[Paper Review] Self-Constrained Inference Optimization on Structural Groups for Human Pose Estimation
Paper : https://arxiv.org/abs/2207.02425
Self-Constrained Inference Optimization on Structural Groups for Human Pose Estimation
We observe that human poses exhibit strong group-wise structural correlation and spatial coupling between keypoints due to the biological constraints of different body parts. This group-wise structural correlation can be explored to improve the accuracy an
arxiv.org
이번에 리뷰할 논문은 "Self-Constrained Inference Optimization on Structural Groups for Human Pose Estimation" 라는 논문이며, "Human Pose Estimation for Real-World Crowded Scenarios" 라는 논문을 인용한 논문들을 찾아보다가 읽게 되었습니다. (참고로 real-world crowded scenario 관련된 논문은 CrowdPose 및 Surveillance 환경에서 pose estimation을 어떻게 robust 하게 동작하게 할지에 대한 문제를 다룬 논문입니다!)
본 논문에서는 human pose 에서 나타나는 strong group-wise structural correlation 및 spatial coupling 문제에 대해 다루게 됩니다. 이러한 group-wise structural correlation를 탐색하여 human pose estimation의 accuracy 및 robustness를 개선할 수 있다고 합니다.
이를 위해 train 중에 keypoint 간의 structural correlation을 특성화 하고, 학습하기 위해 self-constrained prediction-verification network를 개발하였습니다. 추론 과정 중에 feedback information를 통해 pose prediction의 further optimization을 수행할 수 있으므로 성능이 크게 향상한다고 하네요.
먼저 human을 biological structure(생물학적 구조)에 따라 keypoint를 grouping 합니다. 각 group 내에서 keypoint는 high-confidence를 갖는 base keypoint와 low-confidence를 갖는 terminal keypoints 집합으로 나눕니다. 이러한 keypoint 하위 집합에서 orward and backward predictions을 수행하기 위해 self-constrained prediction-verification network를 사용하게 됩니다.
다음 그림과 같이 human pose가 인간의 자유로운 스타일과 유연한 움직임으로 인해 많은 변화를 가지는데, biological structure에 따라 pose가 제한되며, whole body는 upper limbs 및 lower limbs 와 같이 여러 part 로 구성됩니다. 예를 들어 왼쪽 팔과 오른쪽 팔과 같은 body part 가 완전히 다른 스타일과 다른 방향으로 움직일 수 있기 때문에 다른 body part 간의 keypoint correlation가 낮게 유지된다고 합니다. 그러나 동일한 body part 또는 동일한 structural group 내에서 나온 keypoint는 서로에 의해 공간적 제약을 가지게 되는데 이를 unique structural correlation를 탐색함으로써, 예측해낼 수 있다고 합니다.

아래 그림에서는 이 논문에서 주장하는 terminal keypoint의 low-confidence 를 확인 할 수 있습니다. 주로 Left Ear, Right Ear, Left Wrist, Right Wrist, Left Ankle, Right Ankle이 있네요. keypoint group 내에서 발목 및 손목 같은 body part 끝에 위치한 terminal keypoint 가 종종 low-confidence를 나타내는데, 이는 이 keypoint 들이 움직임의 자유도가 훨씬 더 높고, 다른 물체에 의해 더 쉽게 가려지기 때문이라고 합니다.
그래서 본 논문에서는 keypoint를 biological structure 에 따라 6개의 group으로 분할하고, 각 group을 2개의 하위 집합으로 더 분할할 것을 제안합니다. 두 가지 하위 그룹은 terminal keypoint와 base keypoint(나머지 keypoint) 입니다.

train 및 inference 구조는 아래와 같습니다. 백본에서 예측한 모든 keypoint의 heatmap 이 6개의 group으로 분할되고, train 단계에서 각 group은 base keypoint와 terminal keypoint 두 하위 집합으로 나뉩니다. 이 네트워크는 두 하위 집합 간의 structural correlation을 특성화하며, inference 단계에서는 학습된 verification network로부터 나온 예측 결과를 개선합니다. 어떻게 개선하는지 궁금하네요...

일단 grouping은 아래과 같이 이루어집니다. 스켈레톤이 굉장히 찌부 된 모습인데요, group 마다 4개의 keypoint를 가지도록 합니다. 머리 부분 2개, upper 2개, lower 2개로 나누었나봅니다.

학습은 아래와 같이 이루어집니다. 아래 수식과 같이 G를 각 그룹 내의 4개의 keypoint를 나타냅니다. $X_D$는 terminal keypoint 입니다. 예를 들면 1번 그룹에서 $X_D$는 Right Ear 겠네요. $X_A, X_B, X_C$는 나머지 keypoint 입니다.
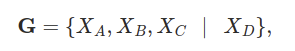
그리고 이에 대응되는 heatmap 수식은 아래와 같습니다.

structural correlation을 학습하기 위해 network 는 visual context 가 포함되어있는 feature map $f$을 통해 base keypoint 로부터 terminal keypoint를 예측합니다.

feature map $f$에는 keypoint estimation을 위한 visual context를 제공하게 됩니다. 아래 식과 같이 verification network 는 prediction network와 동일한 구조를 공유하고, 나머지 3개에서 keypoint $H_A$의 backward prediction을 수행합니다. (이 말이 좀 이해가 안되네요 음~)

prediction network의 prediction output을 input으로 verification network $\Gamma $에 전달하여 이 두 network를 결합하면 다음과 같은 prediction loop를 따릅니다.

self-constraint loss 는 아래와 같습니다.

성공적으로 학습이 진행되면, verification network를 이용하여 예측된 $X_D$가 정확한지 여부를 확인할 수 있으며, self-constraint loss는 local search 에 기반한 prediction $X_D$을 최적화 하기 위한 objective function으로 사용되며, 아래와 같이 나타낼 수 있습니다.

여기서 $\mathbb{H}(\hat{X}_D)$는 gaussian kernel을 이용하여 keypoint $\hat{X}_D$로부터 생성된 heatmap을 나타냅니다. 이는 test sample의 특정 통계를 기반으로 prediction result를 반복적으로 세분화 할 수 있는 효과적인 메커니즘을 제공하고, 이러한 adaptive prediction and optimization은 feedback 및 adaptation 없이 foward 하는 기존 network prediction에서는 사용할 수 없다고 합니다. 이러한 feedback-based adaptive prediction은 test sample에서 더 나은 generalization 기능을 제공하게 됩니다. 이를 이 논문에서는 self-constrained learning (SCL)를 이용한 self-constrained optimization (SCO)라고 합니다. 이에 대해 더 관심 있으신 분들은 3.3 Self-Constrained Learning of Structural Groups을 읽어보시면 좋을 듯 합니다.
그 다음 low confidence를 갖는 keypoint에 대해 inference 단계에서 어떻게 성능을 최적화 시켰는지 보겠습니다. 본 논문에서는 기존 forward process가 training 에서 학습한 지식이 test 세트에 직접 적용이 되고, GT를 사용할 수 없기 때문에 예측 결과가 정확한지 여부를 확인하는 메커니즘이 불가능하다고 지적합니다. 즉, feedback 과정이 필요하다고 말합니다. 그래서 low confidence를 가지는 keypoint를 high-confidence를 가지는 keypoint로 매핑함으로써 해결합니다. self-constraint loss를 이용하여 예측 결과를 정제합니다.

여기서 $\delta $는 keypoint의 search range와 direction을 제어하며 direction은 loss에 따라 동적으로 조정됩니다.
실험 결과는 아래와 같습니다.


아래 그림을 보면 terminal keypoint의 성능이 향상됨을 확인할 수 있습니다.

요 논문은 코드 공개는 안되었나 봅니다!