[Paper Review] Occlusion-Aware Networks for 3D Human Pose Estimation in Video
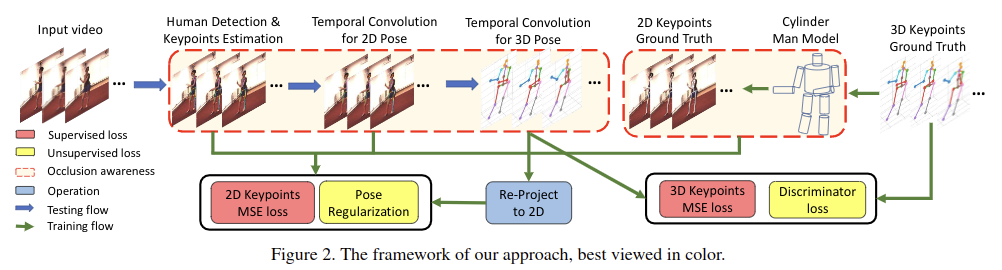
본 논문에서는 3D Human Pose Estimation에서 Occlusion 문제를 해결하기 위하여 occlusion aware deep learning framework 제안합니다. 이를 위해 keypoint의 2D confidence heatmap과 optical flow의 consistency constraint를 사용하여 occluded keypoint의 unreliable estimation을 filtering 합니다. occlusion이 발생하면 incomplete 2d keypoint가 있는 것이기 때문에 이를 2D and 3D temporal convolutional network(TCN)에 제공하여 완전한 3D pose를 생성하기 위해 temporal smoothness를 적용합니다.
complete 하지만 incorrect 한 정보를 제공하는 대신 imcomplete 2d keypoint 정보를 제공함으로써 occluded keypoint 추정의 영향을 덜 받게 됩니다. occlusion aware 3D TCN을 학습하려면 occlusion label이 있는 2D 정보와 3D 정보의 pair가 필요합니다. 이러한 데이터 세트를 사용할 수 없으므로 3D 공간에서 body part의 occupation에 근사할 수 있는 “Cylinder Man Model”을 제안합니다. 모델을 2D 평면에 무관한 viewing angle에 투영함으로써 occluded joint 정보를 얻고, label을 지정하여 많은 학습 데이터를 제공할 수 있습니다. 이러한 방식은 Human3.6M 및 HumanEva-I 데이터세트에서 SOTA를 달성합니다.
본 논문의 주요 Contribution은 아래와 같습니다.
- explicit occlusion handling이 포함된 3D Human Pose Estimation 방법 제안
- 3D pose and occluded 2D pose의 pair의 automatic data augmentation 및 occluded pose regularization를 위한 “Cylinder Man Model” 제안
- semi-supervised 방식으로 end-to-end 학습이 가능한 2d pose 및 3d pose 추정의 fully integrated framework 제안
Cylinder Man Model

- 3D human을 head, torso, two upper arms, two lower arms, two thighs, two lower legs로 나눔, 이러한 approximation 방식은 본 논문의 framework에서 잘 작동함
- GT 또는 3D skeleton이 주어지면 Cylinder를 사용하여 각 10개의 part에 대해 3D Shape을 approximation 시킴
- head의 radius는 10cm로 정의되고, 각 팔 다리의 radius는 5cm로 정의
- 원통의 높이는 해당 part를 정의하는 keypoint 사이의 거리로 정의
- 몸통의 radius는 미리 정의되지 않지만, 목과 어깨 사이의 거리로 정의
- Point P가 Cylinder에 의해 가려졌는지 판단하기 위해서는 orthogonal projection을 가정하여 2D space에 매핑한 뒤, cylinder의 vertical cross section인 ABCD는 직사각형 A’B’C’D’에 매핑됨
- $r_{i, j}$은 cylinder height (i.e., the length of a bone)에 비해 작음, 2D plane에 projection 할 때 ABCD에 의해 P가 가려졌는지 체크
- 만약 projected P가 2D의 A’B’C’D’ 안에 있지 않다면 이는 occlusion 되지 않은 것
- 그렇지 않다면 3D space에서 ABCD의 평면의 norm을 다음과 같이 계산, camera가 가리키는 것을 선택하며, z coordinate는 음수로 나타남
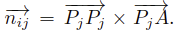
- Point P의 visibility는 다음과 같이 계산됨
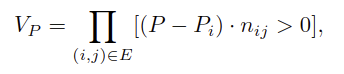
- 여기서 E는 bone을 형성하는 모든 인접 키포인트의 집합이고, [·]은 Iverson bracket을 나타내며, 명제가 참이면 1을 반환하고 그렇지 않으면 0을 반환
- 또한 미분 가능성을 보장하고, 이 연산을 근사화 시키기 위해 sigmoid 함수를 사용
- 그림 4에서 표시된 예시에서 시야 각이 사람 뒤에서 오는 경우 keypoint P는 point O에서 body cylinder에 의해 가려짐
- SMPL과 같은 다른 body model은 사람을 보다 자세히 표현해낼 수 있지만 occlusion 여부를 판단하기 위해 extra computation이 필요함
그러나 Cylinder Man Model을 이용한 top-down approach 기반 방법도 여전히 한계가 있다고 합니다.
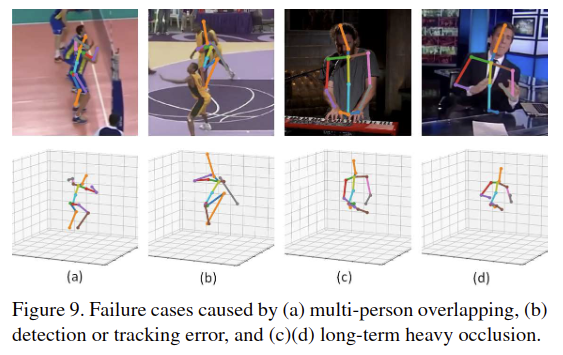
- bbox가 실제 human에게서 너무 많이 벗어나버리면 자세 추정이 실패
- 두 명 이상의 사람이 매우 가깝게 존재할 경우 다른 사람과 구별하지 못할 수 있음
- Cylinder Man Model은 Self-occlusion을 추정하도록 정의되지만 다른 객체에 의한 occlusion을 처리할 수는 없음
- 또한 heavy occlusion 문제를 처리할 수 없음 (심하게 가려진 키포인트를 복구하는데 사용할 수 있는 temporal information은 없음)
실험결과는 아래와 같습니다.


