizations including platform-specific optimizations, and generates the inference engine. This process is referred to as the build phase. The build phase can take con
docs.nvidia.com
참고자료 5 : https://tutorials.pytorch.kr/advanced/super_resolution_with_onnxruntime.html
(선택) PyTorch 모델을 ONNX으로 변환하고 ONNX 런타임에서 실행하기 — PyTorch Tutorials 1.4.0 documentation
Note Click here to download the full example code (선택) PyTorch 모델을 ONNX으로 변환하고 ONNX 런타임에서 실행하기 이 튜토리얼에서는 어떻게 PyTorch에서 정의된 모델을 ONNX 형식으로 변환하고 또 어떻게 그 변환된 모델을 ONNX 런타임에서 실행할 수 있는지에 대해 알아보도록 하겠습니다. ONNX 런타임은 ONNX 모델을 위한 엔진으로서 성능에 초점을 맞추고 있고 여러 다양한 플랫폼과 하드웨어(
tutorials.pytorch.kr
참고자료 6 : https://gaussian37.github.io/dl-pytorch-deploy/
pytorch 모델 저장과 ONNX 사용
gaussian37's blog
gaussian37.github.io
참고자료 7 : https://yunmorning.tistory.com/17
PyTorch를 ONNX로 export하기
ONNX란? ONNX(Open Neural Network Exchange)는 그 이름에서 살펴 볼 수 있듯이, Tensorflow, PyTorch와 같은 서로 다른 DNN 프레임워크 환경에서 만들어진 모델들을 서로 호환되게 사용할 수 있도록 만들어진 공..
yunmorning.tistory.com
참고자료 8 : https://medium.com/@fanzongshaoxing/accelerate-pytorch-model-with-tensorrt-via-onnx-d5b5164b369
Accelerate PyTorch Model With TensorRT via ONNX
PyTorch is one of the most popular deep learning network frameworks due to its simplicity and flexibility with its dynamic computation…
medium.com