[Paper Review] Rethinking Keypoint Representations, Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation
Paper : https://arxiv.org/abs/2111.08557
Rethinking Keypoint Representations: Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation
In keypoint estimation tasks such as human pose estimation, heatmap-based regression is the dominant approach despite possessing notable drawbacks: heatmaps intrinsically suffer from quantization error and require excessive computation to generate and post
arxiv.org
이번에 리뷰할 논문은 ECCV 2022에 소개된 "Rethinking Keypoint Representations, Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation" 논문입니다. 요즘 pose estimation 분야에서 점점 object detection (= person detection) 개념까지 포함되어 나오고 있는 추세인 듯 하네요!!!!!

본 논문에서는 heatmap based regression은 본질적으로 quantization error가 존재하며, excessive computation to generate and post-process가 필요하다는 단점을 지적하고 있으며, 따라서 개별 키포인트와 공간적으로 관련된 키포인트 집합을 객체로 모델링 하는 방식을 제안합니다. 이는 heatmap-free keypoint estimation 방법이며, dense signle-stage anchor-based detection framework 내에서 동작하게 됩니다. 따라서 이러한 방식을 본 논문에서는 Keypoints And Poses As Objects, KAPAO("Ka-Pow!"로 발음)이라고 합니다.

본 논문에서 main contribution은 아래와 같습니다.
- 객체와 관련된 일련의 키포인트를 추가로 포함하여 기존 객체 표현을 확장하는 pose object 라고 하는 새로운 객체 표현을 제안함. multi-task loss를 사용하여 pose object 를 학습하는 방법을 제안함
- keypoint object와 human pose object를 동시에 탐지하고 예측을 융합하여 single-stage multi person human pose estimation에 대한 새로운 접근 방식을 개발함. heatmap을 사용하는 SOTA 방식과 비교하였을 때, heatmap-free 방법은 COCO, CrowdPose라는 두 가지 벤치마크 데이터세트에서 훨씬 더 빠르고 정확하다는 것을 보여줌.
본 논문에서 제안하는 방식은 다음과 같습니다.
학습에 두가지 표현을 사용하게 되는데, 사람 클래스의 bounding box 를 나타내는 pose object와 사람의 관절 정보를 나타낸 keypoint object를 사용하게 됩니다. 두 객체 표현 모두 고유한 이점이 있으며, keypoint object는 강력한 local feature를 기능으로 하는 individual keypoint를 감지하는데 특화되어있습니다. (예를 들면 눈, 귀 및 코).
그러나 keypoint object는 사람이나 포즈에 대한 정보를 전달하지 않으며, multi persion pose estimation을 위해 자체적으로 사용하는 경우 감지된 키포인트를 human pose로 구문 분석 하기 위해 bottom-up grouping method가 필요합니다. 대조적으로 pose object는 신경망이 일련의 키포인트 내에서 공간 관계를 학습할 수 있도록 하므로 weak local feature를 localization 하는데 더 적합합니다.
keypoint object가 pose object의 하위 공간에 존재하기 때문에 a single, shared network head를 사용하여 최소한의 computational overhead로 두 object 유형을 동시에 감지하도록 신경망을 설계합니다.
먼저 object's intermediate bounding box는 아래와 같이 grid coordinates와 grid cell origin (i, j)에 대해 상대적으로 예측됩니다.
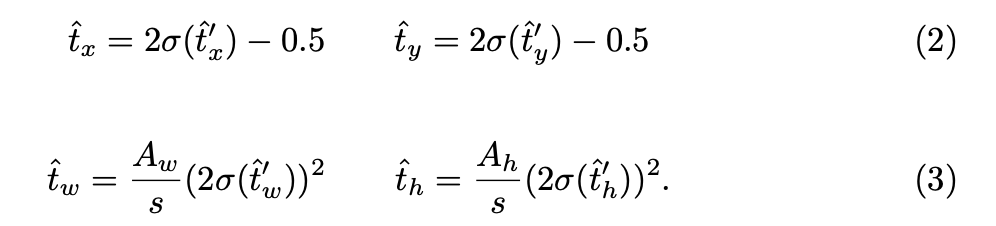
그 다음, 키포인트는 아래와 같이 grid coordinates와 grid cell origin (i, j)에 대해 상대적으로 예측됩니다.
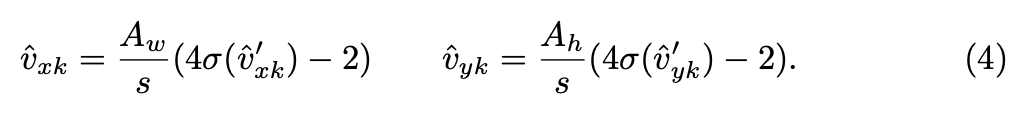
Loss Function은 아래와 같이 설계됩니다. objectness, intermediate bounding box, class score, intermediate pose keypoint에 대한 loss가 계산됩니다. 먼저, objectness는 grid weighting이 적용된 BCE loss가 사용됩니다. 또한 여기서의 IoU는 complete intersection over union(CIoU)를 뜻합니다. bbox에 대해서는 iou 가 사용되고, clssification에서는 BCE가 사용되고, keypoint에 대해서는 mse loss가 사용됩니다. 이 때 keypoint visibility 개념이 사용됩니다.
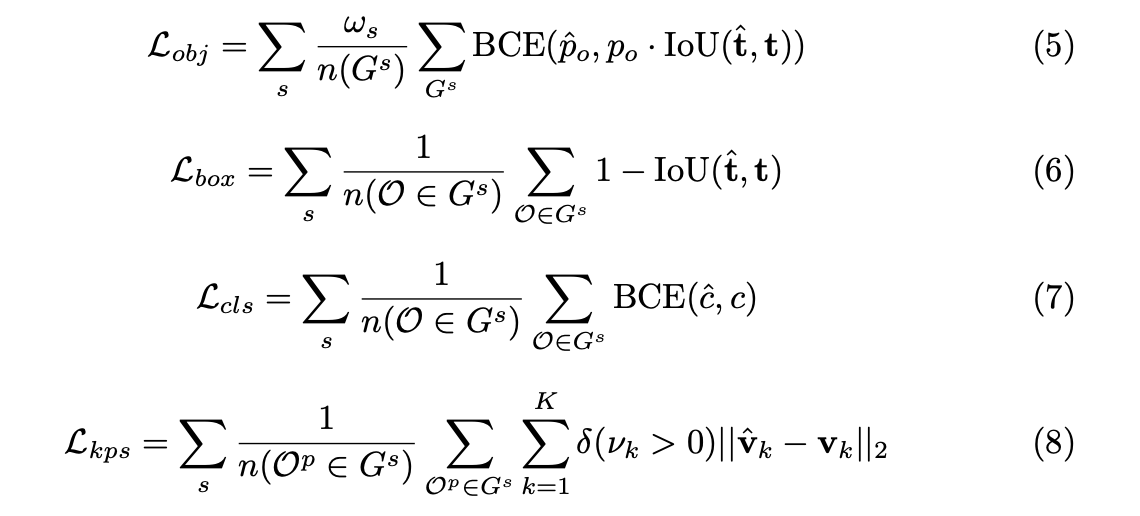
아래와 같이 target이 구성되나 봅니다. 친절하게도 설명을 해놓았네요. 어느새 pose estimation 분야 논문에서는 저 스키 타는 여자 분 사진은 항상 나오는 사진인 듯 합니다.

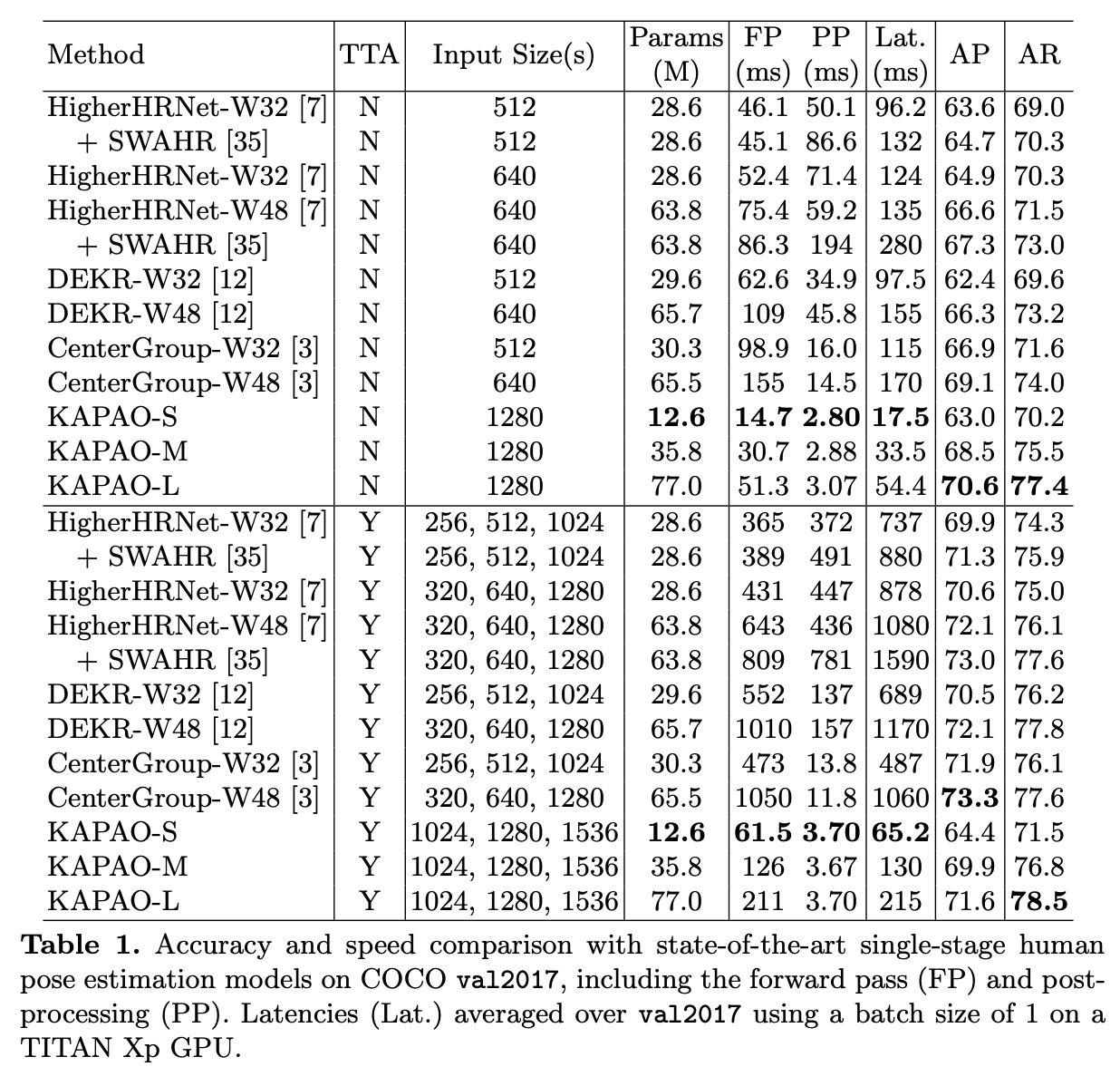
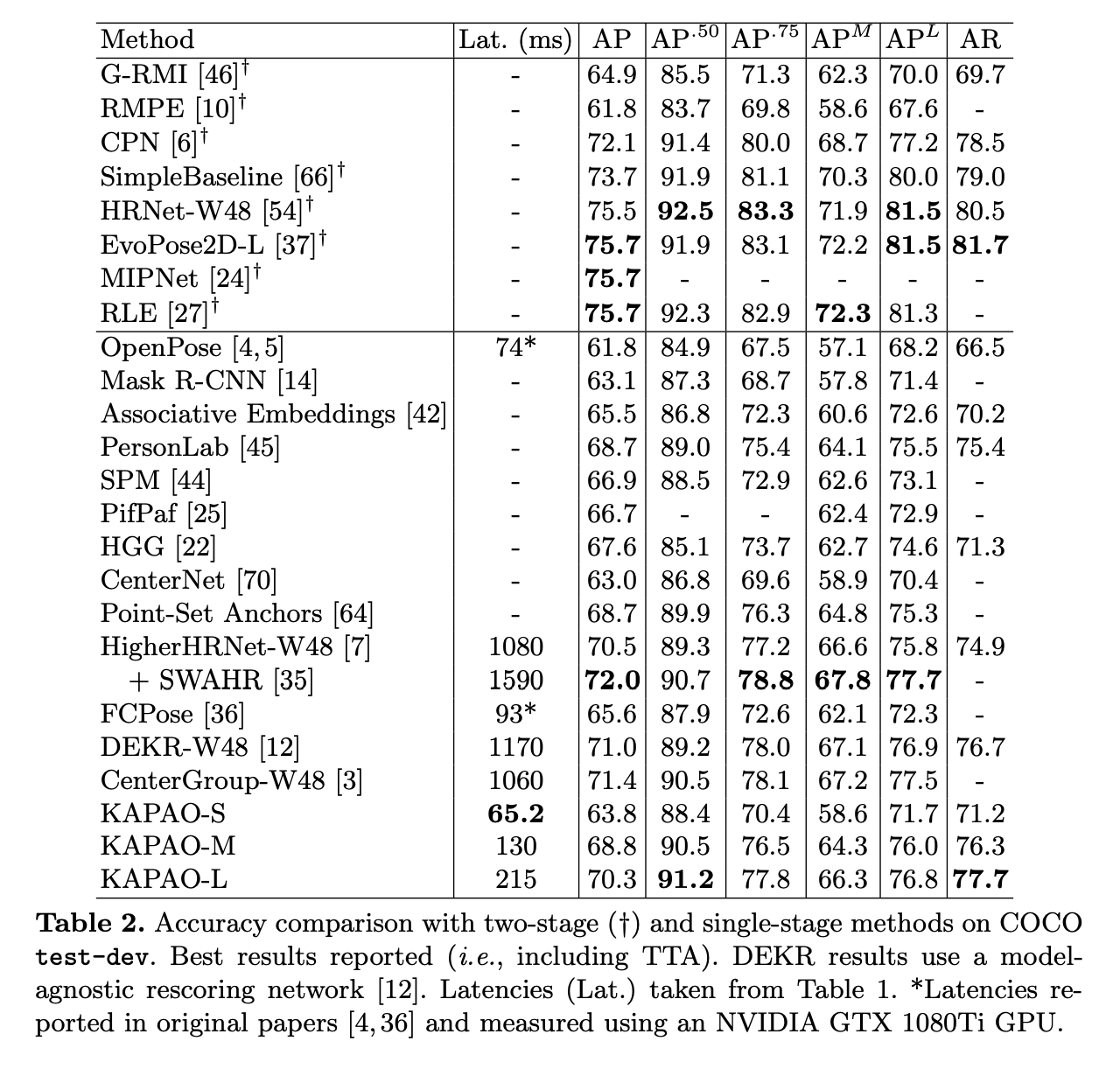
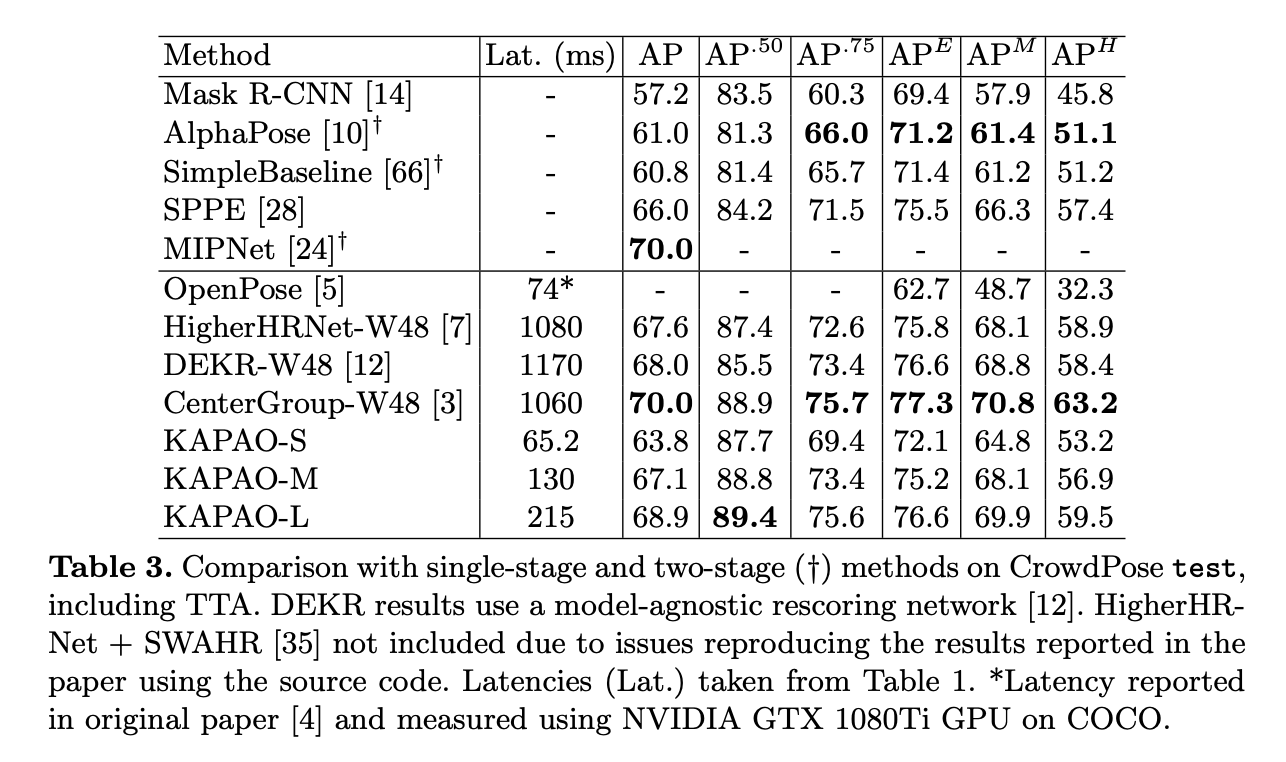
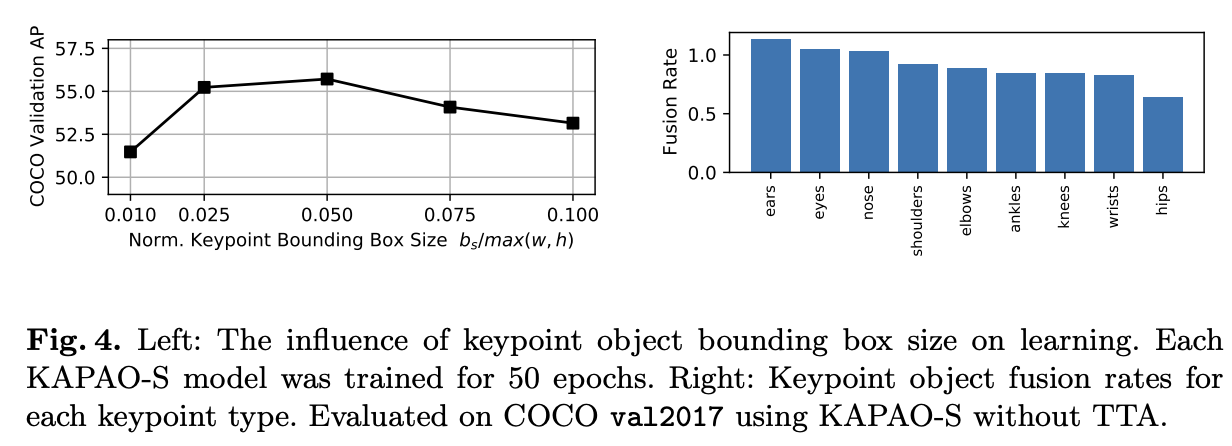
실험 결과는 아래와 같습니다.