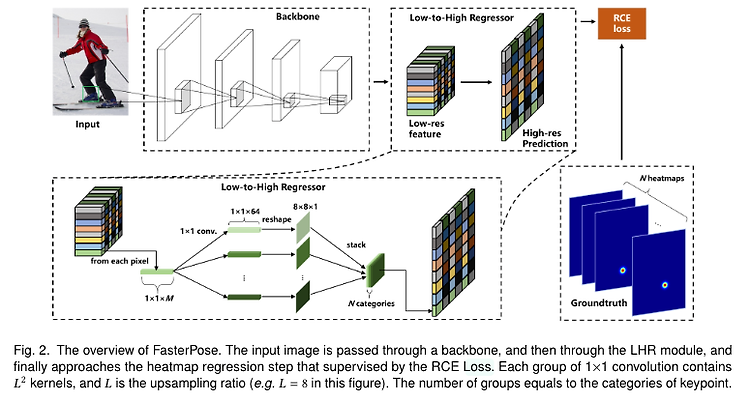
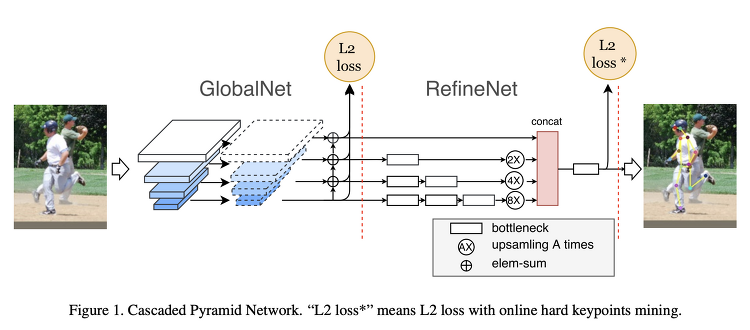
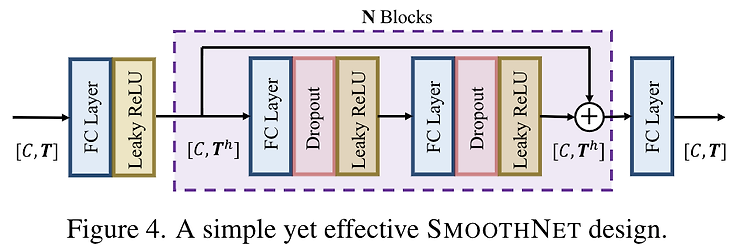
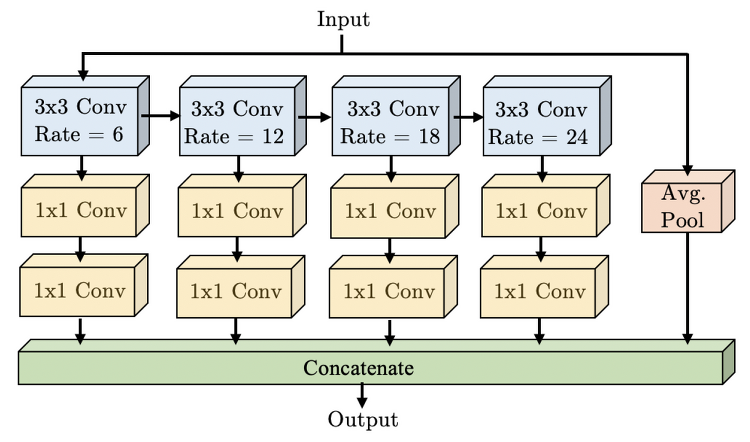
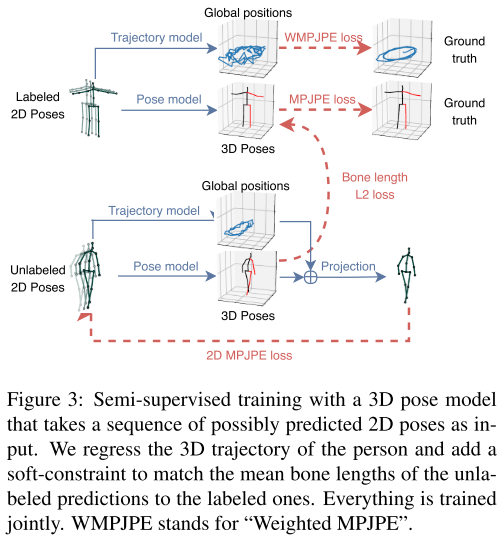
[Pose Estimation] waterfall module 기반으로 설계된 자세 추정 방법들 (UniPose, UniPose+, OmniPose, BAPose)
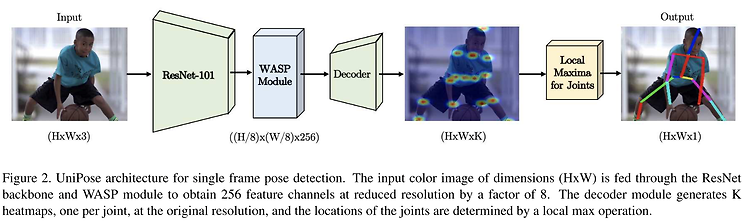
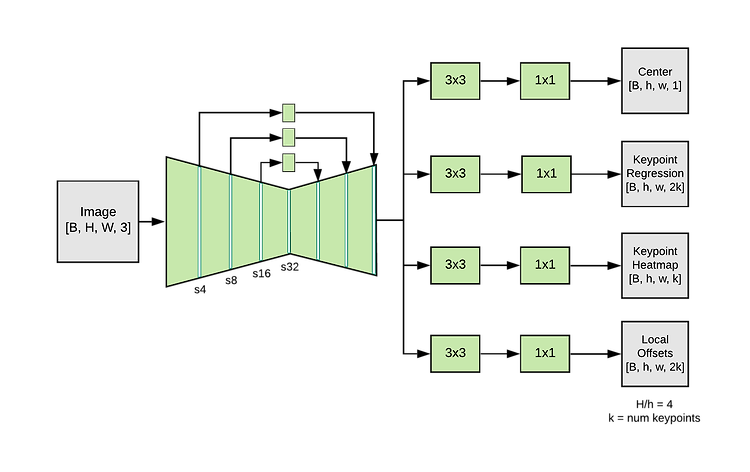
waterfall module 즉 WASP(Waterfall Atrous Spatial Pyramid)는 위 그림과 같은 구성으로 되어있으며 원래 semantic segmentation을 위해 multiscale fields-of-view(FOV)를 유지하면서 cascade architecture에서 progressive filtering을 활용하는 “Waterfall” Atrous Spatial Pooling 기반 방식으로 이루어진 모듈이다. 이와 같은 module로 설계된 자세 추정 방법들은 아래와 같다. 1. UniPose, Unified Human Pose Estimation in Single Images and Videos (CVPR 2020) WASP module (w/ a cascade of..
2022.04.20