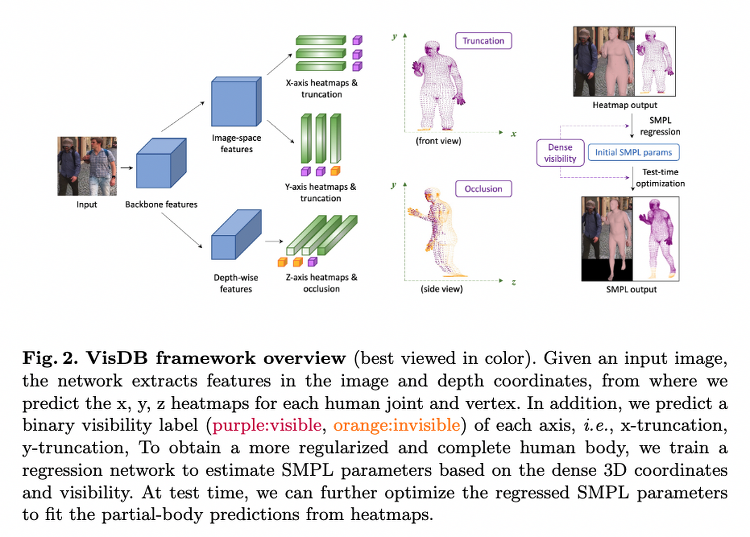
[3D HPS] Learning Visibility for Robust Dense Human Body Estimation
이번에 리뷰할 논문은 "Learning Visibility for Robust Dense Human Body Estimation" 입니다. 본 논문에서는 human joint에 대해 visible 정보를 x, y, z 축에 대해 명시적으로 모델링 했습니다. x, y 축의 visible 정보는 frame 밖에 있는 경우를 구별하는데 도움이 되며, z 축의 visible 정보는 self-occlusion 또는 occlusions by other object을 구별하는데 도움이 됩니다. 본 논문에서는 이러한 정보를 이용하여 3d heatmap을 예측합니다. dense heatmap -based representation은 image domain에서 spatial-relationship을 보존하고, uncert..
2023.05.23