[Paper Review] MobileHumanPose : Toward real-time 3D human pose estimation in mobile devices
이번에 읽게된 논문은 CVPR 2021에 소개된 MobileHumanPose: Toward real-time 3D human pose estimation in mobile devices 입니다. 참고로 카이스트에서 게재한 논문이며, 3D Human Pose Estimation 모델을 Mobile Device에서 작동 될 수 있도록 경량화 한 논문입니다.
Contribution
본 논문에서의 주요 Contribution은 아래와 같습니다.
- 기존 3D HPE 방법들이 높은 computing cost + 정확도에 초점을 맞췄던 것에 비해 본 논문에서는 모바일 기반 모델 효율성을 다룸
- MobileNet v2 수정, parametric activation function, Skip concatenation (U-Net 참조) 구조 제안, 이는 computing cost를 줄이고, 좋은 성능을 달성함
Introduction
보통 딥러닝에서 모델의 성능은 wider channel size 또는 deeper convolution layer를 통해 성능을 높일 수있는데, 이는 computing cost가 높아져 모바일 환경과 같이 리소스가 제한된 장치에서는 적합하지 않다고 합니다. 특히 skip concatenation 구조는 무시할 정도의 computational power로 rich feature를 propagation 하여 정확도를 향상시킨다고 합니다. 이러한 모델은 SOTA와 비슷한 성능을 달성하며, ResNet-50 모델에 비해 모델 크기가 7배 정도 작다고 합니다. Galaxy S20 CPU에서 12.2ms 정도 추론 시간을 단축 시킬 수 있고, 모바일 환경에서 real-time으로 3D Human Pose Estimation을 추정한다고 하네요.
또한 논문을 게재할 당시 3D HPE 논문에서 모델 효율성 문제를 다룬 연구는 단 두 편 뿐이고, 각각 아래와 같은 단점이 있다고 합니다.
- 2020, Towards part-aware monocular 3d human pose estimation: An architecture search approach
- differential architecture search (DARTS) 방법은 3D human pose estimation 구조를 효과적으로 탐색 할 수 있음
- 하지만 모바일 장치에서 실행하기에는 parameter와 computing cost가 상당함

- 2020, Lightweight 3d human pose estimation network training using teacher-student learning.
- parameter, computing cost, FLOPS를 효율적으로 고려함
- 그러나 성능이 다른 SOTA 방식에 비해 떨어짐


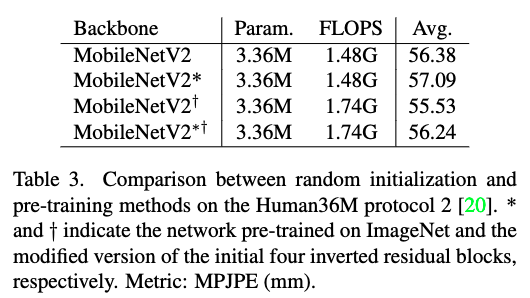
그래서 이러한 한계를 극복하기 위해 성능과, computing cost를 모두 고려한 mobile-friendly network를 제안했다고 합니다. 이 때 모델을 설계 할 때 기존 MobileNetV2 같은 backbone이 image classification task에 대해 잘 학습이 되었지만 3d HPE 작업에 대해서는 fine-tuning 문제가 있다고 하네요. 그래서 이러한 문제를 해결하기 위해 아래 그림과 같이 random initialization 모델을 사용했다고 합니다. 즉, 어떠한 데이터에서도 사전 훈련되지 않은 모델인거죠. 그 외에도 4개의 inverted residual block, activation function 에서 채널 수를 조정하고, skip concatenation을 추가했다고 합니다.

Issue of initialization
대부분의 3D HPE에서는 ImageNet 데이터세트에서 pre-trained model을 사용하는데, Kaiming He 연구에서는 random initialization 된 네트워크가 ImageNet 데이터 세트로 pre-trained model 보다 결과가 나쁘지 않다는 점을 발견했다고 합니다. 이렇게 random initialization을 하게 될 경우 Human36M 데이터로 MPJPE(mm)를 측정했을 때 성능이 더 좋다고 하네요. 참고로 이 논문은 Scratch(w/o pre-training) 학습을 해도 충분히 좋은 성능을 낼 수 있음을 증명한 논문이며, 강한 data augmentation을 사용할 경우 pre-training 보다 init weight 성능이 높고, 데이터세트가 많을수록 rand init의 성능이 pre-training 성능 보다 좋다고 하네요.

MobileHumanPose
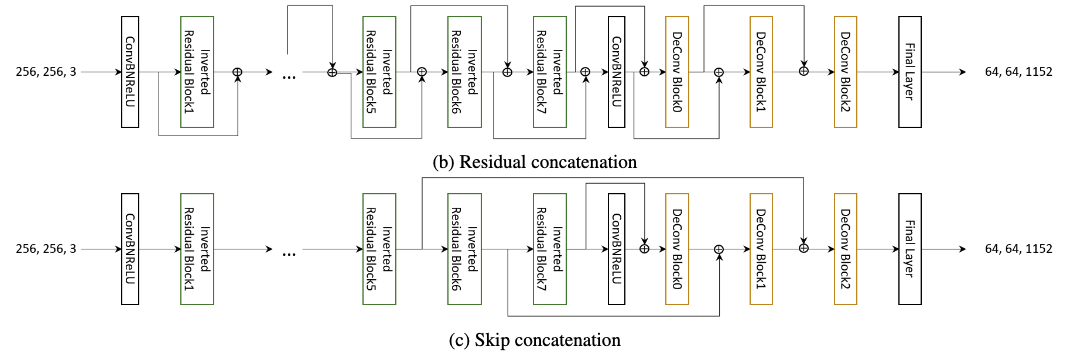
MobileHumanPose의 모델 구조는 encoder가 global feature를 추출하고, decoder가 pose를 추정하는 구조로 이루어지는데, 여기서 backbone block 자체와 activation function이 포함되어있는 처음에 나오는 4개 inverted residual block에서 채널 크기를 수정하고 U-Net의 skip concatenation을 구현했다고 하네요.

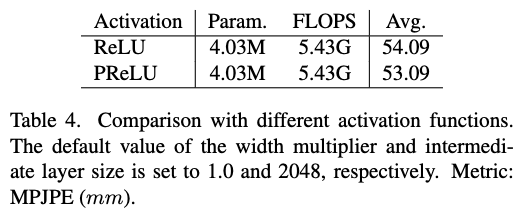
activation function은 Parametric ReLU (PReLU)을 사용했다고 합니다. 이는 pose estimation task에서 성능이 향상됨을 보여주었고, ReLU와 달리 학습 가능한 parameter가 있기 때문에 각 layer에서 정보를 도출하면서 학습할 수 있다고 합니다. 여기서 $a_i$와 $y_i$는 learnable parameter 와 input signal 입니다. 즉 음수에 대한 gradient를 변수로 두고 학습을 통하여 업데이트 시키자는 컨셉입니다. 이 값에 따라 ReLU, LeakyReLU, PReLU 형태가 됩니다. $a_i$가 0이면 ReLU, 0보다 크면 LeakyReLU, 학습 가능하면 PReLU가 됩니다.

Skip concatenation
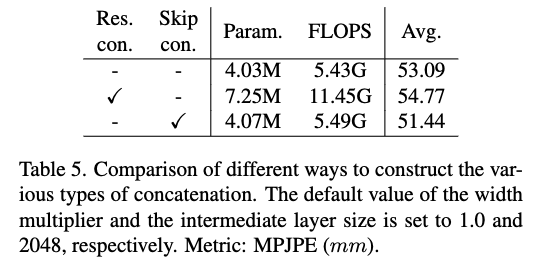
PyTorch에서 대부분의 함수(Conv2D, ReLU)는 FLOPS 계산이 됩니다. 추론 속도 관점에서 FLOPS으로 계산되지 않는 Concat, Bilinear 함수를 적절하게 사용하는게 중요하다고 하네요. Residual concatenation과 skip concatenation 구조를 제안합니다. residual concatenation을 위해 encoder 부분에서 차원을 일치 시키기 위해 average pooling 함수를 사용하고 decoder 부분에서는 bilinear function을 사용합니다. skip concatenation에서는 동일한 차원을 가지는 2개의 서로 다른 ouput의 pure concatenation을 사용합니다. 어떤 논문에서는 residual concatenation 과정에서 연결 과정이 완전하게 수행되지 않는 경우가 발생 할수도 있기에 성능이 저하 될 수 있다고 하여 본 논문에서는 skip concatenation 구조를 채택 했다고 하네요.
Loss
loss function은 L1 Loss를 사용합니다.
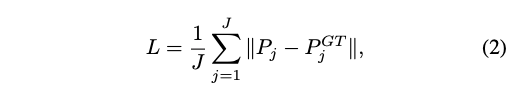
Experiments
MobileHumanPose model은 MuCo-3DHP, COCO 데이터 세트로 2개의 NVIDIA TITAN RTX GPU로 25 epoch 동안 학습했으며, 3일이 걸렸다고 하네요. 표3을 보시면, imagenet에서 pre-trained model을 사용한 결과 보다 성능이 좋은걸 볼 수 있습니다.
또한 PReLU를 사용하면 파라미터 수, FLOPS은 같은데도 불구하고 MPJPE가 2.65mm 정도 좋아집니다.
확실히 Residual 계열이 파라미터수도 많고, FLOPS 수도 높습니다. 성능은 제일 낮네요. 확실히 skip con 방식이 성능 향상에 도움을 줍니다.
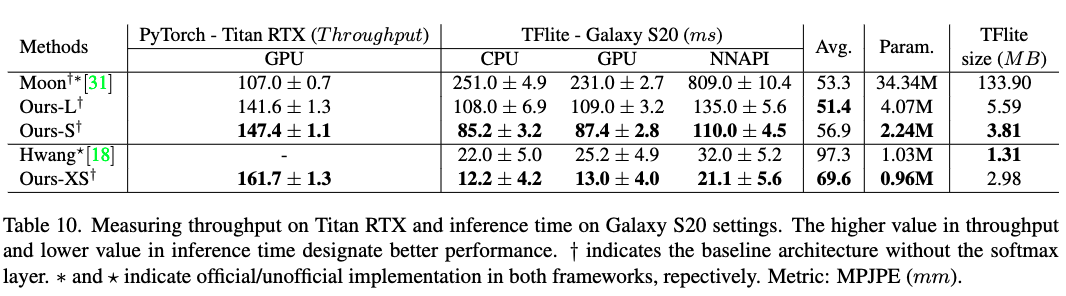
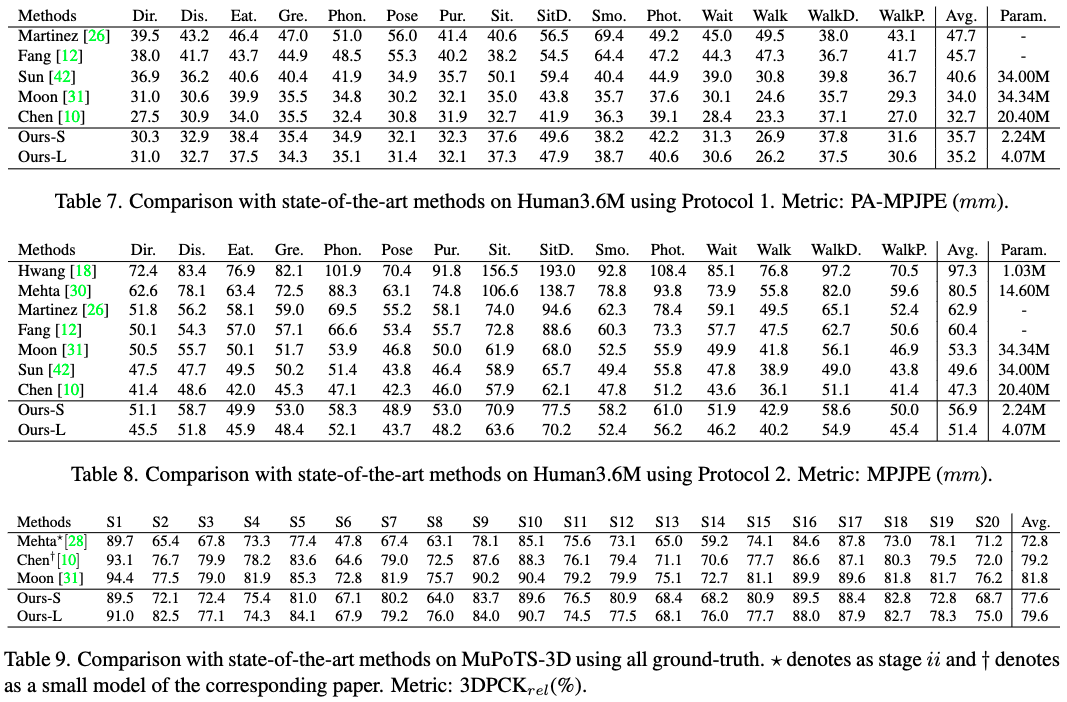
각 Human3.6M, MuPoTS-3D 데이터세트에서 평가한 결과입니다. MPJPE 51.4 ~ 56.9mm 정도 되네요.
Throughput은 아래와 같이 측정했으며, N은 iteration, T는 whole inference time, B는 optimal batch size 입니다. 추론 시간은 아래와 같습니다. 근데 여기서 Ours-XS 모델이 등장하는데 이거에 관련된 MPJPE 정확도는 없네요.
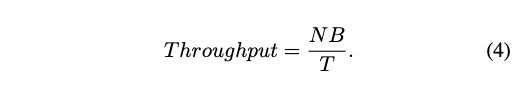
추론 시간은 아래와 같습니다. 근데 여기서 Ours-XS 모델이 등장하는데 이거에 관련된 MPJPE 정확도는 없네요.