[Paper Review] Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression
Paper : https://arxiv.org/pdf/2104.02300.pdf
Github : https://github.com/HRNet/DEKR
HRNet/DEKR
This is an official implementation of our CVPR 2021 paper "Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression" (https://arxiv.org/abs/2104.02300) - HRNet/DEKR
github.com
오랜만에 읽고싶은 논문이 생겨서 이렇게 리뷰를 작성해본다. 논문은 그동안 가끔 읽었었는데 정리를 하는건 엄청 오랜만이라, pose estimation 카테고리에 쓸지, paper review 카테고리에서 쓸지 3분 동안 고민했당.
Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression 이라는 논문이고, DEKR 이라고 지칭한다고 한다. 뭔가 이름이 DETR(DEtection TRansformer)과 굉장히 비슷한 느낌...
Human Pose Estimation 분야는 크게 Bottom-up / Top-down Approach로 나뉘는데, 이 논문의 제목에서도 알 수 있듯 Bottom-up approach에 집중한 논문이며, "Regression"을 이용하여 키포인트를 추정하게 된다. 이 때 regression 을 할 때 키포인트 영역에 초점을 맞춘 representation을 학습하게 된다. Disentangled 라는 단어는 "엉클어진 것을 풀다" 라는 뜻인데 아마도 keypoint regression 과정에서 어려웠던 분리된 키포인트 후보 영역(히트맵)에서 관절 키포인트 지점을 어떻게 딱 지정할 것인지에 대해 엉켜있는 것을 푼다고 표현 한 것 같다. (맞나? 말이 되게 어렵다;;) 여기서 지칭하는 DEKR은 Disentangled Keypoint Regression 이라는 뜻이다.
Abstract
pixel-wise spatial transformer 를 통해 adaptive convolutions 을 채택하여 키포인트 영역의 픽셀을 활성화 시키고 이로부터 representation 을 학습한다. 별도의 regression 을 위해 multi-branch 구조를 사용하며, 각 분기를 adaptive convolutions을 사용하여 representation 을 학습하고 하나의 키포인트를 regression 하게 된다.
결과적으로 disentangled representation 은 각각 키포인트 영역에 집중할 수 있으므로 키포인트 regression은 공간적으로 정확하다고 볼 수 있다.
이러한 regression 방식은 키포인트 탐지 및 그룹화 방법(PAF를 말하는 것 같음)을 능가하고 COCO 및 CrowdPose 벤치마크에서 우수한 결과를 나타낸다.
1. Introduction
최근에 발표된 CenterNet은 representation at the pixel 에서 각 픽셀에 대해 K 키포인트 위치를 함께 추정하게 되는데, 이 키포인트 위치에 대한 직접적인 회귀는 합리적으로 수행되지만 회귀된 키포인트는 공간적으로 정확하지 않으며 성능은 keypoint detection 및 grouping scheme 보다 나쁘다. 아래 그림1 왼쪽 그림과 같이 키포인트 회귀의 두드러진 영역이 광범위하게 퍼져있고 회귀 품질이 만족스럽지 않은 두 가지 예시가 있다.

본 논문에서 키포인트 위치를 정확하게 회귀하려면 키포인트 영역에 초점을 맞춘 representation 을 학습해야한다고 주장하고 있다. 초점 개념에 의한 회귀에서 시작하여 DEKR 이라는 간단하면서 효과적인 접근 방식을 제시한다. pixel-wise spatial trnasformer 를 통해 adaptive convolutions을 채택하여 키포인트 영역에 있는 픽셀을 활성화 시킨 다음 활성화 된 픽셀에서 representation 을 학습하게 된다. 학습된 representation은 키포인트 영역에 포커스를 맞출 수 있다.
본 논문에서는 multi-branch 구조를 통해 회귀를 하게 되는데 각 branch는 키포인트 전용 adaptive convolutions을 사용하여 하나의 키포인트에 대한 representation을 학습하고, 해당 키포인트에 대한 위치를 회귀한다. 이러한 방식을 사용하면 그림 1의 오른쪽 결과를 낼 수 있다.
이러한 DEKR 접근법은 회귀된 키포인트의 위치의 localization 품질을 개선할 수 있다는 것을 보여준다. 회귀 결과를 키포인트 히트맵에서 탐지된 가장 가까운 키포인트와 일치시키지 않고 직접 키포인트 회귀를 수행하는 우리의 방식은 이전의 키포인트 감지 및 그룹화 방법을 능가하며 COCO 및 CrowdPose 에서 상향식 자세 추정 방식에서 우수한 성능을 달성한다.
본 논문의 contribution 은 아래와 같다.
- 우리는 키포인트의 위치를 회귀하기 위한 representation을 키포인트 영역에 정확하게 초점을 맞추어 설정할 필요가 있다고 주장한다.
- 제안된 DEKR 접근 방식은 adaptive convolutions 및 multi-branch 구조의 두 가지 단순한 체계를 통해 disentangled representations 즉 분리된 표현을 학습 할 수 있으므로, 각 표현은 하나의 키포인트 영역에 초점을 맞추고 이러한 표현으로부터 해당 키포인트 위치의 예측은 정확하게 이루어진다.
- 제안된 direct regressioon 접근 방식은 이전의 키포인트 감지 및 그룹화 방식 체계를 능가하게 되고 COCO 및 CrowdPose 에서 상향식 자세 추정 방식에서 우수한 성능을 달성한다.
2. Related Work
Top-down paradigm
하향식 방식에는 HRNet, PoseNet, RMPE, convolutional pose machine, Hourglass, Mask R-CNN, CFN, Integral pose regression, CPN, simple baseline, CSM-SCARB, Graph-PCNN, RSN 등의 방법이 있는데, 사람의 경계 상자 영역을 이용하게 되어 추가적인 비용이 든다. 또한 히트맵에서 키포인트 위치를 파악하기 위한 개선 방법, 자세 추정 개선 방법, 더 나은 데이터 증가 방법, 탐지, 폐색 문제 처리, 세분화 및 자세 추정을 결합한 다중 작업 구조 개발 등 기타 개발 사항들이 존재한다.
Bottom-up paradigm
대부분의 기존 상향식 방법은 주로 동일한 사람이라고 판단되면 키포인트를 연결하는 방법을 많이 사용하였다. 선구적으로 DeepCut, DeeperCut 및 L-JPA 등이 있었으며, 그 다음으로 OpenPose의 Part-affinity fields와 Pif-Paf의 확장, associative embedding, greedy decoding with hough voting in PersonLab, graph clustering in HGG 등의 방법이 있다. 최근 몇몇 연구에서는 포즈 후보 세트를 조밀하게 회귀하여 각 후보는 같은 사람의 kepoint position 으로 구성된다. 이는 회귀 품질이 높지 않고 localization 품질이 약하다. 회귀된 키포인트 위치를 키포인트 히트맵에서 감지된 가장 가까운 키포인트와 일치시키는 사후 처리 체계는 일반적으로 회귀 결과를 개선하기 위해 채택되곤 했다.
우리의 접근 방식은 회귀를 탐색하여 직접 회귀 결과를 개선하는 것을 목표로 한다. 각 표현은 하나의 키포인트 전용이며 적응적으로 활성화된 픽셀에서 학습하여 각 표현이 해당 키포인트 영역에 집중하도록 한다. 결과적으로 분리된 히트맵에서 하나의 키포인트에 대한 위치 예측은 공간적으로 정확하게 추정할 수 있게 된다.
3. Approach
이미지 I 에서 multi-person pose estimation 은 사람의 포즈를 예측하는 것을 목표로 하며, 각 포즈는 어깨, 팔꿈치 등과 같은 K개의 키포인트로 구성된다. 그림 2는 이러한 multi-person pose estimation을 보여준다.

3.1. Disentangled Keypoint Regression
픽셀 단위 키포인트 회귀 프레임워크는 K 키포인트에 대해 center pixel 인 $ q $ 에서 $ 2K-dimensional $ offset vector 인 $ o_{q} $ 를 예측하여 각 픽셀 $ q $에서 후보 포즈를 추정한다. 모든 픽셀에서 offset vector를 포함하는 offset maps $ O $는 키포인트 회귀 헤드를 통해 추정된다.
$ O = F(X) $
여기서 X는 backbone 에서 계산된 특징이고, 이 논문에서의 backbone 은 HRNet 이다. 또한 $ F( ) $는 offset maps $ O $를 예측하는 키포인트 위치 회귀 헤드이다. 제안된 DEKR 헤드의 구조는 아래 그림 3과 같다.
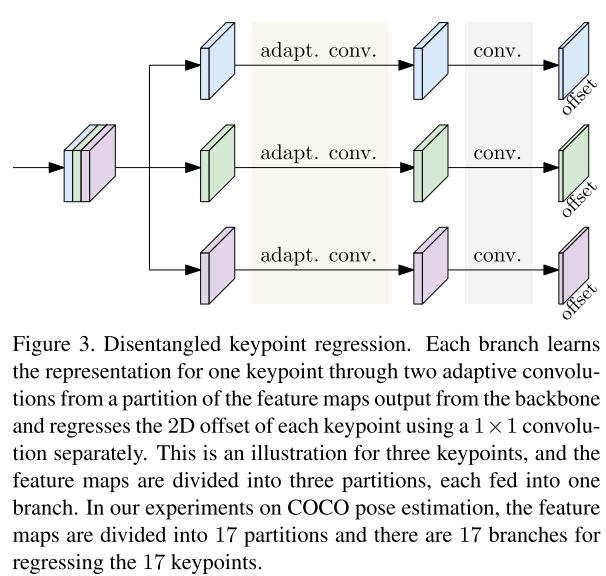
DEKR은 multi-branch parallel adaptive convolutions 을 채택하여 K 키포인트의 회귀에 대한 disentangled representations을 학습하므로 각 representation이 해당 키포인트에 초점을 맞추게 된다.
Adaptive activation.
하나의 일반 컨볼루션(3x3)은 center pixel $ q $ 근처의 픽셀만 볼 수 있다. 여러개의 일반적인 컨볼루션의 시퀀스를 통해 center pixel에서 더 멀리 떨어진 픽셀이 키포인트 영역에 있을 수 있지만 이러한 픽셀에 초점을 맞추지 못하고 활성화 되지 않을 수도 있다. 우리는 키포인트 영역에 초점을 맞추는 representation을 학습하기 위해 adaptive convolution을 채택한다.
$ y(q) = \sum_{i=1}^{9}W_{i}x(g_{si}^{q}+q) $
여기서 $ q $는 center (2D) position 이고, $ g_{si}^{q} $는 offset 이며, $ g_{si}^{q}+q $ 는 i 번째 활성화 된 픽셀에 해당한다. $ \left \{ W_{1}, W_{2}, ... , W_{9} \right \} $ 는 kernel weight 이다.
2x9 matrix로 표시된 offset $ \left \{ g_{s1}^{q}, g_{s2}^{q}, ..., g_{s9}^{q} \right \} $ 는 deformable convolution과 같은 nonparametrix 방식으로 또는 spatial transformer network를 global manner 에서 픽셀 단위로 확장하는 parametric 방식으로 추정될 수 있다. 우리는 후자의 방법을 채택하고, 각 픽셀에 대해 affine transformation matrix $ A^{q}\left ( \in \mathbb{R}^{2\times 2} \right ) $ 와 translation vector $ t\left ( \in \mathbb{R}^{2\times 1} \right ) $ 를 추정한다.
여기서 $ G_{s}^{q} = A^{q}G_{t}+\left [ t t ... t \right ] $ 는 regular 3 x 3 position을 나타낸다. (변환된 공간에서 일반 컨볼루션이 진행됨을 의미)
$ G_{t} = \begin{bmatrix}
-1 & 0 & 1 & -1 & 0 & 1 & -1 & 0 & 1\\
-1 & -1 & -1 & 0 & 0 & 0 & 1 & 1 & 1
\end{bmatrix} $
Separate regression.
offset regressor $ F $는 단일 분기이며, 각 위치에 대한 단일 특성에서 모든 $ K 2D $ offset 을 함께 추정한다. 각 분기가 adaptive convolutions을 수행한 다음 해당 키포인트에 대한 offset을 회귀 시키는 $K$-branch 구조를 사용할 것을 제안한다. backbone에서 feature map $ X $ output 을 $ X_{1}, X_{2}, ... , X_{K} $ 로 나눈고, 해당 feature map 에서 각 키포인트에 대한 offset map $ O_{k} $ 를 추정한다.
$ O_{1} = F_{1}(X_{1}) $
$ O_{2} = F_{2}(X_{2}) $
...
$ O_{K} = F_{K}(X_{K}) $
여기서 $ F_{K} $는 k번째 분기의 k번째 회귀 분석기이며 $ O_{K} $는 k번째 키포인트에 대한 offset map이다. K 회귀 분석기 $ F_{1}( ), F_{2}( ), ... , F_{K}( ) $ 는 구조가 동일하며 매개변수를 독립적으로 학습하게 된다.
Separate regression의 각 분기는 own adaptive convolutions을 학습할 수 있으며, 그에 따라 해당 키포인트 영역에서 픽셀을 활성화 하는데 초점을 맞춘다. 그림 4b-e와 같다.

single-branch의 경우 모든 키포인트 주변의 픽셀이 활성화되고 그림 4-a와 같이 활성화에 초점이 맞춰지지 않는다. multi-branch 구조는 한 키포인트에 대한 representation learning을 다른 키포인트로부터 명시적으로 분리하여 회귀 품질을 향상시킨다. 반대로 single-branch 구조는 feature learning을 암묵적으로 분리해야하기 때문에 optimization 난이도가 높다. 그림 5의 결과는 multi-branch 구조가 회귀 손실을 감소시킨다는 것을 보여준다.

3.2. Loss Function
Regression loss.
손실함수는 normalized smooth loss 를 사용하여 픽셀 단위의 키포인트 회귀 손실을 형성하였다.
$ l _{p}=\sum _{i\in C}\frac{1}{Z_{i}}smooth_{L_{1}}\left ( o_{i} - o_{i}^{*} \right ) $
여기서 $ Z_{i} = \sqrt{H_{i}^{2} + W_{i}^{2}} $ 은 해당하는 person instance의 크기이며, $ H_{i} $와 $ W_{i} $는 instance box 의 높이와 너비이다. $ C $는 GT poses 의 집합이다. $ o_{i} (o_{i}^{*}) $ offset map 의 column 이며, 위치 i에 대한 2K-dimensional estimated (groundtruth) offset vector 이다.
Keypoint and center heatmap estimation loss.
또한 개별 히트 맵 추정 분기를 사용하여 키포인트 유형 및 각 픽셀이 사람의 중심이라는 신뢰를 나타내는 중앙 히트 맵에 각각 해당하는 K 개의 키포인트 히트 맵을 추정합니다.
$ \left ( H, C \right ) = H(X) $
히트맵은 회귀된 포즈의 점수와 순위를 매기는데 사용된다. 히트맵 추정 손실 함수는 예측된 heat value 와 GT heat value 값 사이의 가중 거리로 공식화 된다.
$ l_{h} =\left \| M^{h} \bigodot (H-H^{*}) \right \|_{2}^{2} + \left \| M^{c}\bigodot (C-C^{*}) \right \|_{2}^{2} $
여기서 $ \left \| \cdot \right \|_{2}^{2} $ 는 entry-wise 2-norm 이며 $ \bigodot $ 는 element-wise product operation 이다. $ M^{h} $는 K masks 를 가지며, size 는 H x W x K 이다. k 번째 마스크 $ M_{k}^{h} $ 는 k번째 키포인트 영역에 있지 않은 위치에 가중치는 0.1이고 그렇지 않은 경우는 1이다. center hetmap 의 $ M^{c} $ 에 대해서도 마찬가지이다. $ H^{*} $ 및 $ C^{*} $는 target keypoint 와 center heatmaps 이다.
Whole loss.
전체 손실 함수는 히트맵 손실과 회귀 손실의 합을 나타낸다.
$ l = l_{h} + \lambda l_{p} $
$ \lambda $는 trade off weight 이며 실험에서는 0.03 으로 설정되었다.
3.3 Inference
테스트 이미지가 네트워크에 입력되어 각 위치에서 회귀 된 포즈와 키포인트 및 중앙 히트 맵을 출력한다.. 먼저 중앙 히트 맵에서 중앙 NMS를 수행하여 로컬이 아닌 최대 위치와 중앙 열 값이 0.01 이하인 위치를 제거한다. 그런 다음 중앙 NMS 이후에 남아있는 위치에서 회귀 된 포즈에 대해 포즈 NMS를 수행하여 일부 중첩 된 회귀 포즈를 제거하고 최대 30 개의 후보를 유지한다. 포즈 NMS에 사용 된 점수는 회귀 된 K 키포인트에서 heat values 의 평균이며, 이는 매우 정확하게 위치 된 키포인트로 후보 포즈를 유지하는 데 도움이된다.
나머지 후보 포즈는 해당 중심 heat values 값, 주요 heat values 값 및 shape scores 를 모두 고려하여 추정 한 점수를 사용하여 순위를 매긴다. shape feature 에는 인접한 키포인트 쌍 사이의 거리 및 상대 오프셋과 각 키포인트의 가시성을 나타내는 키포인트 heat values가 포함된다.
scoring net 에 3가지 feature를 입력했는데, two fully-connected layers (each followed by a ReLU layer) 와 해당 예측 포즈에 대한 OKS 점수를 학습하는 것을 목표로 한다.
4. Experiments
다음은 실험 결과이다.


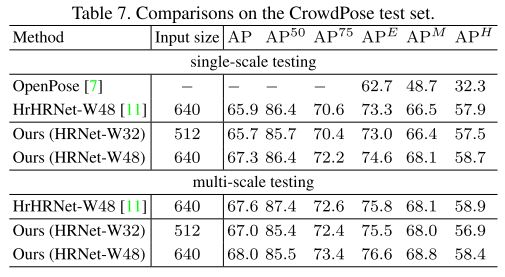
direct regression approach DEKR은 키포인트 keypoint localization 을 개선하고 상향식 접근법에서 SOTA를 달성한다.이는 서로 다른 키포인트를 회귀하기위한 representation을 분리하여 각 representation이 해당 키포인트 영역에 집중하도록했기 때문이다.