[Paper Review] Effective Whole-body Pose Estimation with Two-stages Distillation
Paper : https://arxiv.org/abs/2307.15880
Effective Whole-body Pose Estimation with Two-stages Distillation
Whole-body pose estimation localizes the human body, hand, face, and foot keypoints in an image. This task is challenging due to multi-scale body parts, fine-grained localization for low-resolution regions, and data scarcity. Meanwhile, applying a highly e
arxiv.org
GitHub : https://github.com/IDEA-Research/DWPose
GitHub - IDEA-Research/DWPose: "Effective Whole-body Pose Estimation with Two-stages Distillation" (ICCV 2023, CV4Metaverse Work
"Effective Whole-body Pose Estimation with Two-stages Distillation" (ICCV 2023, CV4Metaverse Workshop) - GitHub - IDEA-Research/DWPose: "Effective Whole-body Pose Estimation with Two...
github.com
Overview
드디어 RTMPose를 뛰어넘는 논문이 나왔습니다. 오늘 리뷰할 논문은 Distillation for Whole body Pose estimators, named DWPose 입니다. Distillation for Whole-body Pose estimators, named DWPose 라는 논문입니다. 일단 저자 소개 페이지를 보시면 많은 인사이트를 얻을 수 있습니다.
first-stage distillation 및 second stage distill로 이루어지는데, 첫번째 단게에서는 visible, invisible keypoints가 모두 있는 teacher’s intermediate feature과 final logits을 활용하면서 weight-decay strategy을 설계합니다. 그 다음 두번째 단계에서는 성능을 더 향상시키기 위해 student model 자체를 distillation 시킵니다. 이 단계는 plug-and-play train strategy로 단 20%의 training time으로 student’s head를 finetuning 시킬 수 있습니다.
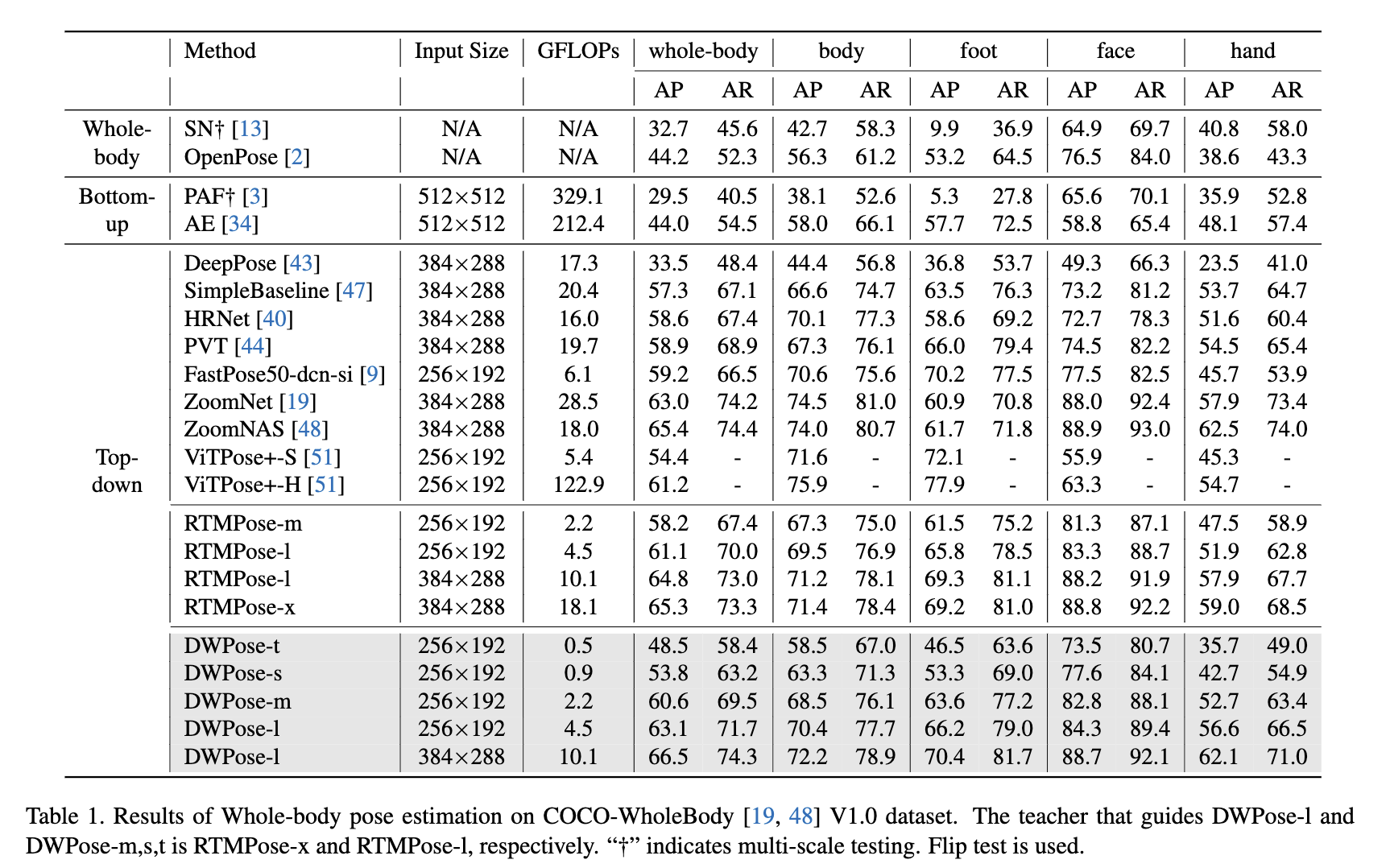
아래 그래프를 보시면 COCO-WholeBody 데이터세트에서 눈에 띌 만큼 성능이 좋다는 것을 보실 수 있습니다.

Method
우선 논문에서는 two-stage pose distillation (TPD)에 대해 설명합니다. 아래 그림에서도 볼 수 있듯, 2가지 단계로 구성됩니다. 1단계에서는 feature 및 logit 수준에서 처음부터 student를 guiding 하는 pre-trained teacher가 있습니다. 그 다음 2단계에서는 self-KD 방식을 사용합니다. 자체 logit을 이용하여 레이블이 지정된 데이터 없이 head를 학습함으로서 간단하게 학습을 하되 상당한 성능 향상을 갖고옵니다.

1. The First-stage distillation
먼저,teacher와 student에서 나온 특징을 $F^t$, $F^s$라고 표시하고, 이들의 final output logit을 $T_i$, $S_i$라고 표시합니다. 1단계 distillation에서는 student가 teacher's feature $F^t$와 logit $T_i$을 강제로 학습하게 합니다.
Feature-based distillation
이 때는 MSE loss를 사용합니다. 아래 식과 같이 나타낼 수 있습니다. 여기서 소문자 $f$는 $F^s$와 $F^t$를 동일한 차원으로 reshape하기 위한 $1x1 conv layer를 뜻하고, H, W, C는 teacher의 height, width, channel을 뜻합니다.

Logit-based distillation
RTMPose는 keypoint localizjation을 수평 및 수직 좌표에 대한 분류 작업으로 처리하는 SimCC 기반 알고리즘으로 포인트를 예측하게 됩니다. 이 설계에 따라 logit-based knowledge method 방법을 적용할 수 있습니다. RTMPose에서 사용하는 original classficiation loss는 다음과 같습니다.
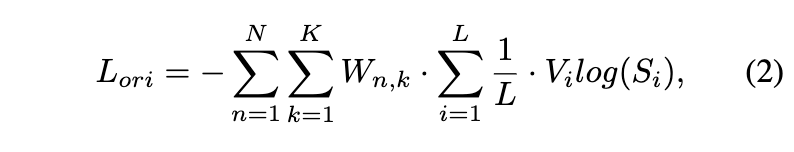
여기서 N은 batch에서 person sample을 뜻하고, K는 keypoint num 입니다. COCO-WholeBody의 경우 133개가 되겠네요. 또한 L은 x or y의 location bin입니다. $W_{n,k}$는 distinguish invisible keypoint를 위한 target weight mask 입니다. $V_i$는 label value 입니다.
logit-based distillation의 경우 원래 손실인 위 손실을 따릅니다. distillation을 위해 target weight mask W를 drop 한다는 것은 주목할 가치가 있다고 하네요. (? 이 부분이 잘 이해가 가지 않습니다...)
레이블 값과 달리 보이지 않는 keypoint도 teacher 가 합리적인 값으로 분배할 수 있다고 합니다. 마치 confidence와 같은 것이죠. 그래서 logit의 distillation loss는 다음과 같이 정의 될 수 있습니다.
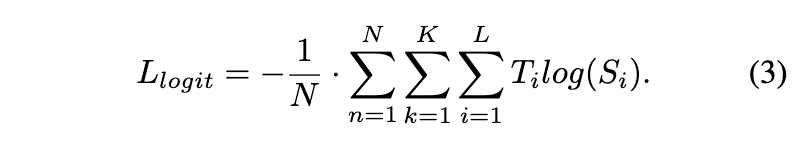
Weight-decay strategy for distillation
feature distillation loss $L_{fea}$와 logits distillation loss $L_{logit}$은 다음과 같이 조절됩니다. 여기서 알파와 베타는 하이퍼파라미터입니다.
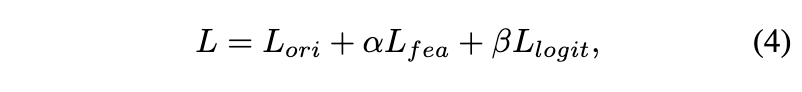
detection distillation 방법인 TADF에서 영감을 받아 distillation에 대한 weight-decay strategy을 적용하여 distillation penalty를 점진적으로 줄인다고 합니다. 이 전략은 student label에 더 집중하고 더 나은 성능을 달성한다고 하네요. 그래서 이를 위해 시간 함수 $r(t)$를 사용하게 됩니다. 여기서 $t$는 current epoch을 뜻하고 $t_{max}$는 total epoch을 뜻합니다.
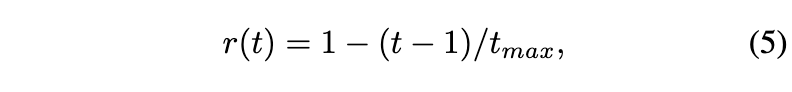
그리하여 First-stage distillation의 total loss는 다음과 같이 정의됩니다.
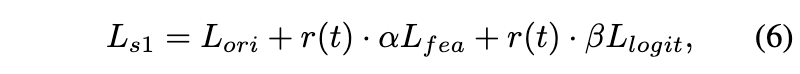
2. The Second-stage distillation
그 다음 단계에서는 학습된 student model을 이용하여 더 나은 성능을 위해 self로 학습하게 합니다. 이러한 방식으로 distillation을 통해 처음부터 학습이 되었는지 여부에 관계없이 student model을 개선할 수 있습니다. pose estimator는 encoder, decoder 구조로 구성됩니다. 학습된 모델을 기반으로 먼저 학습된 backbone과 그렇지 않은 head를 가진 student를 만듭니다. teacher는 학습된 backbone과 head를 가진 동일한 모델이라고 보시면 됩니다. 학습하는 동안 student’s backbone을 고정하고 head를 업데이트 하는 방향으로 학습됩니다. 둘 다 동일한 아키텍처를 가지고 있기 때문에 backbone에서 feature를 한 번만 추출하면 됩니다. 그러면 feature는 teacher의 학습된 head와 학습되지 않은 student의 head에 공급되어 각 logit $T_i$와 $S_i$를 얻게 됩니다.
식 3에 따라 2단계 distillation을 위해 $L_{logit}$으로 student를 학습합니다. 레이블 값으로 계산되는 origin loss를 삭제한다는 점은 주목할만한 가치가 있다고 하네요. loss scale에 대한 하이퍼파라미터를 나타내기 위해 γ 를 사용하면 second-stage distillation의 최종 손실은 다음과 같이 공식화 할 수 있습니다.
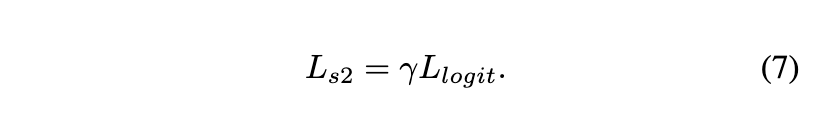
이는 기존의 self-KD 방법과 달리 head-aware distillation 방법은 단 20%의 학습 시간으로 head에서 지식을 효율적으로 추출하고 localization capability를 더욱 향상시킬 수 있습니다.
Experiments
실험을 위해 데이터세트는 Ubody, COCO를 사용했다고 합니다. detector는 SimpleBaseline에서 사용된 것을 썼습니다. 참고로 UBody는 15개의 실제 시나리오에서 1백만 개 이상의 프레임으로 구성됩니다. 해당하는 133개의 2d 키포인트와 SMPL-X 매개변수를 제공하고, 특히 원본 데이터 세트는 3D whole- body estimation 에만 초점을 맞추고 2D annotations의 효과를 검증하지 않습니다. training and testing에 사용되는 비디오에서 10프레임 간격으로 모든 프레임을 선택하여 생성되었습니다. 또한 논문을 보시면 Implementation details이 나와있습니다.

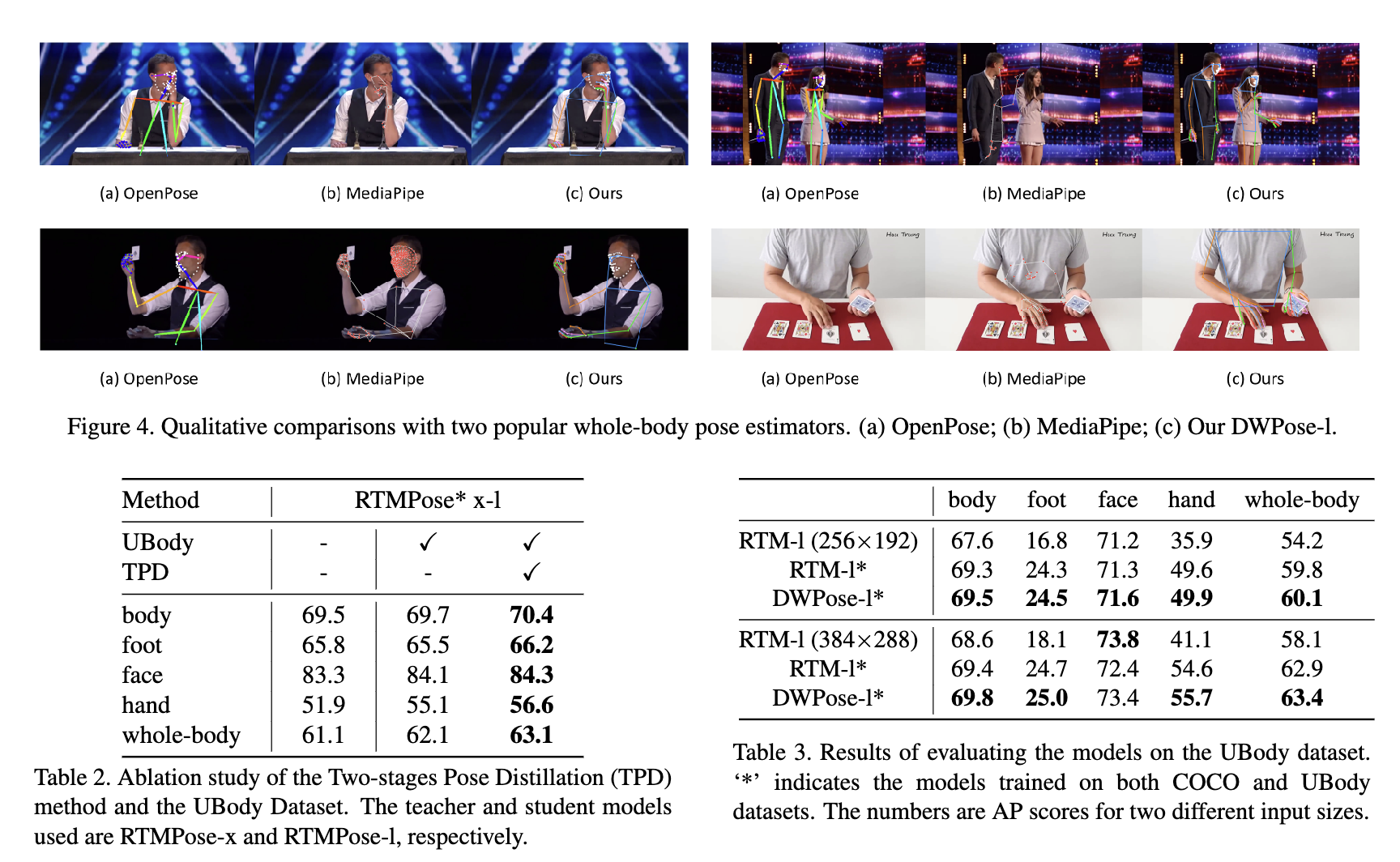
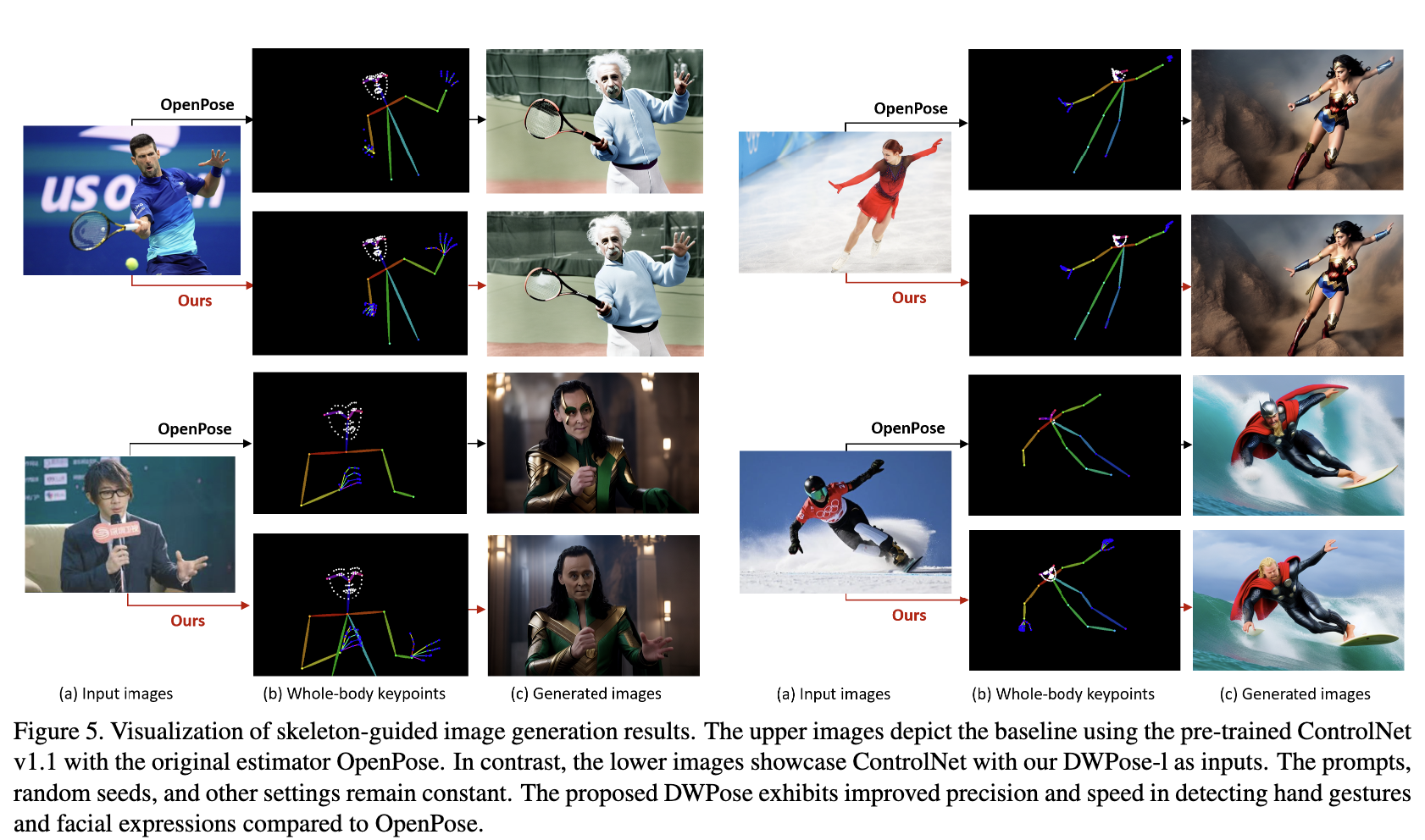
디퓨전 분야에서 source로 OpenPose를 채택했었는데, 이제 앞으로 DWPose를 채택해볼 수 있을 것 같네요!
저자들도 그걸 목표로 두고 있다고 합니다. 앞으로 DWPose를 이용한 디퓨전 연구 결과가 기대가 되네용.
