[Paper Review] YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
GitHub : https://github.com/TexasInstruments/edgeai-yolov5/tree/yolo-pose
GitHub - TexasInstruments/edgeai-yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite. Contribute to TexasInstruments/edgeai-yolov5 development by creating an account on GitHub.
github.com
이번에 소개할 논문은 YOLO 프레임워크를 이용한 Human Pose Estimation 방법인 YOLO-Pose 입니다. CVPR 2022에 소개되기도 하였네요!
논문 개요
본 논문에서 제안하는 모델은 single forward pass에서 여러명의 사람과 2d pose에 대한 bbox를 검출하는 방법을 학습하므로 bottom-up, top-down 방식의 장점을 모두 가진다고 제안합니다. 이러한 접근방식은 검출된 keypoint들을 skeleton으로 그룹화 하기 위한 post-processing이 필요 없다고 합니다. 왜냐면 anchor와 연결된 keypoint는 이미 그룹화 되어있기 때문에 추가적인 그룹화 작업이 필요 없다고 합니다. post-processing이 아예 없는 것은 아니고, object detection에서 사용하는 표준 NMS를 사용한다고 하네요. 또한 COCO validation 세트에서 SOTA를 달성합니다.
기존 문제
본 논문에서는 기존 heatmap 기반 two-stage 방식이 end-to-end로 학습이 불가능하고, 학습 시 evaluation metric에 최적화 되지 않은 L1 Loss에 의존한다는 것을 지적합니다.
Main Contribution
- scale variation 및 occlusion과 같은 주요 문제는 공통적인 문제이기 때문에 object detection에 따라 multi-person pose estimation 하는 방법을 소개합니다. 이 두 분야를 하나로 통합하기 위한 first step 이라고 하네요.
- heatmap이 없는 접근 방식은 pixel level NMS, adjustment, refinement, line-integral, various grouping algorithm 등 을 포함하는 복잡한 post-processing 대신 object detection의 post-processing을 사용합니다.
- box detection에서 keypoint로 IoU loss 개념을 확장했습니다. OKS(object keypoint similarity)는 evaluation에서만 사용되는 것이 아니라 학습 시에도 loss로 사용하게 됩니다. OKS loss는 scale-invariant 하며 본질적으로 다른 keypoint에 각 다른 가중치를 부여하게 됩니다.
- ~4x 정도 적은 컴퓨팅으로 SOTA AP50을 달성합니다. 예를 들어 coco test-dev2017 데이터세트에서 Yolo5m6-pose는 AP50 기준 283.0 GMACS에서 89.4의 성능을 달성한 SOTA DEKR과 비교하여 66.3 GMACS을 달성하게 됩니다.
- joint detection 및 pose estimation framework를 제안합니다. pose estimation은 object detection network에서 거의 무료로 제공된다고 표현하고 있네요 ㅋㅋ
- EfficientHRNet과 같은 real-time 중심 모델 보다 성능이 훨씬 뛰어나고, 복잡성이 낮은 변형된 모델을 제안합니다.
YOLO-Pose
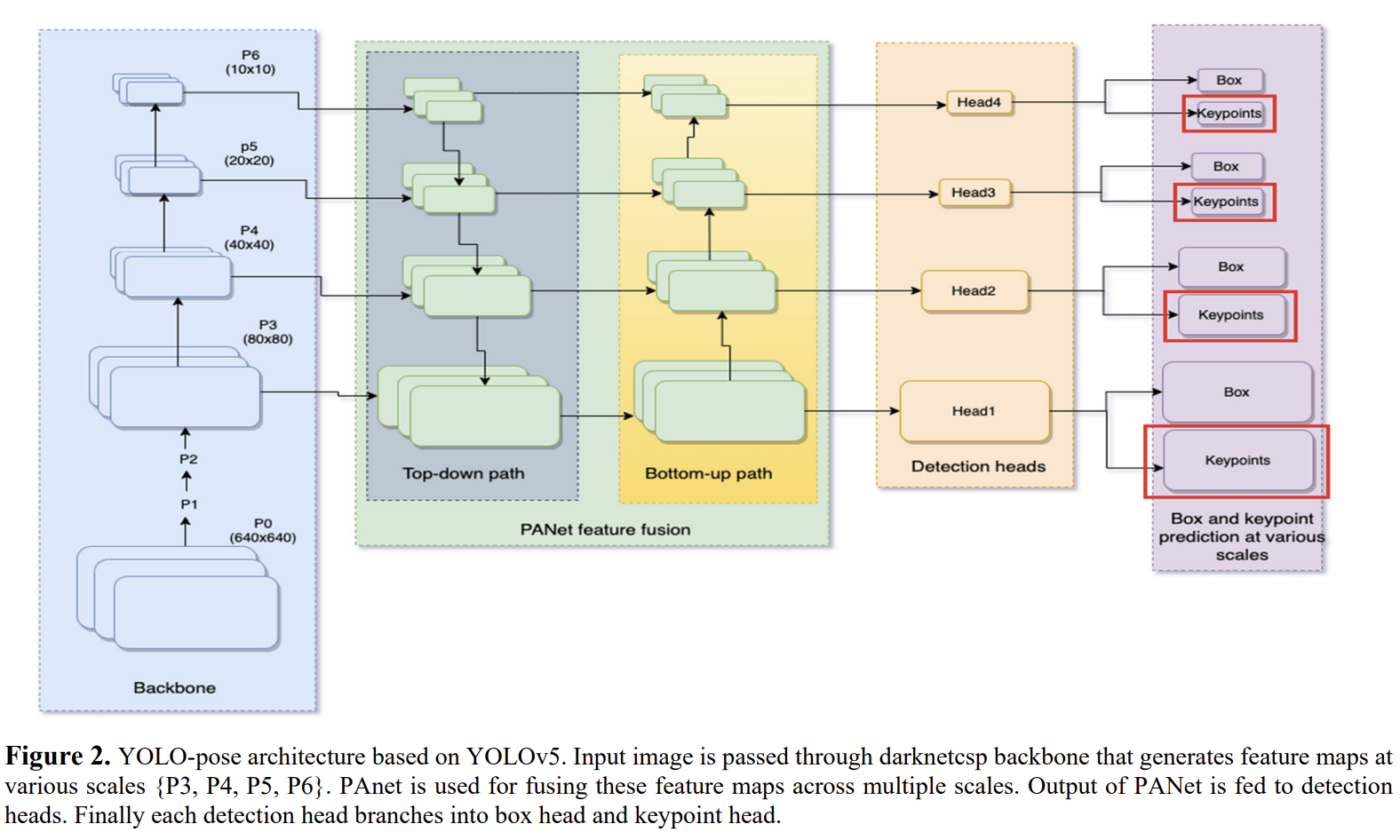
YOLO-Pose 모델은 YOLOv5 모델을 기반으로 설계되었으며, 이 모델은 주로 anchor 당 85개의 요소를 예측하는 box head를 사용하여 80개의 클래스를 검출하게 됩니다. 80개 클래스에 대한 bounding box, object score, confidence score가 있습니다. 또한 각 grid에 해당하는 모양이 다른 3개의 anchor가 있고, pose estimation의 경우 각 사람이 17개의 연관된 keypoint를 갖는 single class person detection 문제로 정의되며, 각 keypoint는 location과 confidence로 식별됩니다. 따라서 anchor와 관련된 17개의 keypoint에 대해 51개의 요소가 존재하며, 각 anchor에 대해 keypoint head는 51개의 요소를 예측하게 되고, box head는 6개의 요소를 예측하게 됩니다. n개의 keypoint가 있는 anchor의 경우 overall prediction vector는 다음과 같이 정의됩니다.

keypoint confidence는 해당 keypoint의 visibility flag를 기반으로 학습됩니다. keypoint가 보이거나(visible) 가려지면(occluded) GT confidence는 1로 설정되고, 이미지 내에 없으면 0으로 설정됩니다. 추론 시 confidence가 0.5 보다 크다면 해당 keypoint는 유효하다고 판단하며, 이 외에 다른 keypoint는 reject 됩니다. confidence 개념은 evaluation에서는 사용되지 않습니다. 그러나 네트워크는 각 detection 된 결과에 대해 17개의 keypoint를 모두 예측하게 되므로 이미지 밖에 위치하는 keypoint를 필터링해야합니다. 필터링하지 않을 경우 dangling keypoint(달랑달랑 키포인트..)가 생겨 skeleton이 변형된다고 합니다.
YOLO-Pose는 CSP-darknet53을 backbone으로 사용하고, backbone에서 다양한 scale의 feature를 합치기 위해 PANet을 사용합니다. 그 다음 크기가 다른 4개의 detection head가 존재하고, 마지막으로 box와 keypoint를 예측하기 위한 2개의 분리된 head가 존재합니다. 이 작업에서 본 논문에서는 복잡성을 150 GMACS로 제한하고, 그 내에서 경쟁력 있는 결과를 달성하게 됩니다.
주어진 이미지에 대해 사람과 일치하는 anchor는 bbox와 함께 전체 2d pose를 저장하고, bbox 좌표는 anchor 중심으로 변환되는 반면, box scale은 anchor의 높이와 너비에 대해 normalization 됩니다. 마찬가지로 keypoint의 위치도 anchor center로 변환됩니다. 그러나 keypoint는 anchor의 높이와 너비로 normalization 하지 않습니다. keypoint 와 bbox 모두 anchor 중심으로 예측됩니다. 따라서 anchor의 너비와 높이와 무관하기 때문에 YOLOX, FCOS와 같은 anchor-free 기반 접근 방식으로 쉽게 확장이 가능합니다.
IoU Based Bounding-box Loss Function
대부분의 object detector는 box detection을 위해 distance-base loss 대신 GIoU, DIoU, CIoU와 같은 IoU loss의 변형된 형태를 사용하는데, 이러한 loss들은 scale-invariant이며, evaluation metric을 직접 최적화 하게 됩니다. 본 논문에서는 bbox supervision을 위해 CIoU를 사용합니다. 또한 $k^{th}$ anchor와 일치하는 GT bbox의 경우 location $(i, j)$ 및 scale s에서 anchor 및 loss는 다음과 같이 정의됩니다.

여기서 $Box_{pred}^{s, i, j, k}$는 location $(i, j)$ 및 scale s에서 $k^{th}$ anchor의 predicted box를 나타냅니다. 본 논문의 경우 각 location에 3개의 anchor가 있으며, prediction은 4개의 scale로 발생하게 됩니다.
Human Pose Loss Function Formulation
OKS는 keypoint를 평가하는데 가장 널리 사용되는 metric입니다. 일반적으로 heatmap 기반 bottom-up 접근 방법은 L1 loss를 사용하여 keypoint를 검출하게 됩니다. 그러나 L1 loss는 최적의 OKS를 얻는데 적합하지 않을 수 있습니다. L1 Loss는 굉장히 단순하며 객체의 scale이나 keypoint의 type을 고려하지 않습니다. heatmap은 probability map으로 순수 heatmap 기반 접근 방식에서는 OKS를 사용할 수 없습니다. OKS는 keypoint 위치를 regression 할 때만 loss function으로 사용할 수 있습니다.
Geng et. al. [30] 연구에 의하면 OKS loss를 사용하기 위한 단계인, keypoint regression을 위한 scale normalized L1 Loss를 제안합니다. anchor center에서 직접 keypoint를 regression 하게 되므로 evaluation metric에 최적화하여 학습할 수 있습니다. 여기서 IoU loss 개념을 keypoint로 확장할 수 있습니다. OKS Loss는 scale-invariant이며, 특정 keypoint에 더 많은 중요성을 부여하게 됩니다. 예를 들면 사람 머리의 키포인트(눈, 코, 귀)는 사람 신체의 키포인트(어깨, 무릎, 엉덩이 등)보다 동일한 픽셀 수준 오류(pixel-level error)에 대해 더 많은 패널티를 받습니다. 이러한 weighting factor는 redundantly annotated validation image에서 COCO author가 경험적으로 선택했다고 합니다. 겹치지 않는 경우에 대한 gradient vanishing으로 인해 어려움을 겪는 vanilla IoU Loss와는 달리 OKS Loss는 절대 정체되는 현상이 없다고 합니다. 따라서 OKS Loss는 dIoU Loss와 유사하다고 하네요. 따라서 GT bbox가 location $(i, j)$ 및 scale s에서 anchor와 일치하면 anchor 중심을 기준으로 keypoint를 예측합니다. OKS는 각 keypoint에 대해 개별적으로 계산된 다음 합산되어 final OKS Loss 또는 keypoint IoU Loss를 제공합니다.

각 keypoint에 해당하는 keypoint가 해당 사람의 것인지의 여부를 나타내는 confidence parameter를 학습하게 됩니다. 여기서 keypoint에 대한 visible flag가 GT로 사용됩니다.
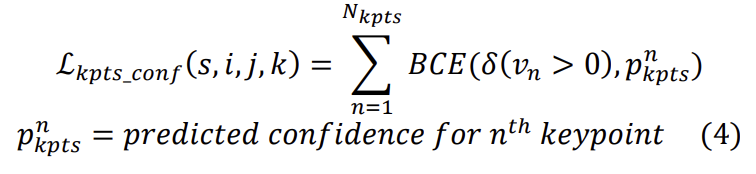
location $(i, j)$에서의 loss는 GT bbox가 해당 anchor와 일치하는 경우 scale s의 $k^th$ anchor에 대해 유효하다고 할 수 있습니다. 마지막으로 total loss는 다음과 같습니다.

YOLO-Pose의 장점 중 하나는 keypoint가 예측된 bbox 안에 있어야한다는 제약이 없다는 것입니다. 따라서 keypoint가 occlusion으로 인해 bbox 외부에 있는 경우 올바르게 인식 될 수 있습니다. 보통 top-down 기반 방법에서는 keypoint가 bbox에 의존적이기 때문에 제약이 있습니다.

Experiments
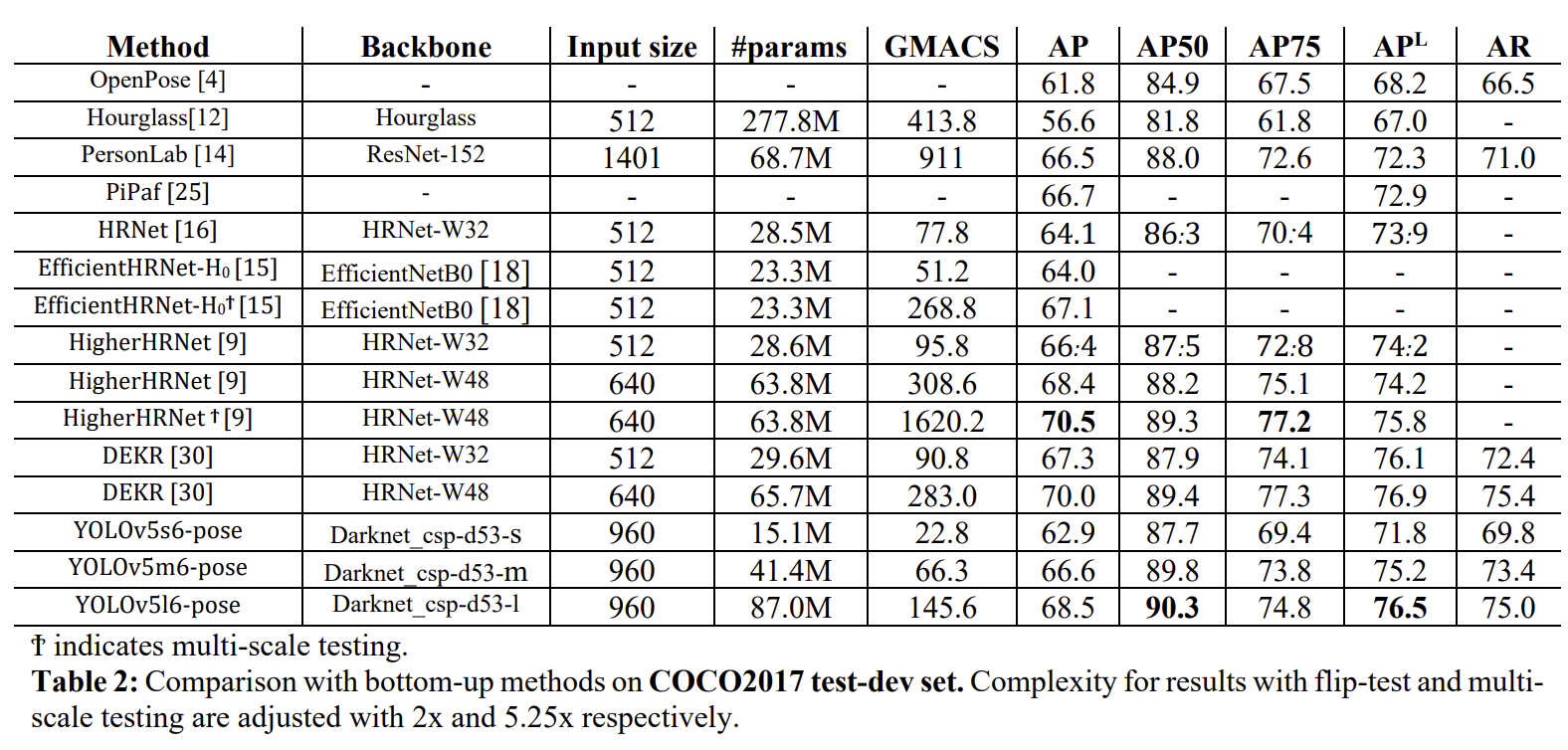
COCO 데이터세트 (val, test-dev)에서 평가한 결과는 아래와 같습니다.

OKS Loss, L1 Loss에 따른 실험 결과는 아래와 같습니다. OKS Loss를 사용하였을 때 L1 Loss에 비해 AP 기준 약 5% 정도 성능 향상이 있네요. 임팩트 있는 결과 같습니다.

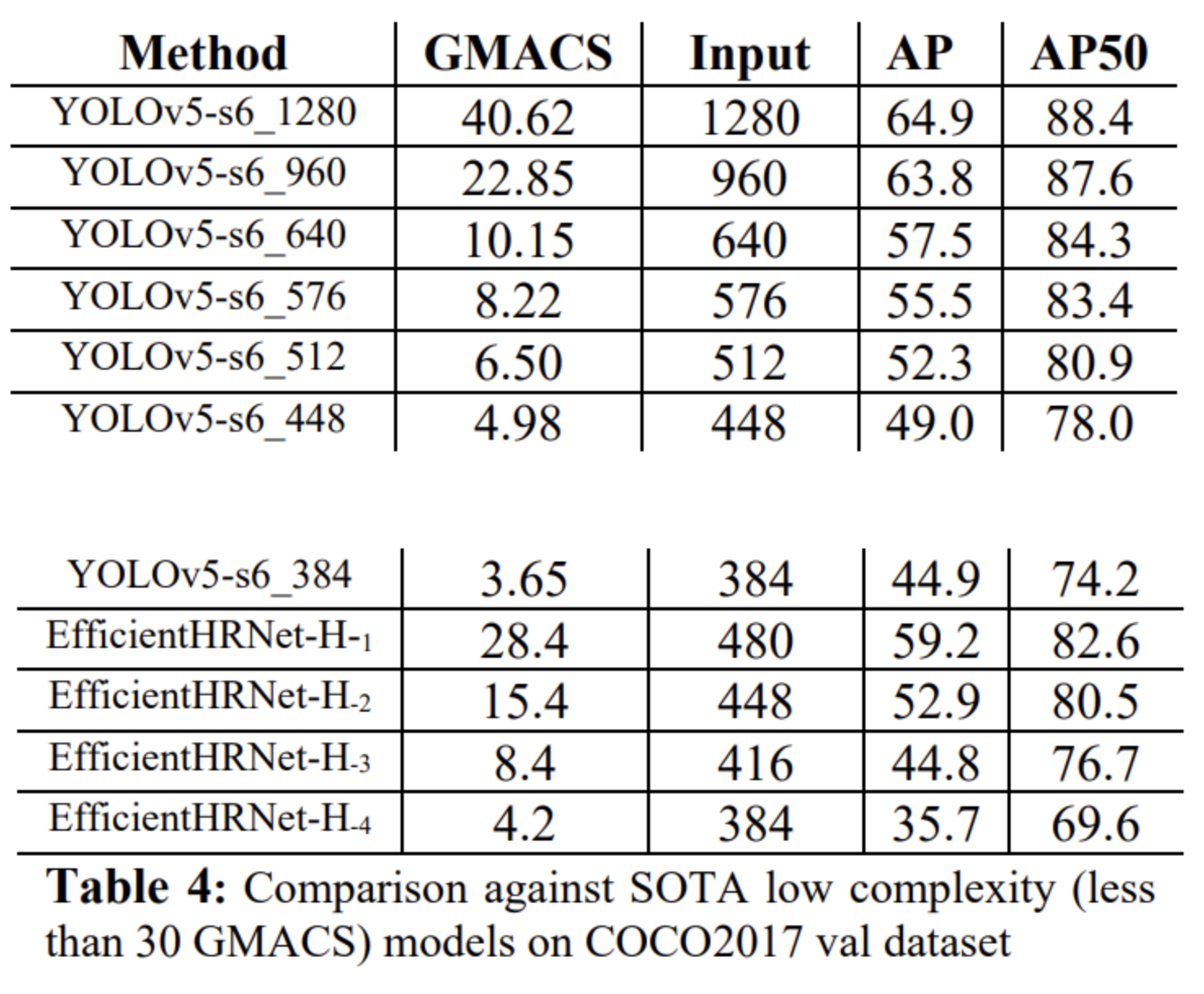
complexity를 비교한 결과는 아래와 같습니다. 30 GMACS 이하여야 low complexity 라고 하네요. 확실히 input size에 비례하는 듯 하고, 동일 input size 대비 EfficientHRNet과 비교하였을 때 YOLO가 더 복잡도가 낮으며, AP도 높은 것을 확인할 수 있습니다.
Quantization 한 결과도 볼 수 있습니다.

마지막으로 Qualitative result 입니다.
