AI Research Topic/Human Pose Estimation
[Paper Review] CPN, Cascaded Pyramid Network for Multi-Person Pose Estimation
꾸준희
2022. 7. 18. 04:47
728x90
반응형
오늘은 Pose Estimation 분야에서 CPN으로 유명한 Casecaded Pyramid Network 논문을 빠르게 훑어보도록 하겠습니다. 이 논문에서는 여러가지 복합적인 요인(Occlusion, Background, ...)에 의하여 검출하기 어려운 키포인트들을 잘 검출하기 위해 CPN이라는 구조를 제안했습니다. 크게 아래 그림과 같이 GlobalNet과 RefineNet으로 구성되어있습니다.
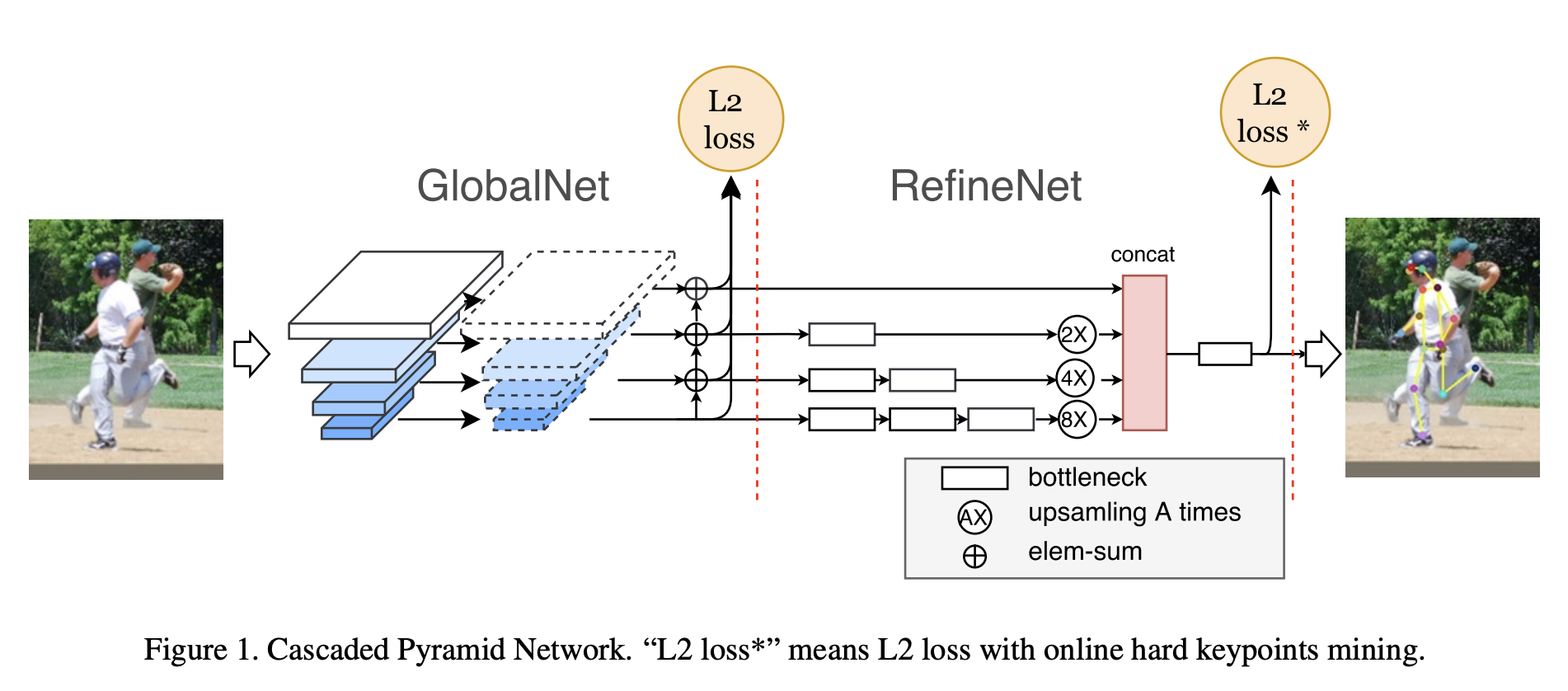
이름에서도 알 수 있듯이 GlobalNet에서는 feature pyramid network 기반으로 global feature를 추출하여 localization하는 방식이며, RefineNet은 GlobalNet에서 localization 하지 못한 hard keypoint를 hard keypoint mining loss를 이용하여 localization 하는 방식입니다. 참고로 위 그림에서 L2 loss*는 online hard keypoints mining이 적용된 L2 loss 입니다.
여기서 등장하는 hard keypoint mining loss 방식은 현재 많은 논문에서 OKHM 이라는 이름으로 불리고 있습니다. Online Keypoint Hard Mining 입니다. 요놈 개념을 다시 찾아보느라 어쩌다 CPN 논문 까지 내려와서 보게 되었네요 😞 다시 보니 또 새롭습니다..
OHKM Loss 가 어떻게 구현되어있는지 아래 코드를 참고하면 좋을 듯 합니다.
class JointsOHKMMSELoss(nn.Module):
def __init__(self, use_target_weight=True, topk=8):
super(JointsOHKMMSELoss, self).__init__()
self.criterion = nn.MSELoss(reduction='none')
self.use_target_weight = use_target_weight
self.topk = topk
def ohkm(self, loss):
ohkm_loss = 0.
for i in range(loss.size()[0]):
sub_loss = loss[i]
topk_val, topk_idx = torch.topk(
sub_loss, k=self.topk, dim=0, sorted=False
)
tmp_loss = torch.gather(sub_loss, 0, topk_idx)
ohkm_loss += torch.sum(tmp_loss) / self.topk
ohkm_loss /= loss.size()[0]
return ohkm_loss
def forward(self, output, target, target_weight):
batch_size = output.size(0)
num_joints = output.size(1)
heatmaps_pred = output.reshape((batch_size, num_joints, -1)).split(1, 1)
heatmaps_gt = target.reshape((batch_size, num_joints, -1)).split(1, 1)
loss = []
for idx in range(num_joints):
heatmap_pred = heatmaps_pred[idx].squeeze()
heatmap_gt = heatmaps_gt[idx].squeeze()
if self.use_target_weight:
loss.append(0.5 * self.criterion(
heatmap_pred.mul(target_weight[:, idx][:, None]),
heatmap_gt.mul(target_weight[:, idx][:, None])))
else:
loss.append(0.5 * self.criterion(heatmap_pred, heatmap_gt))
loss = [(l[None] if l.ndim == 1 else l).mean(dim=1).unsqueeze(dim=1) for l in loss]
loss = torch.cat(loss, dim=1)
return self.ohkm(loss)728x90
반응형