
[Paper Review] UniPose, Unified Human Pose Estimation in Single Images and Videos
“Waterfall” Atrous Spatial Pooling architecture를 기반으로 인간의 자세를 추정하는 UniPose를 소개합니다. 참고로 Waterfall Atrous Spatial Pooling 방법은 semantic segmentation을 위해 multiscale fields-of-view를 유지하면서 cascade architecture에서 progressive filtering을 활용하는 module 입니다. 본 논문에서는 contextual segmentation 및 joint localization을 통합하여 statistical postprocessing 방법에 의존하지 않고 single stage 에서 인간의 자세를 높은 정확도로 추정한다고 합니다! 이러한 방법은 multi-frame 처리를 위해 UniPose-LSTM으로 확장되며, 비디오 환경에서 SOTA를 달성합니다. 참고로 최근에 UniPose+ 으로 확장되었습니다. 😳

본 논문에서 제안하는 아키텍처의 주요 구성 요소는 Atrous Convolution에 대한 cascaded approach와 ASPP(Atrous Spatial Pyramid Pooling) module의 병렬 구성으로부터 얻어진 larger FOC(Field-of-View)를 결합한 Waterfall Atrous Spatial Pooling (WASP) module이라고 하네요. 참고로 ASPP는 multi-scale에 잘 대응할 수 있도록 확장 계수를 이용하여 넓은 receptive field를 볼 수 있도록 하는 Pooling 방법입니다. larger Field-of-View와 multi-scale approach로 인해 contextual information를 사용하여 관절의 위치를 예측해냅니다. contextual approach를 사용하면 신경망에 전체 프레임에 대한 정보가 포함되기 때문에 statistical or geometric 방법에 기반한 post-processing이 필요없다고 합니다.
주요 Contribution은 다음과 같습니다.
- single person human pose estimation을 위한 SOTA를 달성하는 Waterfall module for Atrous Spatial Pooling module을 기반으로 하는 UniPose 프레임워크를 제안
- Waterfall module은 spatial pyramid approach에서 영감을 받은 parallel architecture에서 multiple FOV와 cascade atrous convolutions의 이점을 결합하여 receptive field를 증가시킴
- 제안된 UniPose 방법은 관절의 위치와 사람 검출을 위한 경계 상자를 모두 결정하므로 신경망에서 별도의 branch가 필요하지 않음
- linear sequential LSTM 구성을 채택하여 Waterfall 기반 접근 방식을 UniPose-LSTM으로 확장하고 비디오 환경에서 temporal human pose estimation을 위한 SOTA를 달성
전체 UniPose architecture는 아래 그림과 같습니다. 입력 이미지는 처음에 CNN에 주어지고 최종 레이어는 WASP module로 대체됩니다. 최종 reature map은 Softmax에서 얻은 probability distributions과 함께 각 관절 마다 K개의 heatmaps을 생성한 decoder에 의해 처리됩니다. 그 다음 decoder에서 원래 해상도를 복원하기 위해 bilinear interpolation을 수행한 다음 자세 추정을 위해 관절을 localization하기 위한 local max 연산을 수행하게 됩니다. 여기서 decoder는 visible 및 occluded parts에 대한 관절을 탐지하게 되고, decoder는 post-processing 및 independent parallel branches를 사용하지 않고 bounding box를 생성합니다.
WASP module은 UniPose가 SOTA를 달성하는데 도움을 준 multi-scale representation을 생성합니다. 다음 그림과 같이 WASP architecture는 larger FOV of the ASPP와 cascade 접근 방식의 reduced size를 모두 활용하도록 설계되었습니다. 또한 WASP는 기본적으로 large FOV를 유지하기 위해 atrous convolution에 기반합니다. 또한 효율성을 높이기 위해 atrous conv를 cascade로 수행합니다. ASPP 및 Res2Net과는 달리 WASP는 입력 스트림을 바로 병렬화 하지 않고, filter를 먼저 처리한 다음 new branch를 만들어 waterfall을 생성합니다. 또한 이는 모든 branch의 stream과 원래 입력의 average pooling을 결합하여 multi-scale representation을 달성함으로써 cascade approach을 뛰어넘는 결과를 달성하게 됩니다. WASP의 atrous convolution은 6 정도의 작은 비율로 시작하여 subsequent branch에서 지속적으로 증가합니다. (rates of 6,12,18,24)
그 다음 decoder module은 WASP module의 score map을 body joints 및 bounding box에 해당하는 heatmaps으로 변환합니다. 다음 그림은 1280x720의 입력 컬러 이미지에 대한 decoder architecture를 보여줍니다. decoder는 WASP에서 256개의 feature map을 입력으로 받고, ResNet backbone의 첫 블록에서 256개의 low feature map을 입력으로 받습니다. 그 다음 입력 dimension을 match 시키기 위해 max pooling 연산 후 feature map은 concat 되고 원래 입력 크기로 조정하기 위해 conv layer, dropout layer 및 final bilinear interpolation을 통해 처리됩니다. output은 local max 연산 후 K개의 heatmap으로 구성됩니다.
UniPose-LSTM archtecture는 다음과 같이 구성되며, 네트워크의 전체 크기를 크게 늘리지 않고도 이전에 처리된 프레임의 정보를 네트워크에서 사용할 수 있으며, 단일 이미지 및 비디오에 대해 동일한 ResNet-101, WASP module 및 decoder를 사용한다고 합니다. 실험적으로 LSTM에 최대 5개의 프레임을 통합할 때 정확도가 향상되고 추가 프레임에 대해 정확도가 정체되는 것으로 확인되었다고 합니다.
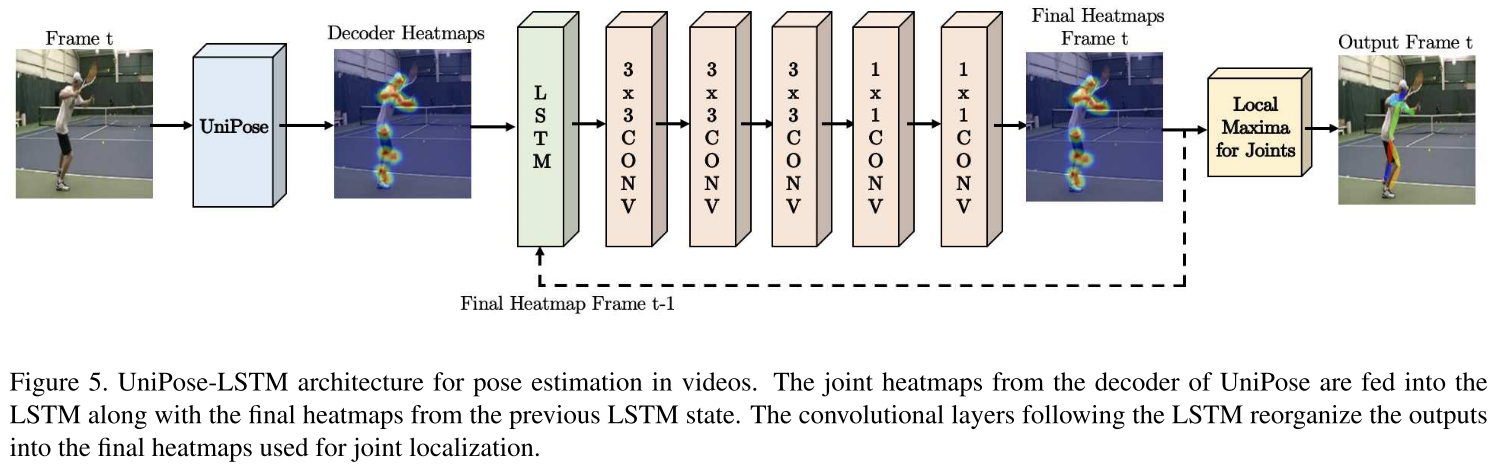
또한 Leeds Sports Pose, MPII, Penn Action, BBC Pose 데이터세트를 이용하여 실험을 수행하였으며, data pre-processing에서 이상적인 Gaussian maps은 GT label에서 생성되었으며, 이는 joint location의 single point 보다 학습에 더 효과적이라고 하네요! 또한 본 논문에서는 σ = 3의 값을 사용하여 Gaussian curve를 생성하였다고 합니다.
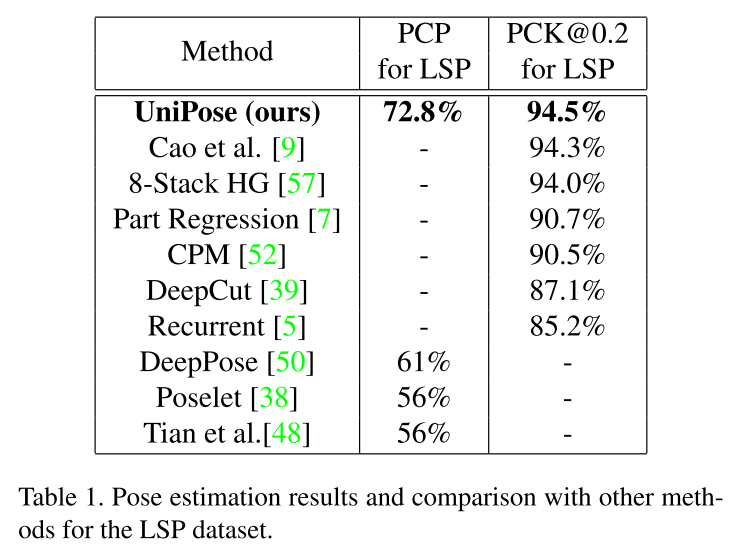
LSP 데이터세트에서의 실험 결과는 아래와 같습니다.

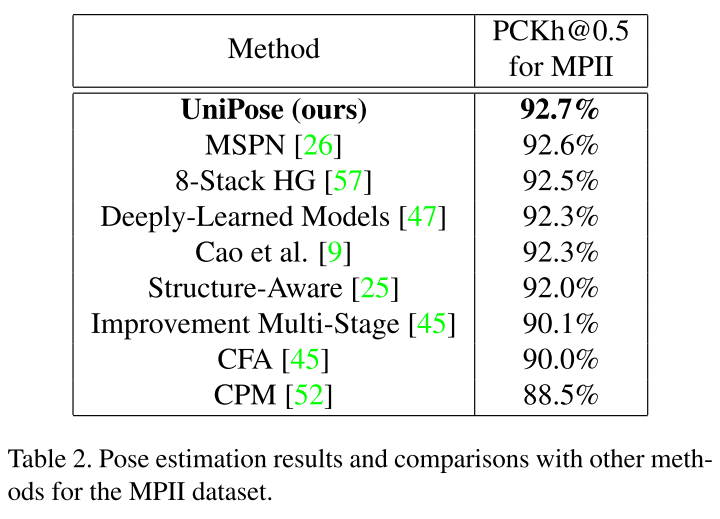
MPII 데이터세트에서의 실험 결과는 아래와 같습니다.

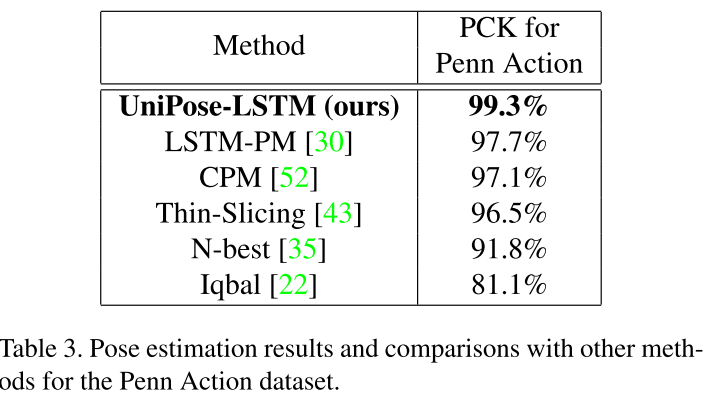
Penn Action 데이터세트에서의 실험 결과는 아래와 같습니다.


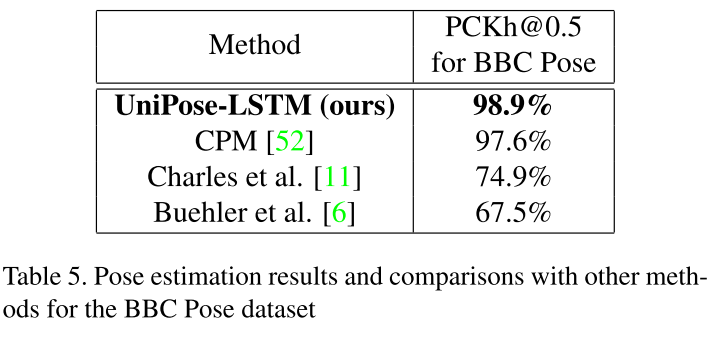
BBC Pose 데이터세트에서의 실험 결과는 아래와 같습니다.

결론적으로 UniPose는 WASP module (w/ a cascade of atrous convolutions and multi-scale representations)을 활용한 자세 추정 모델이며 large FOV of WASP는 프레임의 contextual information에 대한 더 나은 정보를 얻게 해주며, 더 정확한 자세 추정 결과를 달성하여 그 당시 SOTA를 달성하였다고 하네요. 추후 3D Pose에도 확장할 수 있다고 나와있는데 정말로 확장을 했습니다.
UniPose+: A unified framework for 2D and 3D human pose estimation in images and videos
2021년 11월 PAMI에 게재되었네요. 2022년 4월 기준으로 아직 UniPose+코드는 릴리즈 되지 않았습니다.
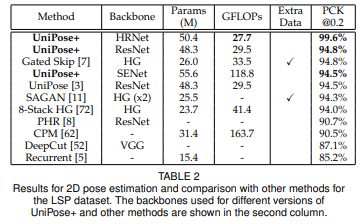
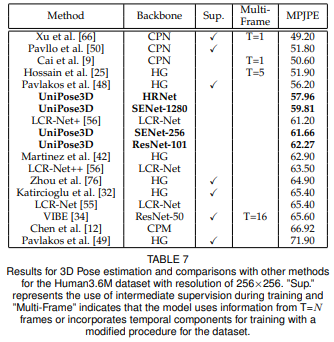
UniPose+는 LSP 데이터세트 기준으로 HRNet을 사용하여 99.6%을 달성했네요... (ResNet은 94.8%)
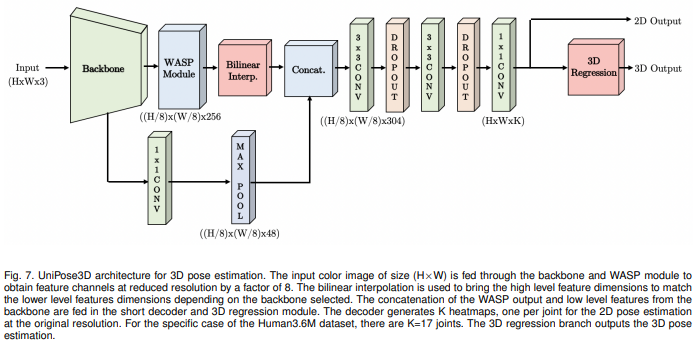
UniPose 모델 주요 코드를 보면 아래와 같이 구성되어 있습니다.
class unipose(nn.Module):
def __init__(self, dataset, backbone='resnet', output_stride=16, num_classes=21,
sync_bn=True, freeze_bn=False, stride=8):
super(unipose, self).__init__()
self.stride = stride
BatchNorm = nn.BatchNorm2d
self.num_classes = num_classes
self.pool_center = nn.AvgPool2d(kernel_size=9, stride=8, padding=1)
self.backbone = build_backbone(backbone, output_stride, BatchNorm)
self.wasp = build_wasp(backbone, output_stride, BatchNorm)
self.decoder = build_decoder(dataset, num_classes, backbone, BatchNorm)
if freeze_bn:
self.freeze_bn()
def forward(self, input):
x, low_level_feat = self.backbone(input)
x = self.wasp(x)
x = self.decoder(x, low_level_feat)
if self.stride != 8:
x = F.interpolate(x, size=(input.size()[2:]), mode='bilinear', align_corners=True)
# If you are extracting bouding boxes as well
# return x[:,0:self.num_classes+1,:,:], x[:,self.num_classes+1:,:,:]
# If you are only extracting keypoints
return x
class wasp(nn.Module):
def __init__(self, backbone, output_stride, BatchNorm):
super(wasp, self).__init__()
inplanes = 2048
if output_stride == 16:
#dilations = [ 6, 12, 18, 24]
dilations = [24, 18, 12, 6]
#dilations = [6, 6, 6, 6]
elif output_stride == 8:
dilations = [48, 36, 24, 12]
else:
raise NotImplementedError
self.aspp1 = _AtrousModule(inplanes, 256, 1, padding=0, dilation=dilations[0], BatchNorm=BatchNorm)
self.aspp2 = _AtrousModule(256, 256, 3, padding=dilations[1], dilation=dilations[1], BatchNorm=BatchNorm)
self.aspp3 = _AtrousModule(256, 256, 3, padding=dilations[2], dilation=dilations[2], BatchNorm=BatchNorm)
self.aspp4 = _AtrousModule(256, 256, 3, padding=dilations[3], dilation=dilations[3], BatchNorm=BatchNorm)
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(inplanes, 256, 1, stride=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU())
# self.global_avg_pool = nn.Sequential(nn.Conv2d(inplanes, 256, 1, stride=1, bias=False),
# nn.BatchNorm2d(256),
# nn.ReLU())
self.conv1 = nn.Conv2d(1280, 256, 1, bias=False)
self.conv2 = nn.Conv2d(256,256,1,bias=False)
self.bn1 = BatchNorm(256)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self._init_weight()
def forward(self, x):
x1 = self.aspp1(x)
x2 = self.aspp2(x1)
x3 = self.aspp3(x2)
x4 = self.aspp4(x3)
x1 = self.conv2(x1)
x2 = self.conv2(x2)
x3 = self.conv2(x3)
x4 = self.conv2(x4)
x1 = self.conv2(x1)
x2 = self.conv2(x2)
x3 = self.conv2(x3)
x4 = self.conv2(x4)
x5 = self.global_avg_pool(x)
x5 = F.interpolate(x5, size=x4.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x1, x2, x3, x4, x5), dim=1)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
return self.dropout(x)
class _AtrousModule(nn.Module):
def __init__(self, inplanes, planes, kernel_size, padding, dilation, BatchNorm):
super(_AtrousModule, self).__init__()
self.atrous_conv = nn.Conv2d(inplanes, planes, kernel_size=kernel_size,
stride=1, padding=padding, dilation=dilation, bias=False)
self.bn = BatchNorm(planes)
self.relu = nn.ReLU()
self._init_weight()
def forward(self, x):
x = self.atrous_conv(x)
x = self.bn(x)
return self.relu(x)
class Decoder(nn.Module):
def __init__(self, dataset, num_classes, backbone, BatchNorm):
super(Decoder, self).__init__()
if backbone == 'resnet':
low_level_inplanes = 256
if dataset == "NTID":
limbsNum = 18
else:
limbsNum = 13
self.conv1 = nn.Conv2d(low_level_inplanes, 48, 1, bias=False)
self.bn1 = BatchNorm(48)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(2048, 256, 1, bias=False)
self.bn2 = BatchNorm(256)
self.last_conv = nn.Sequential(nn.Conv2d(304, 256, kernel_size=3, stride=1, padding=1, bias=False),
BatchNorm(256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),
BatchNorm(256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Conv2d(256, num_classes+1, kernel_size=1, stride=1))
# nn.Conv2d(256, num_classes+5+1, kernel_size=1, stride=1)) # Use in case of extacting the bounding box
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self._init_weight()
def forward(self, x, low_level_feat):
low_level_feat = self.conv1(low_level_feat)
low_level_feat = self.bn1(low_level_feat)
low_level_feat = self.relu(low_level_feat)
#x = self.conv2(x)
#x = self.bn2(x)
#x = self.relu(x)
low_level_feat = self.maxpool(low_level_feat)
x = F.interpolate(x, size=low_level_feat.size()[2:], mode='bilinear', align_corners=True)
x = torch.cat((x, low_level_feat), dim=1)
x = self.last_conv(x)
#x = self.maxpool(x)
return x
UniPose Paper : https://arxiv.org/abs/2001.08095
UniPose: Unified Human Pose Estimation in Single Images and Videos
We propose UniPose, a unified framework for human pose estimation, based on our "Waterfall" Atrous Spatial Pooling architecture, that achieves state-of-art-results on several pose estimation metrics. Current pose estimation methods utilizing standard CNN a
arxiv.org
UniPose+ Paper : https://ieeexplore.ieee.org/document/9599531
UniPose+: A unified framework for 2D and 3D human pose estimation in images and videos
We propose UniPose+, a unified framework for 2D and 3D human pose estimation in images and videos. The UniPose+ architecture leverages multi-scale feature representations to increase the effectiveness of conventional backbone feature extractors, with no si
ieeexplore.ieee.org
Github : https://github.com/bmartacho/UniPose
GitHub - bmartacho/UniPose: We propose UniPose, a unified framework for human pose estimation, based on our “Waterfall
We propose UniPose, a unified framework for human pose estimation, based on our “Waterfall” Atrous Spatial Pooling architecture, that achieves state-of-art-results on several pose esti...
github.com