[Paper Review] PoseDet, Fast Multi-Person Pose Estimation Using Pose Embedding
Paper : https://arxiv.org/pdf/2107.10466.pdf
GitHub : https://github.com/IIGROUP/PoseDet
GitHub - IIGROUP/PoseDet: [FG 2021] Code for PoseDet: Fast Multi-Person Pose Estimation Using Pose Embedding
[FG 2021] Code for PoseDet: Fast Multi-Person Pose Estimation Using Pose Embedding - GitHub - IIGROUP/PoseDet: [FG 2021] Code for PoseDet: Fast Multi-Person Pose Estimation Using Pose Embedding
github.com
이번에 리뷰할 논문은 "PoseDet, Fast Multi-Person Pose Estimation Using Pose Embedding" 입니다.
본 논문에서는 Multi-person pose estimation 방법에서는 일반적으로 body joint의 localization 및 association을 개별적으로 처리하는데, 이는 편리하지만 비효율적이라고 주장하고 있으며, 더 높은 추론 속도로 동시에 body joint를 localization 하고, association을 처리하는 새로운 프레임워크 PoseDet을 제시합니다. 또한 keypoint 위치 측면에서 객체를 나타내는 keypoint-aware pose embedding을 제안합니다. 이러한 pose embedding은 sementic and geometric information 이 포함되어있어서 다양한 포즈에 대한 강력한 예측을 가능하게 한다고 합니다. COCO 벤치마크에서 전례 없는 속도와 경쟁력 있는 정확도를 달성해내며, CrowdPose 벤치마크에 대한 광범위한 실험은 crowd scene에서 robustness 하다는 것을 보여주게 됩니다.
본 논문에서 제안하는 keyopint-aware pose embedding은 다음과 같습니다. 사실 상 이 논문의 핵심 아이디어라고 할 수 있습니다.

본 논문의 contribution은 아래와 같습니다.
- object detection problem으로 multi person pose estimation을 재구성 함. 본 논문에서 제안한 PoseDet 프레임워크는 SOTA approach 에서 전례없는 속도와 경쟁력 있는 정확도를 달성함.
- person instance에 대한 일반적이고 유연한 표현으로 포함된 keypoint-aware pose embedding을 제안하여 PoseDet이 occlusion 및 다양한 포즈가 있는 real-world crowd scene에 강력함. re-identification과 같은 다른 instance-level recognition task에 쉽게 적용 가능함.
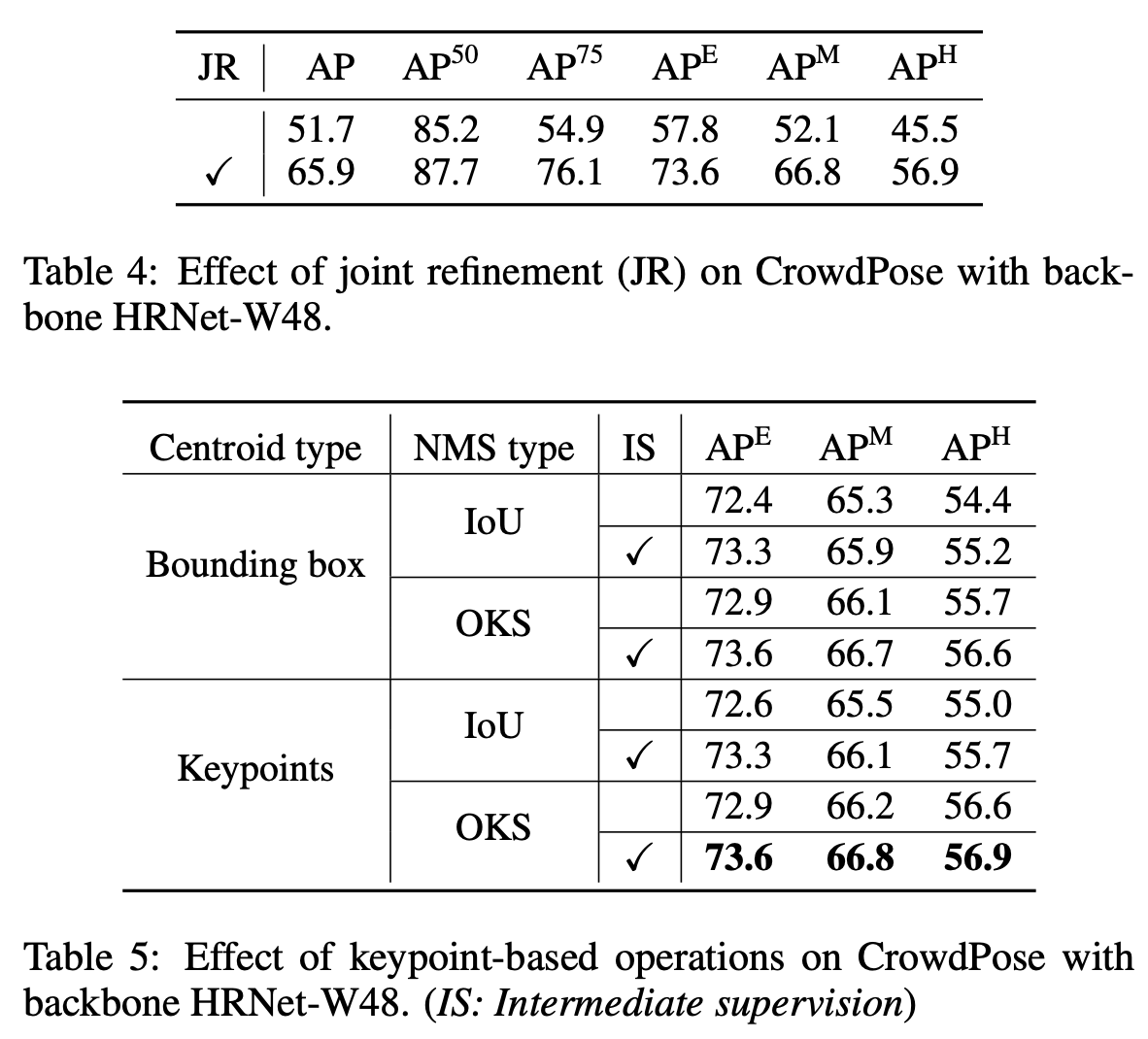
- PoseDet의 성능은 displacement refinement 및 keypoint-based operation으로 더욱 향상됨.
본 논문에서 제안하는 방법은 아래와 같습니다.
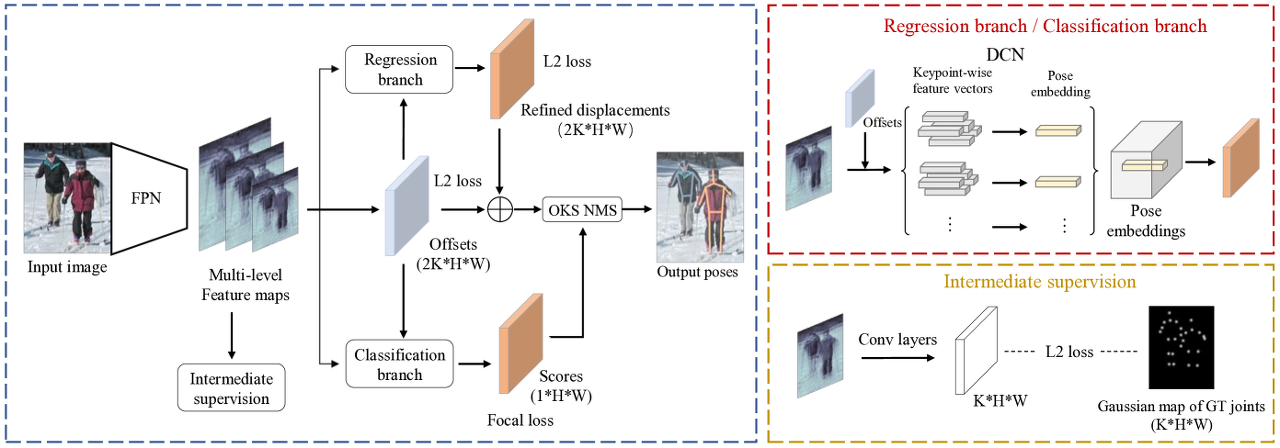
메인 아이디어는 multi-level anchor-free detector를 제안하고, 2d pose를 추정하기 위해 pose embedding을 활용하는 방법을 보여줍니다.
Keypoint-Aware Pose Embedding
먼저, bounding box와 center point에 의해 추출된 feature는 pose estimation을 위해 redundant or limitation 됩니다. 이 시스템에서 object는 keyopint로 표시되며, keypoint의 feature는 classification 및 regression을 위해 extract and aggregate 됩니다. feature map이 주어지면 person instance는 feature map에 인코딩 된 contain semantic and geometric information 이 포함되어 있습니다. 자연어 처리 분야에서 discrete text data는 word embedding을 통해 continuous vector로 표현되어 sementic and syntactic feature을 포착하게 됩니다. 마찬가지로 불규칙한 벡터를 추출하고 집계하여 person instance를 표현하게 되는데, representation은 일련의 벡터에서 pose embedding이라는 이름의 벡터로 mapping 됩니다. 이러한 opse embedding은 shape과 joint의 범주가 모두 확인되었기 때문에 sementic, geometric 정보들을 모두 포함하게 됩니다.
본 논문에서는 DCN layer를 통해 dense pose embedding을 생성하기 위해(CNN은 receptive field 및 다양한 포즈의 제한으로 인해 한계가 있다고 함) offset과 feature map을 입력으로 사용합니다. offset은 각 가설에 대한 2K 차원 벡터로 feature map에서 가설의 위치를 기준으로 K개의 키포인트를 찾아내게 됩니다. DCN은 서로 다른 offset에 따라 각 가설에 대한 pose embedding을 생성하므로 geometric structure의 제한 없이 효율적으로 임의의 위치에 위치하는 feature에 접근 할 수 있습니다.
offset 학습은 DCN 성능에 매우 중요합니다. 다른 연구들에 의하면 fixed offset을 생성하기 위해 가장 일반적인 포즈를 미리 정의된 앵커로 사용했다고도 하네요. 이 작업에서는 GT joint가 supervise 하는 keypoint-aware offset을 생성하기 위해 bypass가 적용되어 offset 학습을 명시적으로 설정합니다. 이를 통해 의미있고, 안정적인 feature를 생성할 수 있습니다. pose embedding은 pose를 추정하기 위해 PoseDet에 적용됩니다. 일반적인 representation 전략으로 joint를 다른 종류의 keypoint로 대체하여 다른 객체로 확장하기 쉽다고 합니다.
PoseDet
PoseDet은 feature extract를 위한 backbone, offset prediction을 위한 bypass, joint localization 및 candidate scoring을 위한 2개의 branch로 구성됩니다. backbone은 FPN으로 single resolution image에서 multi-scale feature pyramid를 생성합니다. object는 scale에 따라 다른 수준으로 할당되며, pose의 scale 다양성 문제를 부분적으로 해결한다고 합니다.
PoseDet은 각 candidate의 pose를 추정하고, 점수를 할당합니다. 그 다음, $F$를 $C$ X $H$ X $W$크기의 single-level feature map이라고 하고, 이 level에서는 가능한 pose를 추정하기 위해 두 branch에서 처리되는 candidate 가 존재합니다. bypass는 offset set을 생성하며, 각 set은 2K 차원 벡터이며, candidate location에서 person instance의 body part까지의 offset을 나타냅니다. FPN에 의해 추출된 predicted offset과 feature map이 주어지면 다른 두 branch는 각각 displacement refinement 및 candidate scoreing을 위한 task-specific pose embedding을 구현합니다. 이는 FPN의 각 level에서 full convolutional network를 이용하여 dense multi-level prediction을 생성한 다음 NMS를 채택하여 redundant prediction을 제거합니다. 그 다음에는 regressing body joints, scoreing candidate에 대해 설명합니다.
Joint Localization
이미지에서 multi person pose는 다음과 같이 나타낼 수 있습니다.
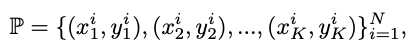
여기서 joint localization 과정은 아래와 같이 나타낼 수 있습니다.
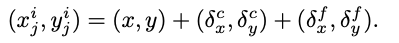
$(x, y)$는 candidate에 대한 좌표 정보이고, 두 번째 항은 coarse displacement, 세번째 항은 refined displacement 입니다. bypass에 의해 predicted offset은 pose embedding을 생성하도록 DCN을 guide 할 뿐 아니라 coarse displacement를 제공하는 pose의 coarse prediction을 제공합니다. regression branch는 2개의 3 x 3 conv layer로 구성되며, pose embedding을 생성하기 위해 deformable convolution layer가 적용됩니다. refined displacement는 pose embedding을 입력으로 사용하는 1 x 1 conv layer를 통해 직접적으로 regression 됩니다.
Candidate Classification
coarse prediction을 기반으로 positive and negative prediction을 분류하여 candidate를 평가합니다. 이 때 OKS(Object Keypoint Similarity)를 metric으로 사용하여 예측 포즈와 GT 포즈 간의 유사성을 평가하게 됩니다. OKS가 0.6 보다 높은 예측은 양수로 나타내고, 0.5 미만은 음수를 나타냅니다. OKS는 동일한 카테고리의 두 관절 사이의 거리 collection 이라고 보면 됩니다.
FPN 이후 classification branch는 2개의 3x3 conv layer와 deformable conv layer로 구성된 candidate scoreing을 위한 pose embedding을 생성하는데 사용됩니다. 그 다음, score를 추정하기 위해 1x1 conv layer가 사용됩니다. predicted score와 pose는 NMS에서 redundant prediction을 억제하는데 사용됩니다.
Intermediate Supervision
FPN의 feature map은 keypoint-aware pose embedding을 생성하기 위해 object representation을 추출하는 person instance의 mapping으로 간주됩니다. 말이 어렵지만, object 와 person 간에 추정을 가능하게 하는 feature map 이라고 보시면 될 것 같네요. FPN이 body joint에 민감하게 동작하도록 만드는데, GT joint로 intermediate supervision을 활용하게 됩니다. 구체적으로는 3x3 conv layer와 1x1 conv layer로 구성된 branch를 추가하여 FPN의 multi level feature map의 입력으로 사용하고, 동일한 resolution의 multi level heatmap을 생성하게 됩니다. heatmap은 채널 수가 관절 수와 동일한 공간 위치에 대한 joint의 확률을 나타내게 됩니다. 다들 아시겠지만 각 level heatmap에 대해 GT joint 위치를 중심으로 2d gaussian map을 생성합니다. 학습 시 pred heatmap과 gt heatmap 사이의 loss를 최소화 하게 됩니다.
Training and Inference
학습 시 Loss는 아래와 같이 정의됩니다.
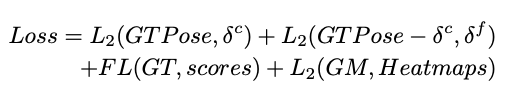
첫번째 항은 bypass loss이며, 이는 L2 loss로 학습되며, 각 candidate에 대한 coarse prediction을 제공합니다. 각 GT pose는 크기에 따라 FPN에 할당되고 GT pose의 중심에 가장 가까운 동일한 수준의 candidate에 할당됩니다. 두번째 항은 coarse prediction을 기반으로 더 delicate pose(섬세한 포즈)를 예측하는 regression branch의 loss 입니다. 이는 L2 loss로 학습됩니다. OKS를 계산한 다음 가장 큰 OKS를 candidate에 할당합니다. OKS가 0.7 보다 높은 것은 L2 loss로 학습됩니다. 세번째 항은 classification branch의 loss입니다. positive 및 negative candidate 모두 focal loss로 학습되며, 클래스 불균형 문제를 해결하게 됩니다. 마지막 항목은 gaussian map과 pred heatmap 사이를 L2 loss로 학습됩니다.
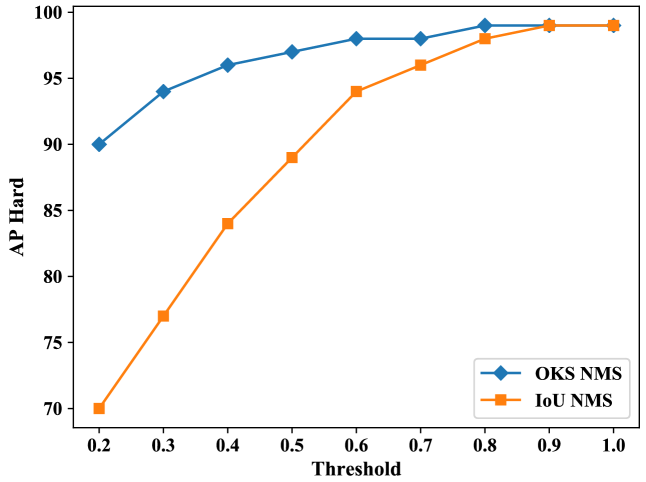
대부분의 modern detection system에서는 IoU를 기반으로 NMS 중첩을 체크하는데, 이는 심하게 가려지는 경우 positive sample을 억제해버리기 때문에 crowd scene에는 적합하지 않다고 합니다 ( ! ) 그래서 OKS로 NMS 측정을 하게 됩니다. 이는 joint 사이의 거리에 따라 달라지므로 유사성에 대해 차별적으로 측정이 가능합니다. 아래 그림과 같이 AP Hard는 가장 많은 crowd를 포함하는 metric으로 채택되며, IoU 기반 NMS는 OKS 기반 NMS 보다 더 많은 positive sample을 잘못 억제시키므로, OKS 기반 NMS 방법이 가려진 사람들을 구별하는데 더 나은 측정임을 보여주게 됩니다. (Threshold 값을 기준으로 보면 0.9 이하로 성능이 두드러짐을 알 수 있네요!)
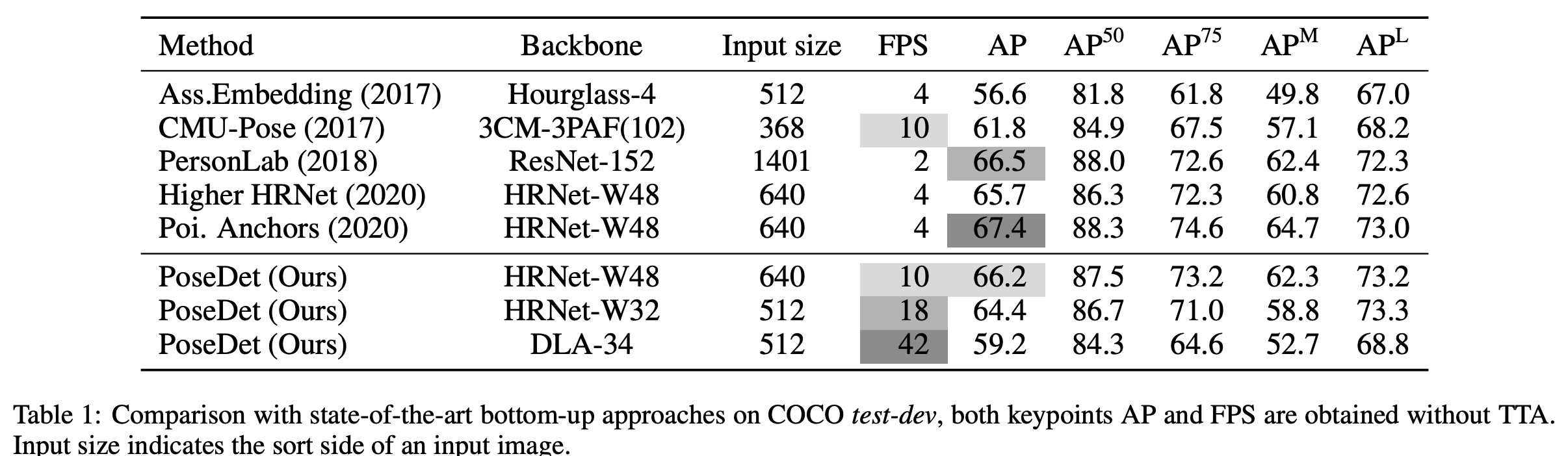
실험 결과는 아래와 같습니다. FPS 및 AP에서 상당 부분 이익임을 증명해주고 있습니다.
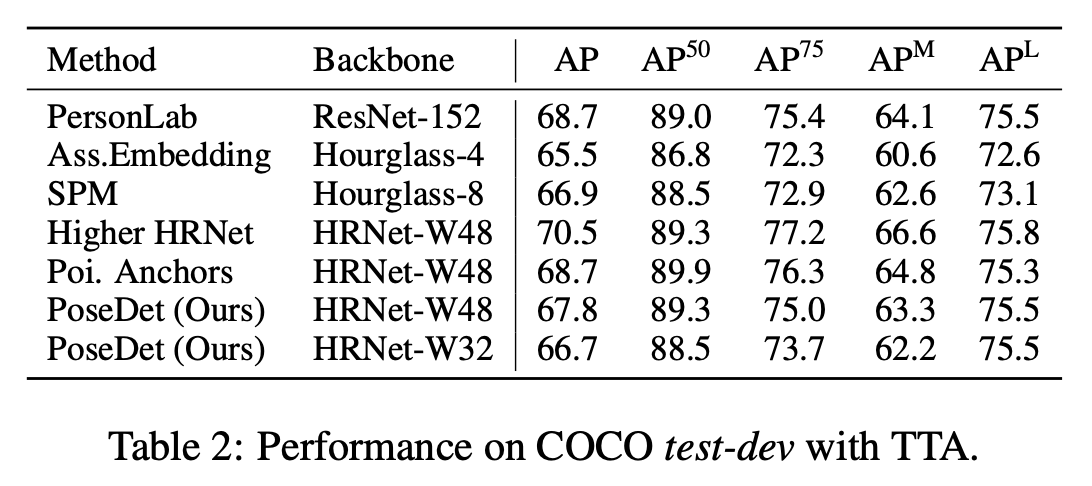
아래는 TTA를 가미한 결과입니다. 참고로 TTA에는 multi-scale testing and flip 가 포함되었다고 합니다.
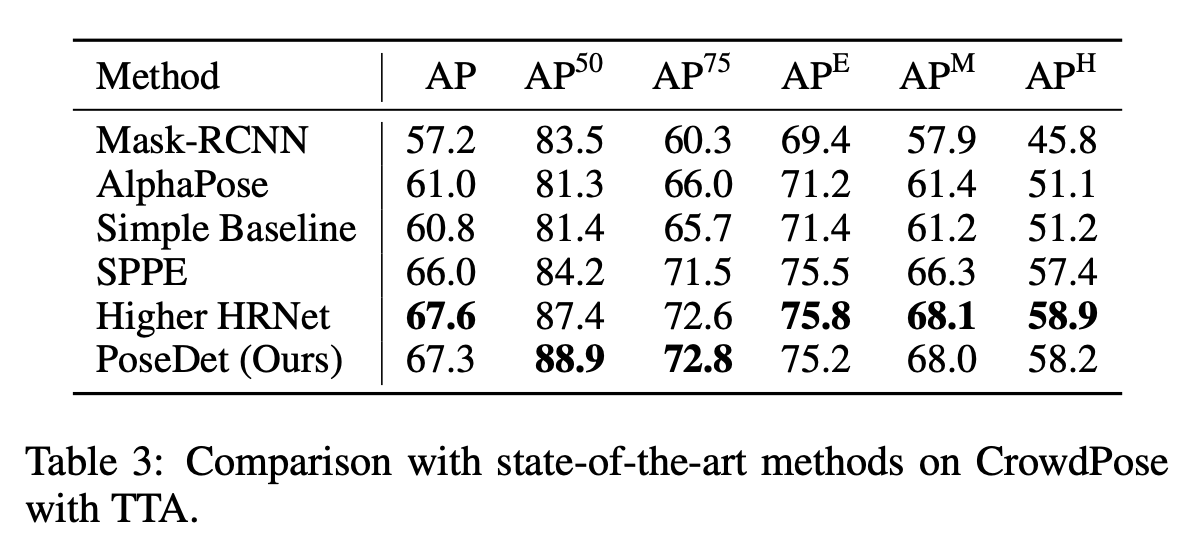
아래 실험 결과는 jonit refinement 에 따른 결과와 centroid type에 따른 결과입니다. 포즈에서는 bounding box를 중복을 처리하는데 있어서 OKS NMS 방법이 효과적이네요.
마지막으로 결과 영상들입니다.


저에겐 유익했던 논문이였네요 헤헷
