[Paper Review] CenterNet, Objects as Points
GitHub : https://github.com/xingyizhou/CenterNet
GitHub - xingyizhou/CenterNet: Object detection, 3D detection, and pose estimation using center point detection:
Object detection, 3D detection, and pose estimation using center point detection: - GitHub - xingyizhou/CenterNet: Object detection, 3D detection, and pose estimation using center point detection:
github.com
Paper : https://arxiv.org/pdf/1904.07850.pdf
오늘 리뷰해볼 논문은 Object Detection 쪽에서 이미 유명한 논문인 CenterNet 입니다. 기존 anchor를 사용하는 방식을 anchor-free 방식으로 대체하는데 한 획을 그은 논문이죠 🙂
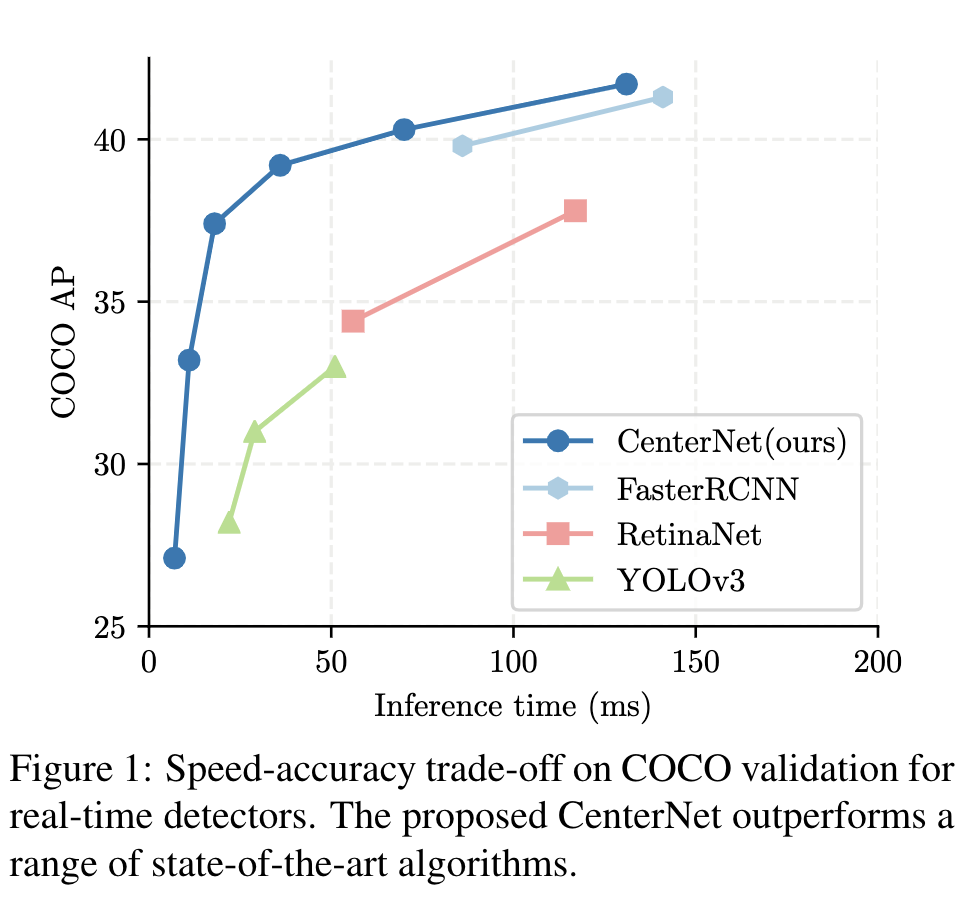
Introduction
Object Detection 분야에서 객체를 탐지할 때 이미지에서 bounding box 형태로 식별하곤 했는데요, 요 논문 전에 CornetNet이 등장하면서 bbox 형태의 식별이 아닌 keypoint 식별로도 탐지가 가능하다는 것을 보여주었습니다. bbox 형태의 detection이 아닌 keypoint detection은 비효율적인 post-processing이 필요없기 때문에 성능면에서 더 좋다고 할 수 있습니다.
CenterNet에서는 object size, dimension, 3D extent, orientation, pose 와 같은 속성들을 center location으로부터 direct regression 하게 됩니다. heatmap 을 생성하는 fully convolutional network에 input image를 넣음으로서 동작하게되고, 이 heatmap의 peak는 object center에 해당하게 됩니다. 각 peak의 image feature는 bounding box의 height 및 width를 예측하게 됩니다. 모델은 standard dence supervised learning으로 학습됩니다. inference 과정에서는 post-processing을 위한 NMS(Non-Maximal Suppression) 과정 없이 이루어집니다.
또한 CenterNet은 각 center point에서 output을 추가하여 human pose estimation 이나 3d object detection의 task로 확장이 가능합니다. pose estimation을 수행하려면 2d joint 위치를 center 로부터의 offset으로 간주하고, center point 위치에서 직접 regression을 수행하면 됩니다. 3d object detection을 수행하려면 object absolute depth, 3d bounding box dimension, object orientation을 regression 하면 됩니다.

Preliminary
이미지를 $I \in R^{W \times H \times 3}$ 라고 하고, 모델의 목표는 keypoint heatmap을 추론하는 것이기 때문에 이 heatmap을 $\hat{Y} \in [0, 1]^{\frac{W}{R} \times \frac{H}{R} \times C}$ 라고 둡니다. 여기서의 $R$은 output stride 이며, $C$는 keypoint type의 number라고 보시면 됩니다. keypoint type은 human pose estimation에서는 17개(17개의 joint)이고, object detection에서는 category 개수인 80개입니다. defalute output stride로 $R = 4$를 사용하게되며, 이를 통해 image가 downsample 됩니다. $\hat{Y}_{x, y, c}$는 올바르게 keypoint가 예측된다면 1 값을 가집니다. 0인 것은 background 라고 보시면 됩니다. 본 논문에서 모델은 fully-convolutional encoder-decoder network는 stacked hourglass network, up-convolutional residual network(ResNet), deep layer aggregation(DLA)을 사용합니다.
keypoint prediction network는 CornerNet 방법을 따르게 됩니다. 각 class에 대한 GT keypoint가 있으면, low-resolution equivalent $\tilde{p} \in R^2$을 계산합니다. 그 다음 Gaussian kernel을 이용하여 heatmap을 생성하여 같은 class의 two gaussian이 겹쳐지면 element-wise maximum을 계산합니다. loss 함수는 아래와 같이 focal loss를 사용합니다.

여기서 $\alpha$와 $\beta$는 focal loss의 hyper-parameter 입니다. $N$은 이미지에서의 keypoint 개수이고, 이는 GT 위치에 대하여 positive focal loss instance 1을 갖게 됩니다. 본 논문에서는 $\alpha = 2$와 $\beta = 4$를 사용하였다고 하네요. discretization error를 개선하기 위해 각 center point로부터 local offset $\hat{O} \in R^{\frac{W}{R} \times \frac{H}{R} \times 2}$을 추가로 계산합니다. 모든 class는 동일한 offset prediction을 공유하게 되며 offset은 다음과 같이 L1 loss로 학습됩니다.
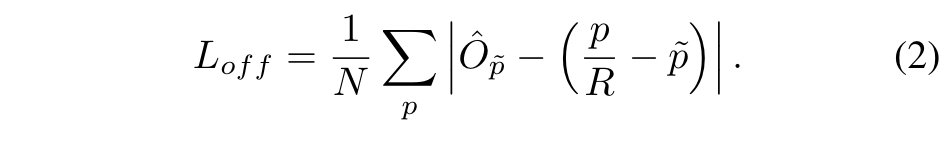
학습은 keypoint location에 대해서만 학습되고, 나머지 location은 무시됩니다.
Objects as points
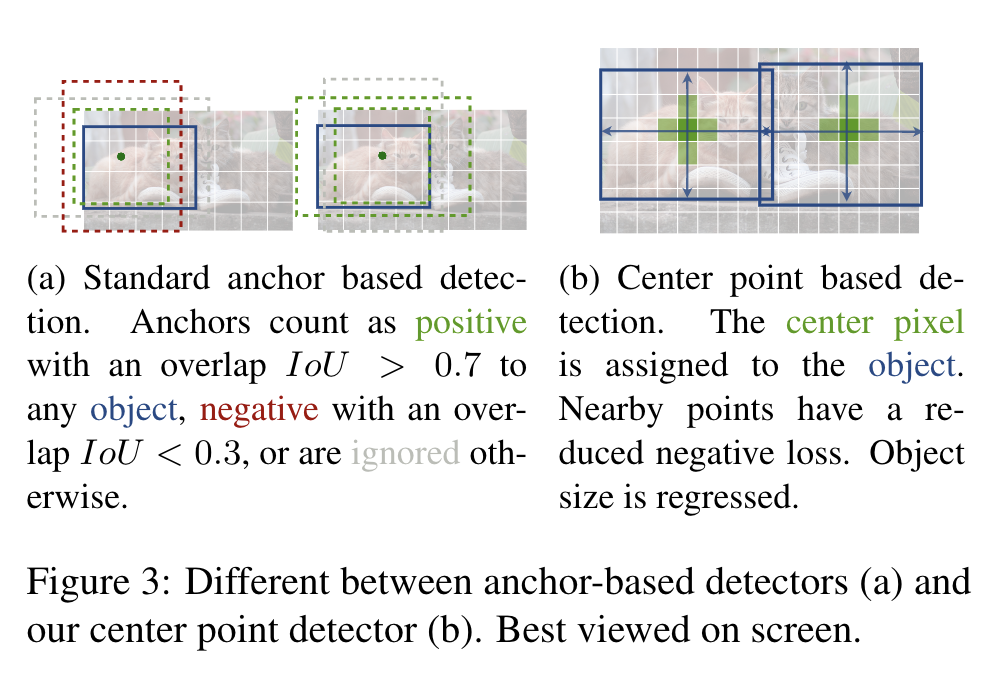
본 논문의 제목이기도 한데요, 이제 이 keypoint estimation을 object detection에 어떻게 적용하였는지 살펴보겠습니다. 먼저 category $c_k$에 속하는 object $k$의 bounding box의 좌표를 $(x_{1}^{k}, y_{1}^{k}, x_{2}^{k}, y_{2}^{k})$ 라고 둡니다. 그 다음 center point $p_k$는 bounding box의 중간으로 설정합니다. keypoint estimator $\hat{Y}$는 모든 center point를 예측하게 됩니다. 그리고 각 object에 해당하는 object size $s_k$를 regression 합니다. $s_k$는 아래와 같이 나타납니다.
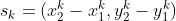
계산 부담을 줄이기 위해 low resolution 상에서 single size에 대하여 prediction을 수행합니다. 이를 위해 아래와 같이 center point에서 L1 loss를 사용하여 size 정보를 regression 합니다.

본 논문에서는 scale을 normalization 하지 않고, 직접 raw pixel coordinate를 사용합니다. 전체 loss는 아래와 같습니다. 여기서는 $\lambda_{size} = 0.1$, $\lambda_{off} = 1$을 사용했다고 하네요.
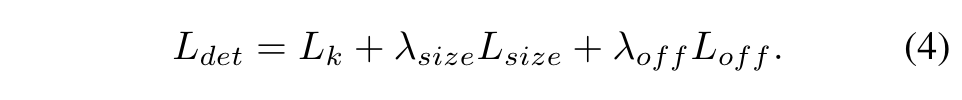
이 네트워크는 각 위치에 대해 총 $C+4$개의 값을 내뱉습니다. 모든 output은 common fully-conv backbone에 공유되며, backbone feature는 $3 \times 3$ conv와 ReLU 함수, $1 \times 1$ conv에 의해 전달됩니다.
From points to bounding boxes
inference time에서 독립적으로 각 category의 heatmap에서 peak 값을 추출합니다. 값이 8-connected neighbor 크거나 같은 모든 response를 찾고, top 100 peaks를 유지합니다. 각 keypoint location은 integer coordinate $(x_i, y_i)$로 나타내고, detection confidence를 heatmap으로부터 추출하고, 해당 위치에서 bounding box를 추출합니다. 모든 output은 IoU-based NMS 또는 다른 post-processing 없이 추출 할 수 있습니다. peak keypoint extraction은 NMS 대신 사용할 수 있으며, $3 \times 3$ max pooling을 통해 구현 될 수 있습니다.
이러한 keypoint 기반 object detection은 3D Detection 분야나 Human Pose Estimation 분야로 확장 될 수 있습니다. 특히 HPE 분야에서는 K개의 keypoint를 추출하면 되겠죠. COCO 기준으로는 17개를 추론하게 됩니다. 그리고 loss 계산 시 invisible keypoint는 고려하지 않는다고 합니다. 이러한 방법은 regression-based one-stage multi person human pose estimator로 부를 수 있습니다. 여기서 center offset은 예전 bottom-up 기반 방식 HPE의 grouping 작업과 비슷하게 작동하여, 가장 가까이에 있는 사람에게 instance를 할당하게 됩니다. keypoint의 confidence는 0.1을 사용하여 걸러냅니다.
Experiments
본 논문에서는 ResNet-18, ResNet-101, DLA-34, Hourglass-104 아키텍쳐에 대해 실험했습니다. ResNet 게열과 DLA-34 계열은 deformable conv layer를 사용하여 수정하였다고 하네요. 각 모델마다 성능은 아래와 같습니다. N.A는 no test augmentation을 나타내고, F는 flip test, MS는 multi-scale augmentation을 나타냅니다.
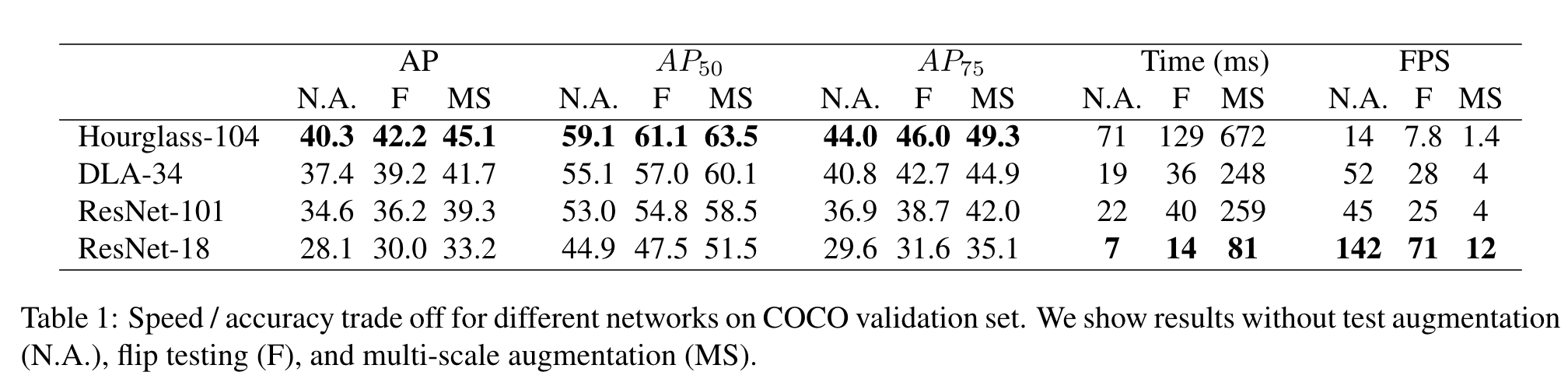
다른 모델들과 비교한 결과는 아래와 같습니다. Hourglass 모델을 이용한건 FPS 7.8을 기록하네요. AP도 좋은 편 같습니다.

CenterNet의 단점은 2개의 객체가 서로 겹친다면, 같은 center point를 가지게 됩니다. 그러면 당연히 객체를 서로 구분 못하게 되는 문제가 발생하겠죠! 결과는 한 개만 나오게 됩니다. 또한 아래 table을 보시면 세번째에 L1 loss와 smooth L1 loss를 비교해놓았습니다. smooth L1 loss 보다 L1 loss가 성능이 더 우수하네요.

그리고 bounding box size weight를 어떻게 주느냐에 따라 실험 성능이 많이 차이났다고 합니다. 0.1로 사용하였을 때 성능이 가장 좋았다고 하네요.