[Paper Review] The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation
Paper : https://arxiv.org/abs/2110.05132
The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation
We introduce CenterGroup, an attention-based framework to estimate human poses from a set of identity-agnostic keypoints and person center predictions in an image. Our approach uses a transformer to obtain context-aware embeddings for all detected keypoint
arxiv.org
GitHub : https://github.com/dvl-tum/center-group
GitHub - dvl-tum/center-group: Official PyTorch implementation of "The Center of Attention: Center-Keypoint Grouping via Attenti
Official PyTorch implementation of "The Center of Attention: Center-Keypoint Grouping via Attention for Multi-Person Pose Estimation" (ICCV 21). - GitHub - dvl-tum/center-group: Official ...
github.com
이번엔 저번에 리뷰했었던 Contextual Instance Decoupling for Robust Multi-Person Pose Estimation 논문 에서 bottom-up 방식 중 SOTA로 언급 되었던 "CenterAttention"의 논문을 읽어보고자 합니다. 이 논문은 ICCV 2021에서 채택 되었네요.

논문 개요
본 논문에서는 indentity-agnostic keypoints와 이미지에서 person center prediction 결과를 이용하여 사람의 자세를 추정하는 attention-based framework인 CenterGroup을 제안했습니다. 이러한 접근 방식은 transformer를 사용하여 검출된 모든 keypoint 및 center에 대한 context-aware embedding을 얻은 후 multi-head attention을 적용하여 joint를 person center로 해당하는 곳에 직접 그룹화 시킵니다. 대부분의 bottom-up 방식은 inference 시에 non-learnable clustering에 의존하지만, CenterGroup 방식은 keypoint detector와 함께 end-to-end 방식으로 학습하는 메커니즘을 사용한다고 합니다. 결과적으로 top-down 방식보다 inference time이 최대 2.5x 더 빠르다고 하네요.
기존 문제
논문에서는 two-step 접근 방식이 별도의 person detector를 사용해야되기 때문에 효율성이 떨어지고, 심한 occlusion이 일어났을 경우 성능이 저하된다고 말하고 있습니다. bottom-up 방식은 먼저 identity-agnostic(정체성에 구애받지 않는) keypoint를 검출 한 다음 이들을 별도의 pose로 그룹화 하기 때문에 다른 접근 방식을 가진다고 합니다. 여기서 identity-agnostic keypoint 개념이 조금 어려운데, 쉽게 풀어 설명하면 이 키포인트가 아직 누구 것인지 모르는 채로 검출되는 것을 말하는 듯 합니다. 흔한 bottom-up 방식의 특징이라고 할 수 있죠! 어쨌든 최근 연구에서는 이러한 방식을 크게 발전 시키긴 했지만 여전히 그룹화 알고리즘은 최적화 알고리즘에 의존적이기 때문에 end-to-end 가 아니며, 느리기도 한 단점을 가지고 있습니다. 또한 일반적으로 학습의 목표가 실제 inference 절차와 잘 맞지 않습니다. keypoint 사이의 유사성을 학습할 수는 있지만, test time에서 그룹화는 differentiable(미분 할 수 없는) 별도의 알고리즘에 의해 수행되기 때문입니다. 최근 one-shot 방식은 최적화 기반 bottom-up 방식에 대한 효율적인 대안입니다. 일반적으로 root node의 위치를 regression 한 다음 keypoint에 대한 offset을 예측하는 것입니다. 이렇게 하면 그룹화 단계가 필요없어지므로 전보다 훨씬 빠를 수 있습니다. 그러나 occlusion 및 scale variation으로 인해 정확도가 떨어지는 편이기 때문에 post-processing에 여전히 힘을 줘야합니다.
Main contribution
그래서 본 논문에서는 이러한 단점들을 보완시켜 attention 기반 새로운 프레임워크를 제안합니다. center node에서 offset을 regression 하는 대신 attention을 사용하여 전체 이미지에서 person center와 keypoint 사이의 best match를 search 합니다. 먼저 heatmap regression을 통해 person center 및 identity-agnostic keypoint에 대한 proposal을 얻게 됩니다. 그 다음 center와 keyoint를 transformer에 제공하여 context 정보를 updated embedding으로 encoding 합니다. 마지막으로 imbedding은 person center와 동일한 pose에 해당하는 keypoint 간의 attention score를 최대화하는 그룹화 방식을 사용하게 됩니다. test time에 가장 높은 attention score를 가진 keypoint를 center에 할당하여 pose estimation을 수행합니다. 그룹화 알고리즘의 단순성과 attention 계산의 병렬 특성으로 인해 SOTA를 달성하게 됩니다.
- end-to-end 방식으로 모델을 학습할 수 있는 multi-head attention formulation으로 keypoint 및 person center 예측을 그룹화하여 pose estimation을 수행
- transformer를 사용하여 bottom-up 방식으로 검출된 keypoint와 ceneter 사이의 종속성을 encoding하여 context-enhanced embedding을 얻고, 제안된 그룹화 방식의 성능을 향상
- SOTA 방법에 비해 최대 2.5x 속도 향상을 제공하는 end-to-end 프레임워크에서 최신 결과를 달성
Multi-Head Attention(MHA) 방식
이 논문에서 제안한 MHA 방식은 각 벡터가 벡터 세트의 multiple regresentation subspace에 집중되도록 하여 정렬되지 않은 벡터 세트에서 context representation을 얻는 것을 목표로 둡니다. n개의 d 차원 쿼리 특징 벡터 집합 및 m 쌍의 키 및 값 벡터 집합이 주어지면 attention head의 연결을 linear 하게 projection 하여 query embedding을 업데이트하게 됩니다.

여기서 $W_o$는 learnable matrix 이며, $d_H$는 dimensionality of each attention head 입니다. 각 attention head는 매 인덱스 마다 계산됩니다.

여기서 attention score는 key와 query 사이의 softmax-normalized dot-product로 계산됩니다.
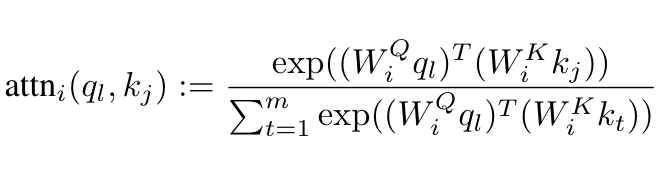
위 식에서 $W_{i}^{Q}$, $W_{i}^{K}$, $W_{i}^{V}$는 learnable projection matrix이다. 이러한 key, query, value가 동일할 때(Q=K=V) transformer encoder의 self-attention을 참조합니다. transformer encoder는 skip-connection 및 layer normalization을 거쳐 self-attention의 initial layer를 쌓은 다음 feed-forward network 및 layer normalization의 second instance에 의해 생성됩니다.
Grouping Keypoints and Centers
입력 이미지가 주어지면 이미지의 모든 사람에 해당하는 pose set을 얻는 것을 목표로 하며, J는 joint number를 나타내고, joint visibility에 의해 고유하게 결정 될 수 있습니다. joint가 보인다면 1, 보이지 않는다면 0을 할당하게 됩니다. 또한 사람의 center location을 C로 둡니다. one-shot 방식은 예측된 사람의 중심 좌표를 직접 사용하고 비용이 많이 드는 그룹화를 피하기 위해 center에서 joint location으로 displacement offset을 regression 하게 됩니다. 이러한 방식에 영감을 받아 similarity score $sim_i(c, k)$ 를 학습하여 자세를 추정합니다. keypoint pair 사이의 유사성과 반대로 center node와 keypoint 사이의 유사성을 추정할 수 있습니다. 그룹화 작업을 nearest-neighbor search 문제로 풀게 됩니다. 그 다음 모든 joint type 에 대해 학습된 embedding space에서 내적을 계산하여 similarity score를 얻습니다. 그 다음 softmax 연산으로 score를 정규화 하여 미분 할 수 없는 인수 최대 값을 대체하게 됩니다. codfficient는 학습 중에 모든 joint 및 모든 person center에 대한 keypoint 위치를 직접 예측하는데 사용하게 됩니다. 아래 식에서 $loc_k$는 검출된 keypoint k의 좌표입니다. 아래 식에서 나온 $loc_k$는 GT 위치에 대해 L1 loss를 직접 계산하여 최소화 할 수 있습니다.



정리해보자면 아래와 같이 요약 할 수 있습니다.
1. keypoint and center detection
identity-agnostic keypoint와 person ceneter의 위치는 HigherHRNet에 따른 heatmap regression으로 얻습니다. output은 가변적인 수의 high-scoring joint 및 person center detection입니다.
2. Encoding keypoints and centers
검출된 모든 keypoint와 center에 대해 CNN backbone에서 feature를 추출하고 spatial location을 encoding하는 additinal embedding으로 feature를 보완합니다. 이러한 embeddingdms transformer에 feed 되어 향상된 context information으로 업데이트된 embedding을 생성하게 됩니다.
3. Keypoint grouping
이전 단계에서 얻은 embedding을 사용하고 person center와 keypoint 사이의 내적 attention을 계산하고 soft-assignment를 얻기 위해 정규화 과정을 거칩니다. 또한 transformer embedding을 사용하여 center node를 true or false로 분류해내고 각 keypoint의 visible 정보를 결정하게 됩니다.
Experiments
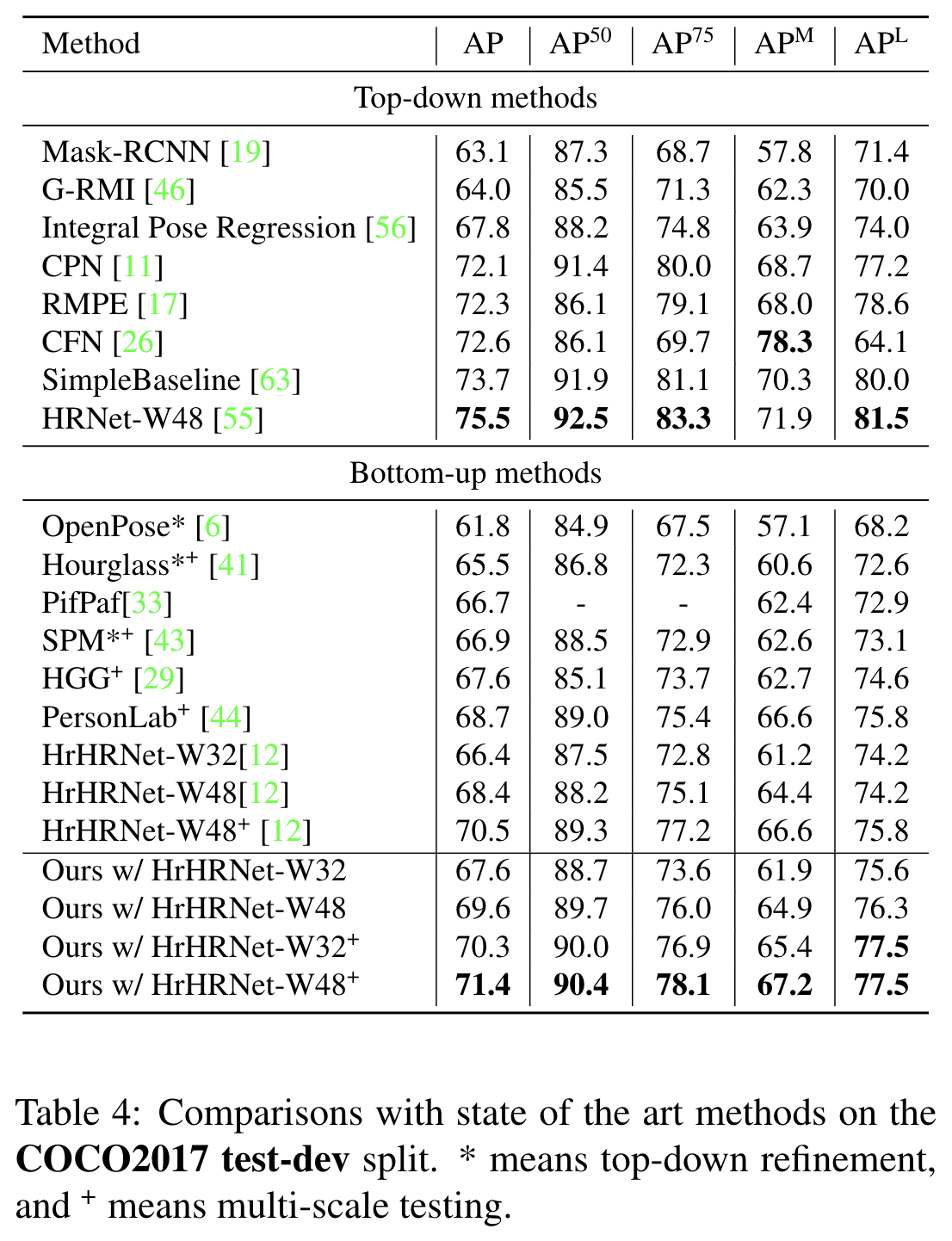
각 COCO 및 CrowdPose 에서 벤치마크 한 결과는 아래와 같습니다.