[Paper Review] FCOS, Fully Convolutional One-Stage Object Detection
이번에 리뷰할 논문은 바로 FCOS: Fully Convolutional One-Stage Object Detection 입니다.
이 논문은 2019년에 나왔으며, Anchor box 기반 검출기 만큼의 정확도를 달성하는 Anchor Free 기반 검출기의 baseline이 되는 논문이기 때문에 리뷰하게 되었습니다! (사실 CornerNet이 먼저이긴 하지만, CornerNet은 더 복잡한 post-processing 절차가 필요하다고 하네요!)
기존 객체 검출(Object Detection) 분야에서 대장을 이루었던 YOLO v3를 비롯하여 RetinaNet, SSD, Faster R-CNN 등의 객체 검출기들은 Anchor box를 사용하는데 비해, FCOS는 One-stage Detector이기 때문에 Anchor box를 사용하지 않습니다.
FCOS는 미리 정의가 필요한 Anchor box를 사용하지 않기 때문에 최종 검출 성능에 영향을 미칠 수 있는 Anchor box와 관련된 하이퍼 파라미터들도 사용할 필요가 없습니다. 또한 후처리(post-processing)로는 유일하게 NMS(Non-Maximum Suppression)만을 사용하여 ResNeXt-64x4d-101을 사용하는 FCOS는 single-model, sigle-scale testing에서 AP 44.7%을 달성했다고 하네요! 그럼 Anchor box를 사용하지 않고도 어떻게 객체 검출을 하였는지 살펴봅시다 😋
1. Introduction
객체 검출은 컴퓨터 비전에서 기본적이지만 어려운 작업이며, 객체 검출 알고리즘은 이미지에서 관심있는 각 인스턴스(Instance)에 대해 어떤 객체인지 분류하며, 그 객체가 이미지에서 어디에 위치하고 있는지 bounding box로 예측을 하게 됩니다.
Faster R-CNN, SSD, YOLO v2, v3 과 같은 현재 나와있는 객체 검출기들은 미리 정의된 Anchor box 세트에 의존하는 경향이 있으며, 여태껏 Anchor box의 사용이 객체 검출의 핵심이라고 여겨져왔습니다. 하지만 이러한 검출기는 몇 가지 단점이 존재합니다.
📌 Anchor box의 크기(size), aaspect ratio, Anchor 갯수에 민감하다는 점
예를 들면 RetinaNet에서 Anchor와 관련된 하이퍼 파라미터를 변경하면 COCO 벤치마크에서 AP 4% 정도의 영향을 미친다고 합니다. 그래서 이러한 Anchor 기반 객체 검출기들은 신중하게 조정될 필요가 있었습니다.
📌 Anchor의 scale과 aspect ratio가 고정되어 있다는 점
그래서 작은 객체의 경우 모양 변화(shape variation)가 큰 객체의 후보(candidate)를 처리하는데 어려움을 겪게 됩니다. 이러한 다양한 객체 크기나 종횡비를 가진 작업에 대해 Anchor box들을 다시 설정 해야하기 때문에 “일반화”하기 힘들다는 단점이 있습니다.
📌 High recall rate를 위해 입력 영상에 Anchor box를 조밀하게 배치해야 한다는 점
예를 들어 단축(짧은 변)이 800인 이미지의 경우 FPN(Feature Pyramid Networks)은 약 180K 이상의 Anchor 가 필요하게 됩니다. 이러한 Anchor box들은 대부분 학습 중에 negative sample로 레이블이 지정됩니다. 이러한 과도한 negative sample들은 학습에서 positive sample 과 negative sample 간의 불균형을 야기하게 됩니다.
📌 Anchor box는 ground-truth bounding box를 사용하여 IoU(Intersection-over-union) 계산을 한다는 점
이는 아주 복잡한 계산을 많이 하게 됩니다.
또한 최근 FCN(Fully Convolutional Networks)은 semantic segmentation, depth estimation, keypoint detection, counting 분야에서 엄청난 성능을 보여주었습니다. high-level vision tasks 중 하나인 객체 검출은 Anchor box의 사용으로 인하여 위와 같은 FCN 계열에 껴들 수 없는 존재였습니다. 그래서 본 논문에서는 아주 심플한 FCN 기반 검출기가 Anchor 기반 검출기보다 훨쓴 더 나은 성능을 달성한다는 것을 보여주게 됩니다!
이러한 FCN 기반 프레임워크는 feature map 단계의 spatial location에서 4D vector와 class category를 직접 예측하게 됩니다. 다음 그림 1의 왼쪽에서 볼 수 있듯 4D vector는 bounding box의 네 개의 면에서 객체의 위치 까지 상대적인 offset을 나타냅니다. 이러한 프레임워크는 각 위치가 4D continuous vector를 regress 해야한다는 점을 제외하고서 semantic segmentation을 위한 FCN과 유사한 모습을 보여주게 됩니다.

유사한 연구 DenseBox 방법은 다른 크기의 bounding box를 처리하기 위해 학습 영상을 고정된 크기로 자르고 크기를 조정하게 됩니다. 따라서 DenseBox는 image pyramid 에 대한 검출을 수행해야하며, 이는 모든 convolution을 한 번 계산한다는 철학에 어긋나게 됩니다. 참고로 이러한 방법은 scene text detection, face detection과 같이 highly overlapped bounding boxes 가 존재하는 특수한 도메인에서 사용됩니다. 그림 1의 오른쪽에서 볼 수 있듯 중첩이 상당히 일어난 bounding box는 겹치는 영역의 픽셀에 대해 regress 할 bounnding box를 결정하기 어렵다는 문제가 있습니다.
이 논문에서는 이러한 문제를 자세히 다루고, FPN을 사용하여 이러한 어려운 문제를 해결할 수 있음을 보여주며, 결과적으로 Anchor 기반 검출기와 유사한 정확도를 얻을 수 있다는 것을 보여줍니다. 또한 이러한 방법이 대상 객체 중심에서 멀리 떨어진 위치에서 low-quality predicted bounding box를 생성할 수 있다는 것을 발견하였고, 이러한 문제를 해결하기 위해 해당 bounding box의 중심에 대한 픽셀의 편차(deviation)를 예측하는 “centerness” 개념을 소개합니다.
이 score는 low-quality를 가지는 bounding box의 weight를 낮추고, NMS에서 검출 결과를 병합하는데 사용됩니다. 이렇게 간단하면서도 효과적인 centerness branch를 통해 FCN 기반 검출기는 Anchor 기반 검출기보다 성능이 뛰어나다는 것을 보여주게 됩니다.
FCOS의 장점을 정리하자면 다음과 같습니다.
📌 객체 검출 문제는 semantic segmentation 등과 같이 FCN 프레임워크를 사용할 수 있게 되므로, 다양한 작업들과 통합하여 재사용 될 수 있습니다.
📌 Proposal Free 및 Anchor Free 라서 파라미터의 수가 크게 줄어듭니다. 이러한 파라미터들은 heuristic tuning 이 필요하며, 좋은 성능을 달성하기 위해서 많은 trick이 필요합니다. 또한 Anchor Free 기반 검출기는 학습이 비교적 단순해집니다!
📌 Anchor box를 제거함으로써 IoU 계산과 같은 Anchor box와 관련된 복잡한 계산들을 더 이상 하지 않아도 되고, 학습 중 Anchor box와 GT-box 간의 매칭을 할 필요가 없으므로 더 빠른 학습과 테스트를 수행 할 수 있습니다.
📌 FCOS는 SOTA를 달성합니다. 또한 이 FCOS는 two-stage 검출기에서 RPN(Region Proposal Networks)로 사용 될 수 있으며, Anchor 기반 RPN 방법 보다 훨씬 더 나은 성능을 보장합니다.
📌 제안된 검출기는 instance segmentation 및 keypoint detection을 포함하여 최소한의 수정으로 다른 vision 관련 task들을 해결 할 수 있도록 확장이 가능합니다. 그래서 FCOS는 many instance-wise prediction 문제에 대한 새로운 baseline이 될 것 이라고 하네요!
2. Related Work
Anchor-based Detectors
Anchor 기반 검출기는 Fast R-CNN과 같은 전통적인 sliding-window 및 proposal 기반 검출기의 아이디어에서 시작하며, Anchor box는 bounding box 위치 예측을 개선시키기 위해 extra offsets regression과 함께 positive 또는 negative patch로 분류되는 pre-defined sliding windows 또는 proposal으로 정의 됩니다. 따라서 이러한 검출기의 Anchor box는 training sample로 볼 수 있으며, 각 sliding windows/proposal의 image feature를 반복적으로 계산하는 Fast RCNN과 같은 검출기와는 달리 Anchor box는 CNN의 feature map을 사용하고 반복적인 feature 계산을 하지 않고 검출 프로세스 속도를 크게 높이게 됩니다. Anchor box를 설계하는 것은 Faster R-CNN의 RPN, SDD, Yolo v2에 의해 대중화되었으며 검출 모델의 baseline이 되어왔습니다.
그러나 위에서 설명한 것 처럼 Anchor box는 지나치게 많은 하이퍼 파라미터들을 생성하게 되며 일반적으로 우수한 성능을 달성하기 위해서는 미세하게 이를 조정해야한다는 단점이 있습니다. Anchor shape을 설명하는 하이퍼 파라미터 외에도 Anchor 기반 검출기는 Anchor box에 positive, ignored 또는 negative sample로 레이블을 지정하는 하이퍼 파라미터도 필요합니다. 이전에는 Anchor box의 레이블을 결정하기 위해 Anchor box와 GT-box 사이의 IoU를 사용하게 됩니다. 이러한 파라미터는 최종 정확도에 큰 영향을 미치게 되며 heuristic tuning이 필요하게 됩니다.
Anchor-free Detectors
가장 널리 알려진 Anchor-free 검출기는 YOLO v1 일 수 있습니다. Anchor box를 사용하는 대신 YOLO v1은 객체 중심 근처 지점에서 bounding box를 예측하게 됩니다. 더 높은 품질의 검출을 생성할 수 있는 것으로 간주되기 때문에 중앙에서 가까운 지점만을 사용하게 됩니다. 그러나 이는 중심 근처의 지점만 bounding box를 예측하는데 사용되기 때문에 YOLO v1은 YOLO v2 에서 언급한 것 처럼 low recall을 보입니다. 결과적으로 YOLO v2는 Anchor box를 사용합니다. YOLO v1과 비교하여 FCOS는 GT box의 모든 지점을 이용하여 bounding box를 예측하고, low-quality의 bounding box는 제안된 “centerness”로 처리 됩니다. 결과적으로 FCOS는 Anchor 기반 검출기와 비슷한 recall을 제공합니다.
CornerNet은 bounding box의 pair of corners를 검출하고 그룹화 하여 객체를 검출하는 SOTA Anchor-free 검출기입니다. 이는 동일한 인스턴스에 속하는 pair of corners를 그룹화 하기 위해 훨씬 더 복잡한 post-processing을 거치게 됩니다. 또한 DenseBox 라는 것도 있습니다. 이는 overlapping bounding box를 처리하기 어렵고 recall이 상대적으로 낮기 때문에 일반 객체 검출에 적합하지 않은 것으로 나타났습니다.
3. Our Approach
FCOS는 per-pixel prediction 방식으로 Object Detection을 재구성하며, multi-level prediction을 사용하여 recall을 개선하고 overlapped bounding box로 인한 모호성을 해결하는 방법을 제안합니다. 마지막으로 low-quality detected bounding boxes를 억제하고 전체 성능을 크게 향상시키는 “centerness” 개념을 소개합니다.
3.1 Fully Convolutional One-Stage Object Detector
먼저 $F_{i}\in \mathbb{R^{H\times W \times C}}$를 backbone CNN의 layer $i$의 feature map 이라고 정의하고, $s$를 layer 까지의 stride 라고 정의합니다. 입력 영상에 대한 ground-truth bounding boxes는 {$B_{i}$}라고 정의합니다. 여기서 $B_{i} = (x_{0}^{(i)}, y_{0}^{(i)}, x_{1}^{(i)}, y_{1}^{(i)}, c^{i}) \in \mathbb{R}^{4}\times \left\lbrace 1, 2, ... C \right\rbrace$ 입니다.
또한 $(x_{0}^{(i)}, y_{0}^{(i)})$과 $(x_{1}^{(i)}, y_{1}^{(i)})$은 bounding box의 left-top과 right-bottom corner의 좌표를 뜻합니다. $c^{i}$는 bounding box에 속하는 객체의 class를 뜻합니다. $C$는 class의 number를 뜻하며, MS-COCO 데이터세트에서는 80을 뜻합니다.
각 feature map $F_{i}$ 위치인 location $(x, y)$는 $(x, y)$의 receptive field의 center인 $(\left \lfloor \frac{s}{2}\right \rfloor + xs, \left \lfloor \frac{s}{2}\right \rfloor + ys)$로 나타낼 수 있습니다.
입력 영상의 위치를 Anchor box의 중심으로 간주하여 대상 bounding box를 regress 하는 Anchor 기반 검출기와는 달리, FCOS는 해당 위치에서 대상 bounding box를 직접 regress 합니다. 즉, semantic segmentation을 위한 FCN과 동일한 Anchor 기반 검출기에서 Anchor box 대신 training samples 로 위치를 직접 다루게 됩니다.
위치 location $(x, y)$가 GT box 에 속하고 클래스 레이블 $ c^* $가 GT box의 클래스 레이블인 경우 ppositiva sample로 간주됩니다. 그렇지 않으면 negative sample이 됩니다. 여기서 $ c^* = 0 $은 background class를 뜻합니다. 클래스 분류를 위한 레이블 외에도 위치 정보에 대한 regression target인 4D real vector $t^* = ( l^* , t^* , r^* , b^* )$가 있습니다. 여기서 $l^{* }, t^{* }, r^{* }, b^{* }$는 그림 1의 왼쪽과 같이 bounding box의 위치에서 네개의 변 까지의 거리를 뜻합니다.
location이 여러 bounding box에 속하는 경우 ambiguous sample로 간주됩니다. regression target으로 minimal area의 bounding box를 선택하기만 하면 됩니다.
다음은 multi-level prediction을 사용하여 ambiguous sample의 수를 크게 줄일 수 있으므로 검출 성능에 거의 영향을 미치지 않음을 보여주게 됩니다. location $(x, y)$가 bounding box $B_{i}$와 연관되면 location에 대한 training regression target은 다음과 같이 식1로 나타낼 수 있습니다.
$l^{* } = x-x_{0}^{(i)} , t^{* } = y-y_{0}^{(i)}, $
$r^{* } = x_{1}^{(i)}-x , b^{* } = y_{1}^{(i)}-y.$
FCOS가 regressor를 학습 시키기 위해 가능한 많은 foreground sample을 활용할 수 있다는 점은 주목할만한 가치가 있습니다. 이는 GT box가 포함된 IoU가 충분히 높은 Anchor box만 positive sample로 간주하는 Anchor 기반 검출기와는 다릅니다. FCOS가 Anchor 기반 검출기들 보다 우수할 수 있었던 이유중 하나가 바로 이것입니다.
Network Outputs
traning target에 해당하는 신경망의 final layer는 classification label의 80D vector $p$와 4D vector $t=(l, t, r, b)$인 bounding box 좌표를 예측하게 됩니다. multi-class classifier를 학습하는 대신 $C$ binary classifier를 학습합니다. classification 및 regression branch에 대해 각 backbone 신경망의 feature map 뒤에 4개의 convolutional layer를 추가합니다. regression traget은 항상 positive이므로 $exp(x)$을 사용하여 임의의 실수를 regression branch의 맨 위에 있는 $(0,∞)$
에 매핑합니다. FCOS는 location 당 9개의 Anchor box가 있는 Anchor 기반 검출기 보다 신경망 출력 변수가 9배 더 적습니다.
Loss Fucntion
학습 시 손실함수는 다음과 같이 정합니다.
$L(\left\lbrace p_{x, y} \right\rbrace, \left\lbrace t_{x, y} \right\rbrace) = \frac{1}{N_{pos}}\sum_{x, y}L_{cls}(P_{x, y}, C_{x, y}^{* }) \; + \; \frac{\lambda }{N_{pos}}\sum_{x, y}1_{\left\lbrace C_{x, y}^{* }>0 \right\rbrace}L_{reg}(t_{x,y}, t_{x, y}^{* }), $
여기서 $L_{cls}$는 focal loss이며, $L_{reg}$는 UniBOx에서 소개된 IOU loss 입니다. $N_{pos}$는 positive sample의 수를 나타내며 $\lambda$가 1인 것은 $L_{reg}$에 대한 balance weight 입니다. 이 summation은 feature map $F_{i}$의 모든 위치에 대해 계산됩니다. $1_{\left\lbrace C_{x, y}^{* }>0 \right\rbrace}$은 indicator function이며 $C_{i}^{* } > 0$인 경우 1이며 그렇지 않으면 0이 됩니다.
Inference
FCOS의 추론은 간단합니다. 입력 영상이 주어지면 신경망을 통해 전달하고 classification score인 $p_{x, y}$ 및 regression prediction인 $t_{x, y}$을 얻게 됩니다. feature map $F_{i}$의 각 location에 대해 $p_{x, y} > 0.05$ 인 위치를 positive sample로 선택하고, 식1을 반전시켜 예측된 bounding box를 얻습니다.
3.2 Multi-level Prediction with FPN for FCOS
제안된 FCOS는 FPN + multi-level prediction으로 2가지 문제를 해결 할 수 있습니다.
CNN에서 final feature map의 large stride(e.g. 16x)은 상대적으로 낮은 recall을 초래할 수 있습니다. (이하 BPR은 best possible recall) Anchor 기반 검출기의 경우 large stride로 인한 low recall rates는 positive anchor box에 필요한 IoU score를 낮추어 어느 정도 보장 할 수 있습니다. FCOS의 경우 large stride 로 인해 final feature map에서 encode 되는 위치가 없는 객체를 recall 시킬 수 없기 때문에 BPR이 Anchor 기반 검출기보다 훨씬 낮을 수 있다고 생각할 수 있습니다.
표 1에서는 FCOS는 large stride에도 불구하고 FCN기반 FCOS가 여전히 우수한 BPR을 생성할 수 있으며 공식 구현인 Detectron에서 Anchor 기반 검출기 RetinaNet의 BPR보다 훨씬 더 우수할 수 있음을 보여줍니다. 따라서 BPR은 실제로 FCOS의 문제가 아니며 multi-level FPN prediction을 사용하여 BPR을 추가로 개선하여 Anchor 기반 RetinaNet의 성능을 향상 시킬 수 있습니다.
GT box의 중첩은 다루기 힘든 모호성을 유발 시킬 수 있습니다. 이러한 모호성으로 인하여 FCN 기반 검출기의 성능이 저하됩니다. 이러한 모호성은 multi-level prediction으로 해결 할 수 있으며 FCN 기반 검출기가 Anchor 기반 검출기와 동등하거나 때로는 더 나은 성능을 얻을 수 있음을 보여줍니다. FPN에 따라 다양한 수준의 feature map에서 다양한 크기의 객체를 검출하게 됩니다. 특히 {$P_{3}, P_{4}, P_{5}, P_{6}, P_{7}$ 로 정의된 다섯 가지 수준의 feature map을 사용합니다.여기서 그림 2와 같이 $P_{3}, P_{4}, P_{5}$는 backbone CNN의 feature map $C_{3}, C_{4}, C_{5}$에 의해 생성되고, top-down connection으로 1x1 conv layer가 뒤따르게 됩니다. $P_{6}, P_{7}$은 각 $P_{5}, P_{6}$에 stride 가 2인 하나의 conv layer를 적용하여 생성됩니다. 결과적으로 feature level $P_{3}, P_{4}, P_{5}, P_{6}, P_{7}$은 각 stride 8, 16, 32, 64, 128을 갖게 됩니다.
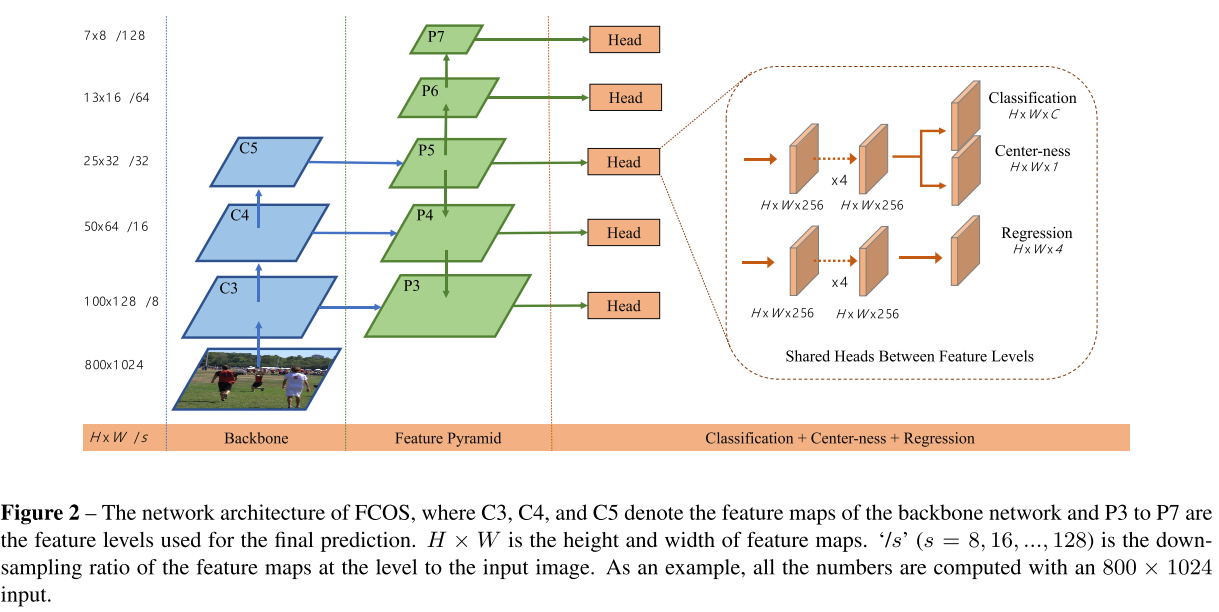
크기가 다른 Anchor box를 다른 feature level에 할당하는 Anchor 기반 검출기와는 달리 FCOS는 각 level에 대한 bounding box의 regression 범위를 직접 제한하게 됩니다. 먼저 모든 feature level에서 각 location에 대한 regression traget인 $l^{* }, t^{* }, r^{* }, b^{* }$를 계산합니다. 그 다음 위치가 $max(l^{* }, t^{* }, r^{* }, b^{* }) > m_{i}$ 또는 $max(l^{* }, t^{* }, r^{* }, b^{* }) < m_{i-1}$을 만족하면 negative sample로 설정되므로 더 이상 bounding box를 regression 할 필요가 없습니다. 여기서 $m_{i}$는 feature level $i$가 regression 해야 하는 최대 거리를 나타냅니다. 여기서 $m_{2},m_{3}, m_{4}, m_{5}, m_{6}, m_{7}$은 각 0, 64, 128, 256, 512 및 $∞$로 설정됩니다.
크기가 다른 객체는 다른 feature level에 할당되고 대부분의 중첩은 크기가 상당히 다른 객체 간에 발생하게 됩니다. multi level prediction을 사용하더라도 location이 여전히 2개 이상의 GT box에 할당된다면 minimal area의 GT box를 선택하게 됩니다.
마지막으로 서로 다른 feature level 간에 head를 공유하여 검출기 파라미터를 효율적으로 만들 뿐 아니라 성능도 크게 개선하게 됩니다. 그러나 다른 크기의 범위(e.g., the size range is [ 0, 64 ] for $P_{3}$ and [ 64, 128] for $P_{4}$)를 regression 하기 위해서는 다른 feature level에 동일한 head를 사용하는 것은 올바르지 않습니다. 결과적으로 $standard$ $exp(x)$을 사용하는 대신 FCOS에서는 $exp(6)$을 학습 가능한 scalar $s_{i}$에 사용하여 feature level $P_{i}$에 대한 exponential function의 base를 자동으로 조정하여 검출 성능을 약간 향상시키게 됩니다.
3.3 Center-ness for FCOS
FCOS에서 multi-level prediction을 사용한 후에도 FCOS와 Anchor 기반 검출기 사이에는 여전히 성능 차이가 있었던 이유는 객체의 중심에서 멀리 떨어진 위치에 의해 생성된 low-quality predicted bounding box 들 때문이라고 생각했기에 하이퍼 파라미터를 도입하지 않고 문제를 해결 할 수 있는 “centerness” 개념을 제안합니다.
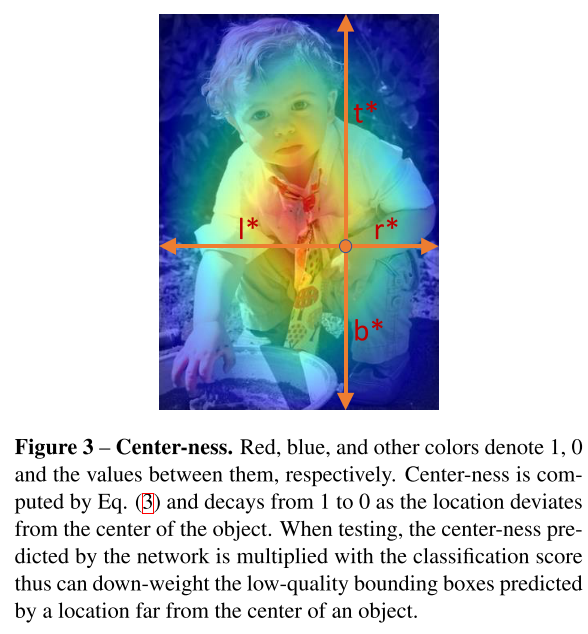
특히 그림 2의 “centeness”를 예측하기 위해 classification branch와 병렬로 single layer branch를 추가합니다. centerness는 그림 7과 같이 location에서 해당 location이 담당하는 객체의 중심까지 정규화된 거리를 나타냅니다. location에 대한 regression target $l^{* }, t^{* }, r^{* }, b^{* } $이 주어지면 centerness target은 다음과 같이 정의됩니다.
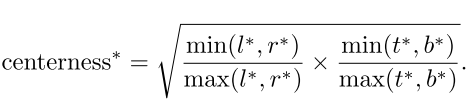
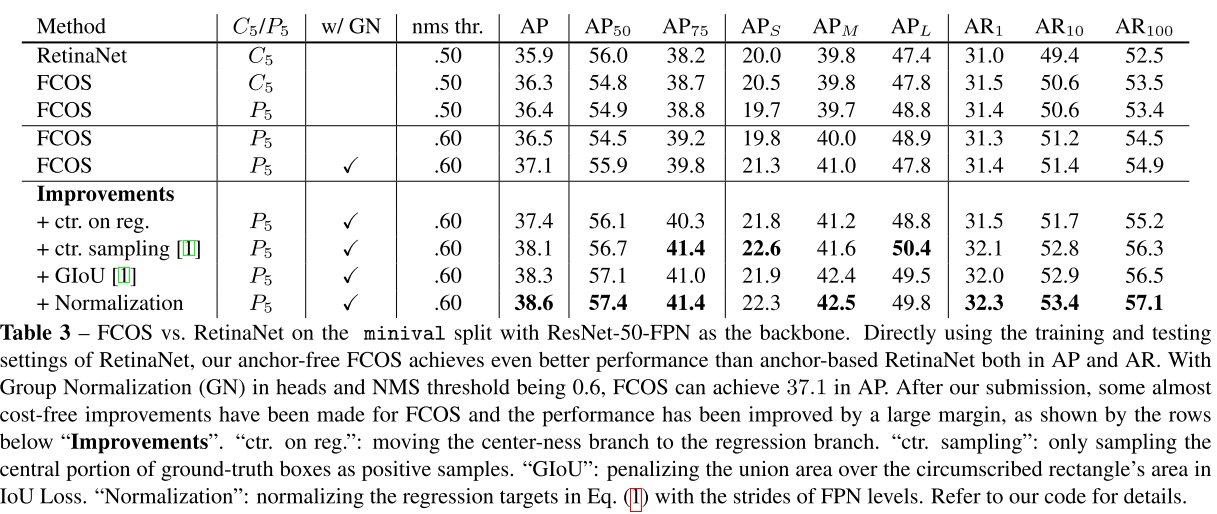
여기서 sqrt를 사용하여 centerness의 decay를 늦춥니다. centerness는 0에서 1사이의 범위 값이며, binary cross entropy(BCE) 손실로 학습됩니다. 이 손실은 위에서 설명한 손실 함수에 추가됩니다. 테스트 할 때 final score는 예측된 centerness를 해당 classification score와 곱하여 계산됩니다. 따라서 centerness는 객체의 중심에서 멀리 떨어진 boundinb box의 score를 낮출 수 있게 됩니다.결과적으로 이러한 low-quality bounding box는 최종 NMS에 의해 높은 확률로 필터링되어 검출 성능이 크게 향상 될 수 있습니다. centerness의 대안은 하이퍼 파라미터 하나를 추가하는 정도로 GT bounding box의 중앙 부분만 positive sample로 사용할 수 있습니다. 두 방법의 조합이 훨씬 더 나은 성능을 달성할 수 있음을 표 3에서 확인 할 수 있습니다.
4. Experiments
실험은 COCO 벤치마크에서 수행됩니다. 일반적으로 학습에 COCO trainval35k split (115k images)을 사용하고 ablation study를 위해 validation으로는 minival split (5k images)을 사용합니다. 검출 결과를 평가 서버에 업로드하여 test dev split (20k images)에 대한 주요 결과를 보고합니다.
Training Details
ResNet-50이 backbone으로 사용되며 RetinaNet과 동일한 하이퍼 파라미터가 사용됩니다. 특히 FCOS에서는 초기 학습률이 0.01이고 16개 이미지의 미니 배치로 90K iteration에 대해 stochastic gradient descent(SGD)로 학습됩니다. 학습률은 60K 및 80K에서 각 10배 정도 감소하게 됩니다. weight decay 및 momentum은 각 0.0001과 0.9로 설정되었습니다. ImageNet에서 pre-trained weight로 backbone 신경망을 초기화합니다. 새로 추가된 레이어의 경우 Focal loss for dense object detection 논문에 나와있는 것과 같이 초기화 합니다. 또한 입력 영상은 단축이 800이고 장축이 1333보다 작거나 같도록 크기를 조정합니다.
Inference Details
먼저 신경망을 통해 입력 영상을 전달하고 class와 bounding box를 얻습니다. post-processing은 RetinaNet과 동일합니다. 학습에서 사용한 동일한 크기의 입력 영상을 사용합니다.
4.1 Ablation Study
4.1.1 Multi-level Prediction with FPN
앞에서 언급했듯 FCN 기반 검출기의 주요 문제는 low recall과 GT bounding box에서 중첩된 결과로 발생하는 ambiguous sample 입니다. 이 섹션에서는 두 문제가 multi-level prediction으로 해결 될 수 있음을 보여줍니다.
Best Possible Recalls
표 1에서 볼 수 있듯 stride가 16((i.e., no FPN)인 feature level $P_{4}$ 에서만 FCOS는 이미 95.55%의 BPR을 얻습니다. Detectron에서 RetinaNet의 BPR인 90.92% 보다 훨씬 높은 수치입니다. FPN의 도움으로 FCOS는 98.40%의 BPR을 달성할 수 있습니다.

Ambiguous Samples
FPN을 사용하지 않고 $P_{4}$만 사용하는 경우 실제로 많은 양의 ambiguous sample(23.16%)이 있습니다. 그러나 FPN을 사용하면 대부분의 겹친 개체가 서로 다른 feature level에 할당되기 때문에 비율을 7.14%로 크게 줄일 수 있습니다.

4.1.2 With or Without Center-ness
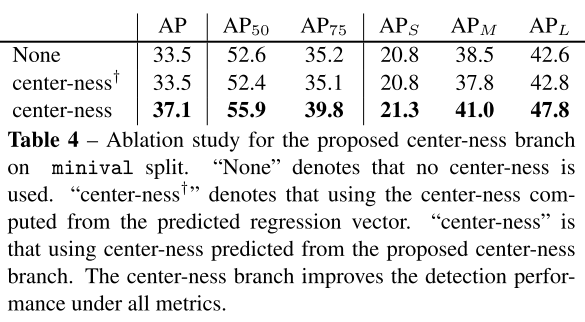
표 4에서 볼 수 있듯 centerness는 AP를 33.5%에서 37.1%로 높였고, Anchor-free FCOS가 Anchor 기반 RetinaNet(35.9%)보다 성능이 우수하다는 것을 보여줍니다.
4.1.3 FCOS vs. Anchor-based Detectors
FCOS는 RetinaNet과 두 가지 차이점이 있습니다.
1. 마지막 prediction layer를 제외하고 새로 추가된 Conv layer에서 Group Normalization을 사용하여 안정적으로 학습합니다.
2. $C_{5}$ 대신 $P_{5}$를 사용하여 $P_{6}$ 및 $P_{7}$을 생성합니다. $P_{5}$를 사용하면 성능이 약간 더 향상 될 수 있습니다.
동일하게 비교하기 위해 GN을 제거하고 $C_{5}$를 사용하여 비교하였을 때 표 3과 같이 36.3% vs 35.9% 의 결과를 볼 수 있습니다. 또한 Anchor 기반 검출기에 최적화 된 RetinaNet의 모든 하이퍼 파라미터를 사용했다는 점에 주목할 필요가 있습니다. FCOS에서 하이퍼 파라미터를 튜닝한다면 더 성능이 향상 될 수 있습니다.
4.2. Comparison with State-of-the-art Detectors
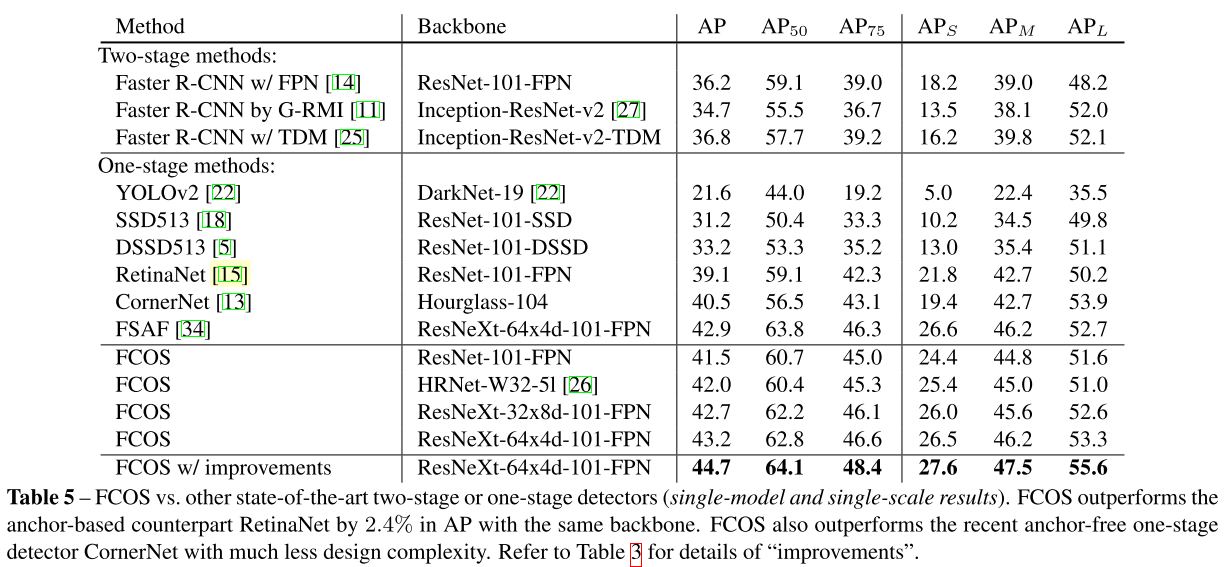
MS-COCO 벤치마크의 test-dev split 에서 FCOS와 SOTA 검출기를 비교합니다. 실험을 위해 학습 중 640에서 800 사이 범위의 이미지의 단축을 randomly scale하고 iteration을 180K로 늘렸습니다. 학습 속도 변경 지점은 비례적으로 조정되었다고 합니다. 표 5에서 볼 수 있듯이 ResNet-101-FPN을 사용하는 FCOS는 동일한 backbone ResNet-101-FPN을 사용하는 RetinaNet을 AP에서 2.4% 능가합니다. ResNeXt-64x4d-101-FPN을 backbone으로 사용하여 FCOS는 AP에서 43.2%를 달성했습니다. 이는 CornerNet을 큰 차이로 능가합니다.
5. Extensions on Region Proposal Networks
FCOS는 one-stage 검출기에서 Anchor 기반 검출기보다 훨씬 나은 성능을 달성할 수 있음을 보여주었습니다. FCOS는 RPN의 Anchor box를 two-stage 검출기인 Faster R-CNN의 FPN으로 대체 할 수 있습니다. 또한 FPN head의 layer에 GN을 추가하여 학습을 안정적으로 만들 수 있습니다. 표 6과 같이 centeness가 없어도 FCOS는 $AR^{100}$과 $AR^{1k}$를 크게 향상 시킵니다.

6. Conclusion
본 논문에서는 Anchor와 Proposal이 없는 one-stage 검출기 FCOS를 제안했습니다. FCOS는 RetinaNet, YOLO 및 SSD를 포함하여 널리 사용되는 Anchor 기반 one-stage 검출기와 비교하였을 때 훨씬 더 설계 복잡성이 적습니다. 또한 SOTA 성능을 달성합니다. 그리고 FCOS는 two-stage 검출기의 RPN으로 사용될 수 있으며, 성능 향상을 보여줄 수 있음을 시사합니다.

(2022.04.14) 내용 아래와 같이 추가합니다!
사실 저에게 제일 도움이 많이 되었던 부분은 논문의 Appendix 부분입니다. Appendix 부분에 있던 내용을 간략하게 정리하면 아래와 같습니다.
- IoU threshold 기준을 더 엄격하게 잡는다면, FCOS가 RetinaNet 보다 성능이 좋습니다. 이는 FCOS가 객체를 더 정확하게 감지하기 위한 bounding box regressor를 갖는다는 것을 보여줍니다. 이러한 결과가 나타나는 이유 중 하나는 FCOS는 regressor를 학습 시키기 위해 더 많은 foreground sample을 활용할 수 있는 능력이 있습니다.
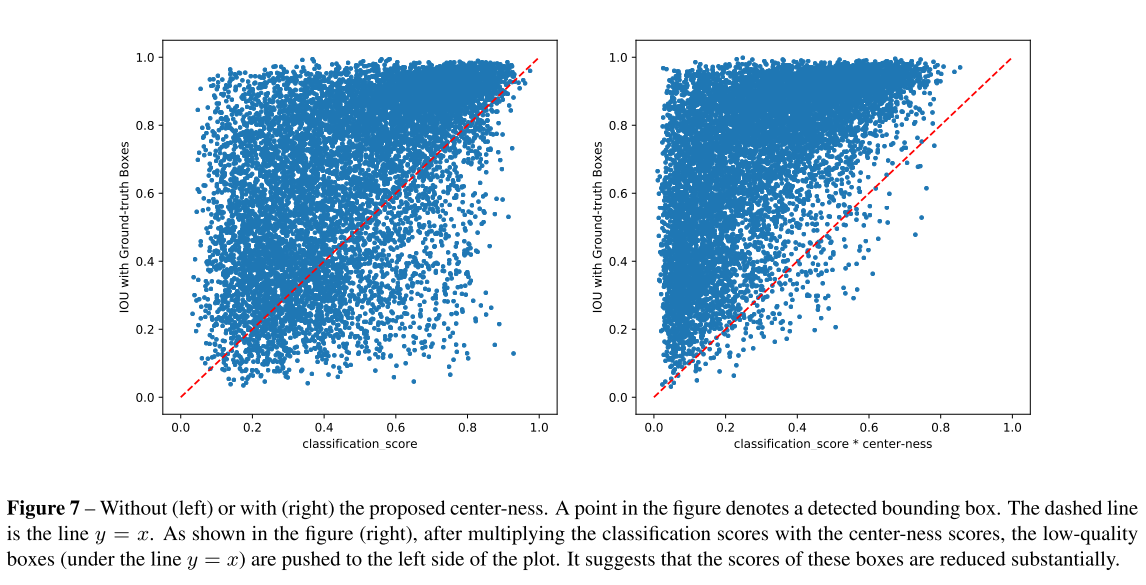
- 일반적인 classification score는 아래 그림의 왼쪽과 같이 품질은 낮지만 confidence score가 높은 결과들이 많습니다. 하지만 본 논문에서 주장하는 것 처럼 classification score에 centerness score를 곱한다면 아래 그림 오른쪽과 같이 품질이 낮은 bounding box들은 확실히 줄어들게 되고, post-processing 과정에서 필터링될 가능성이 높습니다. 즉 최종 탐지 성능이 향상됩니다.
- 아래 Table 8에서 볼 수 있듯이 기본 FCOS는 RetinaNet과 동등한 성능을 제공하게 되며, 설계가 더 단순하고 신경망 출력이 ~9배 적습니다. 또한 FCOS는 단일 앵커를 사용하는 RetinaNet 보다 훨씬 더 잘 작동합니다. testdev에서 2% 이득에 관해서는 표8의 구성요소들로 인한 성능 이득 이외에 다른 training details(e.g. learning rate schedule)이 성능 차이를 조금 유발 할 수 있습니다. GN(Ground Normalization)을 이용하는 것이 성능을 향상시키고 학습을 안정적으로 돕는다고 합니다.
