[Paper Review] Imbalance Problems in Object Detection : A Review
Paper : https://arxiv.org/pdf/1909.00169v1.pdf
Project page : https://github.com/kemaloksuz/ObjectDetectionImbalance
kemaloksuz/ObjectDetectionImbalance
Lists the papers related to imbalance problems in object detection - kemaloksuz/ObjectDetectionImbalance
github.com
본 게시물은 위 논문을 번역하여 나름 .. 다시 정리한 글 입니다.
1. Introduction
객체 탐지(Object Detection, OD) 분야에 있어서 불균형(Imbalance) 문제는 피할 수 없는 주제이다. 객체 탐지란 주어진 영상에서 객체의 인스턴스 범주와 위치를 동시에 추정하는 것이다. 1세대 OD 방법은 손수 제작된 특징들과 선형, max-margin 분류기에 의존하는 양상을 띄고 있었다. 이 세대에서 가장 성공적이고 대표적인 방법은 DPM(Deformable Parts Model) 이라고 한다. 딥러닝(Deep Learing) 세대가 시작된 후에는 이와 같은 방식들이 모두 신경망으로 대체되어 딥러닝 알고리즘으로 변화하였다. DPM 은 OD의 유명한 벤치마크 데이터 세트인 PACAL VOC 에서 0.34 mAP 를 달성하였지만, 현재 딥러닝 기반의 최신 OD 모델[Yolo9000]들은 0.80 mAP 를 달성할 정도로 OD 수준이 향상되었다.
지난 5년간 OD에서 심층 신경망의 통합이 이루어졌으며, OD의 불균형 문제는 여러 수준에서 주목 받기 시작하였다. 특히 입력 속성에 대한 불균형 문제는 해당 속성에 대한 분포가 성능에 영향을 줄 때 발생한다. 불균형 문제를 해결하지 않는다면, 최종 탐지 성능에 악영향을 미치게 된다. 예를 들어, OD에서 가장 일반적인 불균형 문제인 "Foreground-to-background" 불균형 문제는 positive example 수와 negative example 수 사이의 극심한 불균형을 이룬다는 것을 말한다. 쉽게 설명하자면, 주어진 영상에서 GT 를 잘 맞추는 케이스들이 많지만, 맞추지 못하는 케이스들도 엄청나게 많음을 의미한다. 이 문제를 해결하지 않는다면, 당연히 정확도는 떨어지게 된다.
본 논문에서는 이를 포함하여 총 4가지 유형으로 불균형 문제를 분석한다.
- Class Imbalance : 다른 클래스 사이의 불균형 문제
- Scale Imbalance : 다양한 스케일 사이의 불균형 문제
- Spatial Imbalance : Bounding-box 속성과 관련된 불균형 문제
- Objective Imbalance : 여러 손실 함수와 관련된 불균형 문제

2. Background and Definitions
Background
객체 탐지를 위한 주요 접근 방식은 아래와 같이 하향식 및 상향식 접근법으로 분류되는데, 오늘날 대부분의 객체 탐지 방법들은 하향식 접근법을 따르고 있으며, 상향식 접근법은 비교적 최근에 제안되었다.
- 하향식(top-down) 접근법
- 앵커(Anchors) / 관심 영역(Regions-of-interest) / 객체 제안(Object Proposals)과 같은 것들이 초기에 생성되고 평가되어 객체를 탐지하는 방식
- Two-Stage Object Detector
- 객체가 포함되어있을 확률이 가장 높은 영역인 관심 영역을 결정하는 메커니즘을 사용하여 사전 정의된 앵커로 negative 들을 관리함으로써 가장 알맞은 관심 영역을 찾음
- 관심 영역은 중복 결과를 제거하는 NMS(Non-maxima Suppression) 과 같은 추가 처리 과정을 거쳐 경계 상자(Bounding-box) 및 확률로 검출 결과를 출력
- One-Stage Object Detector
- 입력 영상에서 특징을 추출한 후, 영역 제거 단계 없이 앵커에서 직접 검출 결과를 예측하도록 설계

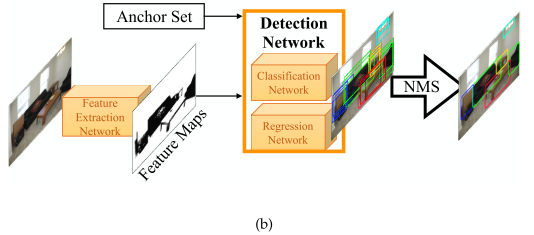
- 상향식(bottom-up) 접근법
- 키포인트(Key-point) 및 부분(Parts) 들과 같은 하위 객체 엔티티(Entity)를 나중에 그룹화하여 객체를 탐지하는 방식
- 물체를 키포인트 추정(Keypoint Estimation) 작업으로 간주하고 클래스별로 히트맵(Heatmap)을 사용하여 물체의 모서리(Corner)를 예측함, 이는 회귀 신경망(Regression Network)에 의해 더욱 개선됨
- Associative Embedding 및 Brute Force Search 알고리즘과 같은 방법을 이용하여 객체 인스턴스(Instance)를 형성하여 그룹화
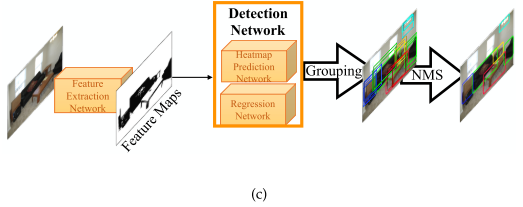
Definitions
- Feature Extraction Network/Backbone
- 입력 이미지에서 탐지 신경망까지 객체 탐지 과정
- Classification Network/Classifier
- 백본에 의해 추출된 특징에서 분류 결과까지 객체 탐지 과정
- 신뢰도 점수(Confidence Score)로 표시
- Regression Network/Regressor
- 백본에 의해 추출된 특징에서 회귀 출력까지 객체 탐지 과정
- 각 x 축 및 y 축 값으로 구성된 두 개의 경계 상자 좌표로 표시
- Detection Network/Detector
- 분류와 회귀를 포함한 객체 탐지 과정
- Region Proposal Network (RPN)
- 백본에서 추출한 특징에서 생성된 결과에 이르기까지 신뢰 점수 및 경계 상자 좌표가 있는 Two-stage 객체 탐지 과정
- Bounding Box
- 특정 특징으로 이루어진 이미지의 사각형
- 공식적으로 x1, y1, x2, y2 는 x2 > x1 및 y2 > y1 을 만족하는 왼쪽 위 모서리(x1, y1)와 오른쪽 아래 모서리(x2, y2)로 이루어짐
- Anchor
- Two-stage Object Detector 의 RPN과 One-stage Object Detector의 신경망에 적용되는 사전 정의된 경계 상자 세트
- Region of Interest (RoI)/Proposal
- RPN과 같은 메커니즘에 의해 생성된 경계 상자 세트
- Input Bounding Box
- 샘플링된 앵커 및 관심 영역 탐지 신경망 또는 RPN이 훈련됨
- Ground Truth(GT)
- 기준이 되는 경계 상자 데이터
- Intersection Over Union
- GT 경계 상자와 탐지된 경계상자의 교차점
- Under-represented Class
- 클래스 불균형 문제와 관련하여 훈련되는 동안 데이터 집합 또는 미니 배치에서 샘플 수가 적은 클래스
- Over-represented Class
- 클래스 불균형 문제와 관련하여 훈련되는 동안 데이터 세트 또는 미니 배치에서 더 많은 샘플이 있는 클래스
- Backbone Features
- 백본 신경망을 적용하는 동안 얻은 특징 세트
- Pyramidal Features/Feature Pyramid
- 백본 특징에 약간의 변형을 이용하여 얻은 특징 세트
- Image Pyramidal Features
- 입력 이미지의 업색플링 및 다운샘플링 된 버전에 백본 신경망을 적용하여 얻은 특징 세트
- Trident Features
- 스케일 인식 Trident(트라이던트, 세갈래) 블록을 확장(dilation) 비율이 다른 백본 신경망으로 이미지에 적용하여 얻은 특징 세트
- (The set of features obtained by applying scale aware trident blocks as the backbone networks with different dilation rates to the image.)
- Regression Objective Input
- 어떤 방법들은 방법들마다 다른 변환(Transformation)을 적용하여 로그 도메인에서 예측을 수행하는 반면, GIoU Loss 와 같은 방법은 경계 상자 좌표를 직접 예측함
3. Taxonomy of the imbalance problems and their solutions in object detection
객체 탐지 분야에서 불균형 문제는 어디서든 나타날 수 있다. 이러한 문제들을 다루는 연구 목록들을 본 논문에서 제시하고 있으며, 이러한 불균형 문제를 해결하기위해 제안된 방법들(샘플링, 특징 추출 단계의 개선, 목적 함수들에 대한 수정 및 생성 방법 등)을 소개한다.
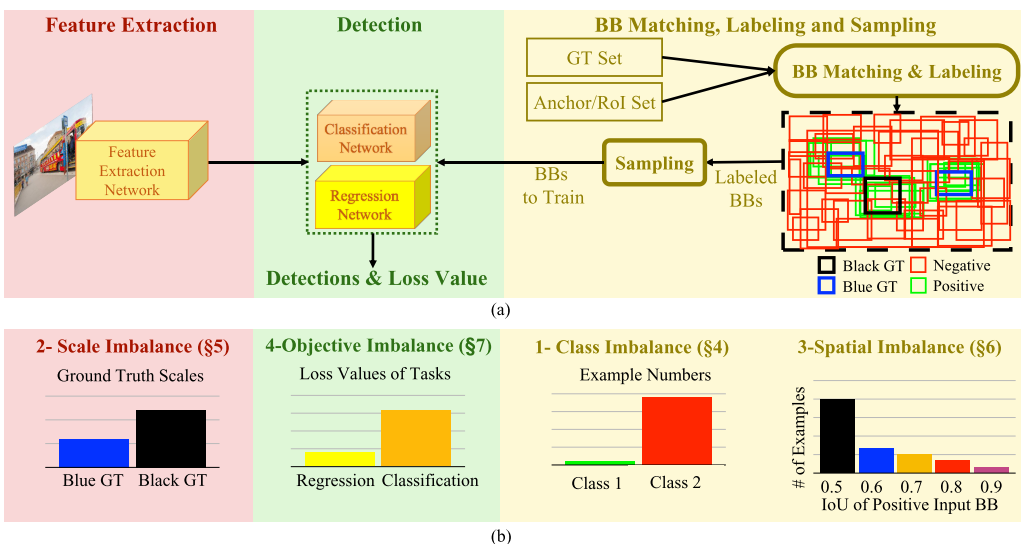

4. Imbalance 1 : Class Imbalance
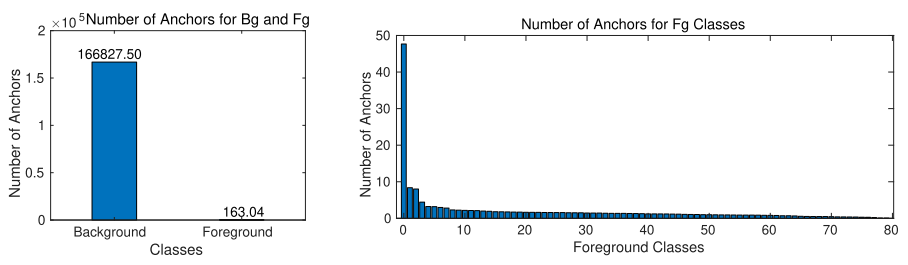
클래스 불균형 문제는 클래스가 과도하게 표현될 때 관찰되며, 객체 탐지 관점에서 전경(foreground, fg) - 배경(background, bg) 불균형과 전경-전경 불균형 두가지 방식으로 발생 할 수 있다.
아래 그림은 MS-COCO 데이터 세트의 학습 이미지에 RetinaNet 의 기본 앵커 세트를 적용하고, fg 클래스가 있는 앵커의 IoU 가 0.5 를 초과하는 경우의 빈도수를 계산한 결과이다. 초과하지 않는 경우(즉, bg 상자인 겨우) 및 fg 클래스와 겹치는 경우 각 클래스의 개수를 별도로 유지하고 데이터 세트의 이미지 수로 결과를 정규화 하였다. 이 두 가지 유형의 불균형은 서로 다른 특성을 가지고 있으며, 서로 다른 방법으로 해결 할 수도 있지만 생성 모델링(generative modeling)을 사용하여 두 가지 문제를 해결 할 수도 있다.
- Class Imbalance
- Foreground-Background Class Imbalance
- Foreground-Foreground Class Imbalance
4.1 Foreground-Background Class Imbalance Definition.
- Foreground-Background Class Imbalance
- Background Class : 과다 표현된 클래스
- Foreground Class : 불완전한 클래스
대부분의 경계 상자가 경계 상자 매칭 및 라벨링 모듈에 의해 배경 (a.k.a negative) 클래스로 표시되기 때문에 불가피하다는 문제를 가진다. 이러한 문제는 훈련중에 발생하며, bg 에는 주석이 표시되지 않으므로 데이터 세트의 클래스당 이미지 수는 상관이 없다.
- Solution
- 샘플링 방법은 일련의 경계 상자에서 샘플을 선택하는 방법과 샘플을 생성하는 방법으로 나뉜다.
- 샘플링 방법에서 경계 상자의 손실함수에 대한 기여도(Contribution)가 조정된다.
- 이러한 기여도에 따라 하드 샘플링 or 소프트 샘플링 으로 구분된다.
- Hard Sampling Methods
- Soft Sampling Methods
- Generative Methods
Hard Sampling methods
- 객체 탐지의 불균형을 해결하기 위해 일반적으로 사용되는 방법이다. 하드 샘플링 방식은 기여도가 0 또는 1 값인 이진 값을 가지므로 선택되거나 폐기된다. 이러한 방식으로 불균형 문제를 해결하며, 선택되지 않은 샘플들은 현 반복(Iteration)에서 무시된다. 선택된 샘플들은 손실에 기여가 되지만, 선택되지 않은 샘플들은 전혀 기여가 되지 않는다.
- Random Sampling : 간단하게 샘플링을 랜덤으로 수행한다. 랜덤 샘플링은 편향되지 않으며 fg 및 bg 클래스 내에서 원래 분포를 유지한다.
- Hard-example mining : 이는 어려운 샘플들로 검출기를 훈련시키는것에 가설을 둔다. 이 가설에 의하면(얼굴 및 사람 탐지에서 bootstrapping 이 사용됨) 어려운 샘플들로 초기 모델을 훈련한 다음, 분류에 실패한 안좋은 예시들을 사용하여 새로운 분류기가 훈련이 된다. 동일한 절차를 반복하여 여러 분류기들을 얻을 수 있다. bootstrapping 은 제한된 컴퓨팅 리소스 때문에 개발되었지만, 오늘날 리소스가 많은 경우에도 이러한 방법이 사용된다. 연구에서는 손실 값을 이용하여 더 어려운 샘플들을 찾기 위해 하드 샘플링 방식을 채택한다. Single-shot Detector 는 어려운 샘플들을 사용하여 훈련한 첫번째 deep object detector 이다. 이는 가장 높은 손실 값을 발생시키는 네거티브 샘플들만 선택한다.
- OHEM(Online Hard Example Mining) : positive 및 negative 샘플의 손실 값을 고려한 체계적인 접근 방식이다. 그러나 이는 추가 메모리가 필요하며 훈련 속도가 느려진다.
- IoU-based sampling : 샘플의 하드한 정도를 IoU 와 연관시키고 전체 세트에 대한 손실함수를 계산하는 대신 negative 샘플들만 샘플링 방법을 다시 사용한다. negative 샘플들에 대한 IoU 간격은 K-bins 으로 나누고, 동일한 수의 negative 샘플이 각 bin 내에서 무작위로 샘플링되어 더 높은 IoU 를 갖는 샘플을 뽑음으로써 더 높은 손실 값을 갖는 샘플을 뽑을 수 있다.
mining 성능을 향상시키기 위해 여러 연구에서 어려운 샘플들을 쉽게 찾을 수 있도록 검색 공간을 제한할것을 제안하였다. two-stage object detector 는 앵커에 대해 가장 가능성이 있어보이는 경계 상자를 찾은 다음 가장 높은 점수를 가지는 최고의 관심 영역을 선택하기 때문에 추가적인 샘플링 방식이 적용된다.
- IoU-lower Bound : Fast R-CNN 에서 사용된 이 기법은 hard negative 를 뽑기 위해 negative 관심 영역의 IoU 의 하한을 0 이 아닌 0.1 로 설정한 다음, 랜덤 샘플링을 적용한다.
- Negative Anchor Filtering : one-stage object detector 에서 앵커 정제 모듈을 사용하여 앵커의 신뢰도 점수를 계산하였으며, easy negative 앵커를 제거하기 위해 threshold 값을 다시 채택한다.
Soft Sampling methods
하드 샘플링과는 달리, 소프트 샘플링 방식의 경우 기여도는 0부터 1까지의 값을 가지므로 샘플들을 버리지 않고 전체 데이터 세트를 사용하여 매개 변수를 업데이트 한다. 간단한 방법은 bg 및 fg 모두에 대해 상수 계수(constant coefficient)를 사용하는 것이다. SSD 및 RetinaNet 과 같은 one stage detector 에 비해 앵커 수가 적은 YOLO 는 bg 클래스의 샘플 손실 값이 절반으로 줄어드는 소프트 샘플링의 간단한 예시이다.
- Focal Loss : 이는 역동적으로 어려운 샘플들에 대해 더 많은 가중치를 부여한다. 아래 식에서 ps 는 GT 클래스에 대한 추정 확률을 뜻하는데, ps 가 낮을 수록 오차가 커지므로 더욱 더 어려운 샘플들을 뽑아 낼 수 있다. r = 0 인 경우에는 focal loss 가 vanilla cross entropy loss 로 퇴화된다.

- GHM(Gradient Harmonizing Mechanism) : Focal Loss 와 유사하게 GHM은 easy positive 및 negative 로 부터 비롯되는 그라디언트(Gradient Norm)를 제재한다. Focal Loss 와 달리 GHM은 유사한 그라디언트를 가진 샘플 수를 세고 나서, 이러한 샘플이 많을 경우 샘플 손실에 패널티(penalty)를 가하는 카운팅 기반 접근 방식이다. 아래 식과 같이 G(BBi)는 그라디언트가 BBi의 그라디언트에 가까운 샘플의 수 이며, m은 배치에서 입력 경계 상자의 수를 뜻한다. GHM 의 방법은 easy 샘플들이 너무 많은 경우라고 가정한다. 다른 방법과 달리 GHM 은 분류 문제 뿐만 아니라 회귀 작업에도 유용하다. 또한 그라디언트의 균형을 잘 맞추는 것이 목적이므로 이 방법은 회귀 손실의 불균형과도 관련이 있다.

- PISA(PrIme Sample Attention) : IoU가 높은 것을 선호하는 positive 샘플에 대해서만 가중치를 부여하는 방법이다. 이는 먼저 자신의 IoU를 기반으로 각 클래스에 대한 positive 예를 근거로 하여 순위를 정하고, 각 샘플 i 에 대하여 정규화된 순위 ui 를 다음 수식과 같이 계산한다. 여기서 ri 은 i 번째 샘플의 순위 이며, nj 는 배치에서 j 클래스의 총 샘플 수 이다. 정규화된 순위에 따라 각 샘플의 가중치는 다음 아래 수식과 같이 정의된다. 여기서 베타는 정규화된 순위와 최소 샘플 가중치의 기여도를 조정하는데 사용된다. 감마 값은 modulating factor 이다. 다음 두 식의 balancing strategy 은 손실에 대한 높은 IoU 를 가지는 샘플의 기여도를 증가 시킨다.

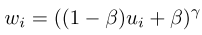
기본적으로 샘플링과 관련하여 몇 가지 중요한 사항이 있는데, 우선 hard sample 이 easy sample 보다 더 선호 된다는 대부분의 논문의 견해와는 반대로, PISA 가 적절하게 균형이 잡힌다면, 손실 값이 더 작은 높은 IoU가 있는 positive sample 은 positive 에 적용된 OHEM 에 비해 훈련이 잘된다. 더욱이, nagative 에 대해서는 OHEM 과 결합할 때 학습이 더 잘 수행되는 걸로 나타났다고 한다. 마지막으로, AP@0.50 의 성능 개선이 없기 때문에 주된 개선은 Localization 에서 이루어졌다는 것을 뜻한다. 결과적으로 분류기는 성능이 좋지 않더라도 회귀가 개선 되므로 분류기에 이러한 샘플을 제공하는 대신 IoU 분포의 특성이 변경되기 때문에 개선 될 수 있다.
또 다른 다른 소프트 샘플링 방식은 최종 성능 측정을 직접 모델링하고, 이 모델을 기반으로 샘플들에 가중치를 두는 것이다.
- AP(Average Precision) Loss : 분류(Classification) 손실에 순위를 매겨서 모델링하고, 손실 함수로 AP 를 사용하는 방법이다. 참고로, Hinge Loss 를 기반으로 분류 손실을 정의하기 위해 순위를 지정하는 방법을 사용하는 DR Loss 라는 것도 있다. 구체적으로 AP 를 개선하기 위해, 손실 함수로써 1-AP 가 사용된다. 그러나 AP를 손실 함수로 사용하는데 두가지 challenge 가 있다. 첫째, 박스의 신뢰 점수가 주어지면 최종 AP를 얻기 힘들다는 점. 둘째, AP is not differentiable. 최종 손실 값을 도출하기 위해 AP Loss 의 저자는 먼저 신뢰 점수를 아래 첫번째 식과 같이 변환하여 pi가 i 번째 경계 상자의 신뢰 점수가 되도록 한다. 그 다음 변환된 값인 xij 를 기반으로 AP Loss 의 주요항 Uij는 다음 두번째 식과 같이 표현된다. 여기서 P, N은 각 positive, negative 를 뜻하며, pi < pj 이면 Uij 는 0이고, 그렇지 않으면 1보다 작은 양수 값을 갖는다. 또한, 세번째 수식에서 yij 는 순위 레이블(Ranking Label)이고, i번째 박스가 fg 박스 이고, j 번째 상자는 bg 박스인 경우에만 1로 설정된다.
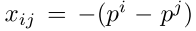


하지만, 이러한 AP Loss 는 최적의 신뢰 값 임계치가 클래스 마다 다르다는 것을 지적했다. 따라서 이러한 손실을 사용할 때에는 학습 중에 신뢰 점수가 균형을 이루는지의 여부를 판단해야한다.
Generative Methods
하드 및 소프트 샘플링 방법과는 달리, 생성 방법은 인공 샘플을 학습 데이터 세트에 직접 생성하고 주입하여 불균형 문제를 해결하는 것이다. 이러한 접근법 중 가장 유명한 방식은 GANs(Generative Adversarial Networks)이다.
- GANs : GAN의 장점은 신경망의 손실 값이 최종 탐지 결과에서 생성된 샘플의 분류 정확도를 기반으로 하기 때문에 학습 중에 더 어려운 샘플을 생성하도록 자체적으로 적읃 된다는 것이다.
- Adversarial-Fast-RCNN : 폐색(Occlusion)과 다양한 변형(Deformation)을 통해 하드 샘플을 생성한다. 이는 데이터를 생성 할 때 RoI Pooling 을 거친 뒤 고정크기의 특징 맵을 취함으로써 특징레벨에서 직접 수행된다. 이를 위해 폐색된 특징 맵 생성을 위한 adversarial spatial dropout 신경망 및 변형된 특징 맵 생성을 위한 adversarial spatial transformer 신경망이 제안되기도 했다. 이 두 신경망은 더 하드한 샘플을 제공하기 위해 신경망 설계에 순차적으로 배치되며, end-to-end 방식으로 기존의 객체 탐지 모델에 통합 된다.
또한, 멀티 크롭(multiple crop) 된 영상이나 원영상이 혼합되어있는 영상을 생성함으로써 데이터 세트를 증강(augment) 시키기 위해 인공적으로 영상들을 생성 할 수도 있다. 간단한 접근 방식은 자른 객체를 영상에 무작위로 배치하는 방법이다. 이러한 이미지는 사람이 눈으로 봤을 때 비현실적으로 보일 수 있다. 이 경우에는 붙여 넣으려고 하는 객체의 크기와 붙여 넣을 위치를 결정해야 문제가 해결된다.
- PSIS(Progressive and Selective Instance-Switching) : 후보 인스턴스들의 스케일 및 형상을 고려하여 한 쌍의 영상에서 동일한 클래스에 속하는 단일 객체들을 교환한다. 낮은 성능을 가지는 클래스의 객체를 교환하여 영상을 생성하면 당연히 검출 결과의 품질은 향상된다.
손수 객체를 복사하여 붙여넣는 대신, GAN을 사용하여 영상을 생성 할 수있다. 이는 이미지와 fg 객체 마스크가 주어지면 fg 객체 마스크를 이미지에 배치하여 현실적으로 판단하기 어려운 샘플들을 생성하게 된다.
- Bounding Box Generator : 이미지를 생성하는 대신 주어진 경계 상자 IoU, 경계 상자 공간 및 fg 클래스 분포로 positive RoI 를 생성한다. 이러한 방식은 GT 경계 상자에 맞추어 데이터가 생성된다.
4.2 Foreground-Foreground Class Imbalance
전경 클래스(객체) 끼리의 불균형 문제에서 전경 클래스는 over-represented 클래스 및 under-represented 클래스 모두를 뜻한다. 전경 클래스 간의 불균형은 데이터 세트와 샘플링된 미니 배치와 관련되어있다. 각 미니 배치가 데이터 세트의 분포를 반영해야되기 때문에 관련이 있으며, 이 데이터 세트를 불균형이라고 할 수 있다. 배치 샘플링 메커니즘은 학습중에 사용할 입력 경계 상자와 그 하위 집합을 선택하기 때문에 미니 배치 레벨 불균형(mini-batch-level imbalance)이다.
- Foreground-Foreground Imbalance owing to the Dataset : 데이터 세트로 인한 fg-fg 간의 불균형
- Foreground-Foreground Imbalance owing to the Batch : 배치로 인한 fg-fg 간의 불균형
데이터세트로 인한 불균형 문제
객체는 본질적으로 서로 다른 빈도로 영상 내에 존재하기 때문에 데이터 세트에서 객체 클래스 간의 불균형이 존재한다. 이러한 이유로 인스턴스 수가 많은 클래스 즉, over-represented class 는 과적합(overfitting) 될 수 있다. 이를 위해 Generative methods 는 추가적으로 샘플을 학습하여 불균형 문제를 해결 할 수 있다. 또한, 이러한 불균형 문제를 해결하는 다른 방법은 객체 탐지를 위한 "long tail" 분포를 미세 조정하는 것이다. 여기서 long tail 은 인스턴스 수가 부족한 클래스를 뜻한다. 객체 탐지를 위해 long tail 분포를 finetuning 하는 것은 학습 과정에 미치는 영향에 대한 분석을 제공하고, 시각적 관점에서 유사한 클래스에 대해 클러스터링을 사용한다. long tail 분포 분석에서 학습에 영향을 미치는 두가지 요소는 예측의 정확성 그리고 샘플의 수이다. 그렇기 때문에 사전 훈련된 백본 신경망의 마지막 계층의 특징을 기반으로 클래스 간 유사성을 수작업으로 측정하고, 데이터 세트로 인한 불균형 문제를 해결하기 위해 클래스를 계층적으로 그룹핑 한다. 설계된 계층 구조 트리의 각 노드에 대해 분류자(classifier)가 학습되며, 트리의 마지막 노드들에서는 주어진 입력 경계 상자의 최종 결과를 결정하기 위해 SVM 분류기를 사용한다.
배치로 인한 불균형 문제
배치에서 클래스의 분포가 고르지 않기 때문에 편향될 수 있다. 즉, 이미지의 객체 및 클래스 수가 크게 다르기 때문에 이러한 문제가 일어나게 된다. 이 문제를 위한 해결책인 OFB(Online Foreground Balanced) 샘플링이 제안되었으며, 이는 각 샘플링 박스에 확률을 할당하여 이러한 불균형 문제를 배치 레벨에서 해결 할 수 있도록 하였다. 배치 내에서 다른 클래스의 분포는 균일하다. 즉, 이 접근법은 샘플링 중에 적은 수의 positive 를 가진 클래스를 뽑는것을 목표로 하며, 이 방법은 효율적이지만 성능 향상은 기대 할 수 없다.
5절 부터는 다음 포스팅 참조
'AI Research Topic > Object Understanding' 카테고리의 다른 글
| [Object Detection] EfficientNet and EfficientDet (0) | 2020.02.23 |
|---|---|
| [Object Detection] The Car Connection Picture Dataset (4) | 2020.02.03 |
| [Object Detection] darknet 으로 Gaussian YOLOv3 학습하기 (linux) (0) | 2020.01.29 |
| [Paper Review] M2Det : A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network (7) | 2020.01.09 |
| [Object Detection] Gaussian YOLOv3 (0) | 2019.12.27 |