[Paper Review] MDM: Human Motion Diffusion Model
Paper : https://arxiv.org/pdf/2209.14916.pdf
GitHub : https://github.com/GuyTevet/motion-diffusion-model
GitHub - GuyTevet/motion-diffusion-model: The official PyTorch implementation of the paper "Human Motion Diffusion Model"
The official PyTorch implementation of the paper "Human Motion Diffusion Model" - GitHub - GuyTevet/motion-diffusion-model: The official PyTorch implementation of the paper "Human Mo...
github.com
Project page : https://guytevet.github.io/mdm-page/
MDM: Human Motion Diffusion Model
Natural and expressive human motion generation is the holy grail of computer animation. It is a challenging task, due to the diversity of possible motion, human perceptual sensitivity to it, and the difficulty of accurately describing it. Therefore, curren
guytevet.github.io
Youtube : https://youtu.be/9MqPxlwx2CQ
Introduction
이번에 소개할 논문은 2022년에 소개된 human motion을 위한 classifier-free, diffusion-based generative model인 MDM(Motion Diffusion Model)입니다. 요즘 핫한 diffusion을 이용한 모델 중 하나인데요, text를 쓰면 human motion을 자동으로 생성해주는 모델입니다. 며칠 전 카카오브레인에서 비슷한 연구인 FLAME 모델을 발표했는데요, MDM 보다 FLAME 성능이 좋다고 하여 MDM 논문부터 읽어보게 되었습니다.

이 논문에서 주목할만한 design-choice는 diffusion step에서 noise가 아닌 sample의 예측이라는 것 입니다. (참고로 diffusion model에서는 noise를 발생시켜 학습하게 됩니다.) 이는 foot contact loss와 같은 motion의 location 및 velocity에 대해 설정된 geometric loss의 사용을 용이하게 합니다. MDM은 다양한 conditioning mode와 다양한 생성 작업을 가능하게 하는 일반적인 접근 방식이라고 할 수 있습니다. 이 모델은 lightweight resource로 학습되었는데도 불구하고 text-to-motion 및 action-to-motion task에 대한 SOTA를 달성했습니다.

먼저, MDM은 U-net backbone 대신 transformer 기반 모델이며, 모델이 가볍고 motion data(joint collection)의 temporal 및 non-spatial 특성을 잘 반영할 수 있습니다. 또한 다양한 형태의 conditioning을 가능하게 합니다. text-to-motion, action-to-motion, unconditioned generation의 3가지 작업을 수행할 수 있습니다. text-to-motion 작업에서 MDM 모델은 HumanML3D 및 KIT에서 SOTA를 달성합니다. single mid-rage GPU에서 3일만 training 하면 된다고 하네요.
Motion Diffusion Model
이 모델의 목표는 임의의 condition $c$에서 human motion을 합성하는 것입니다. 이러한 condition은 audio, natural language(text-to-motion) 또는 discrete class(action-to-motion)와 같이 synthesis를 나타내는 real-world signal 일 수 있습니다. 또한 unconditioned motion generation도 가능하며 이를 null condition c = ∅ 로 표시합니다. 생성된 motion $x^{1:N} = \left\{ x^i \right\}_{i=1}^{N} $ 는 joint rotation 또는 position $x^i \in \mathbb{R}^{J \times D}$으로 표현되는 human pose이며, 여기서 $J$는 joint의 수이고, $D$는 joint representation의 dimension 입니다. MDM은 location 또는 rotation 또는 둘 다로 표현 할 수 있습니다.
Framework
Diffusion은 Markov nosing process로 모델링 됩니다. $\left\{ x^{1:N}_{t} \right\}_{t=0}^{T}$, 여기서 $x^{1:N}_{0}$은 data distribution에서 도출되고, 아래 식을 따릅니다. 여기서 $\alpha \in (0, 1)$는 constant hyper-parameter 입니다. $\alpha_t$ 가 충분히 작으면 $x^{1:N}_{t} \sim N(0, I)$ 을 근사할 수 있습니다. 여기서 $x_t$는 noising step $t$의 full sequence를 나타냅니다.
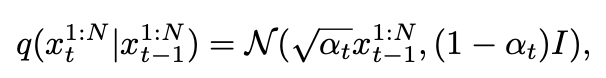
여기서 conditioned motion synthesis는 distribution $p(x_0 | c)$를 점진적으로 cleaning 하는 reversed diffusion process인 $x_T$를 모델링 하게 됩니다. $\epsilon_t$를 예측하는 대신 Ramesh et al. (2022)에 소개된 방법을 따릅니다. 또한 signal itself를 예측하게 됩니다. 이 방법은 simple objective (Ho et al., 2020)에 소개되어있습니다.
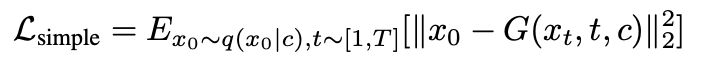
Geometric losses
motion domain에서 generative network는 geometric loss를 사용하여 표준 정규화 됩니다. 이러한 loss는 물리적인 특성을 이용하게 되고 artifact를 방지하여 자연스럽고 일관적인 동작을 생성하게끔 만듭니다. 이 작업에서 position(in case we predict rotations), foot contact, velocity를 조절하는 loss를 사용합니다.
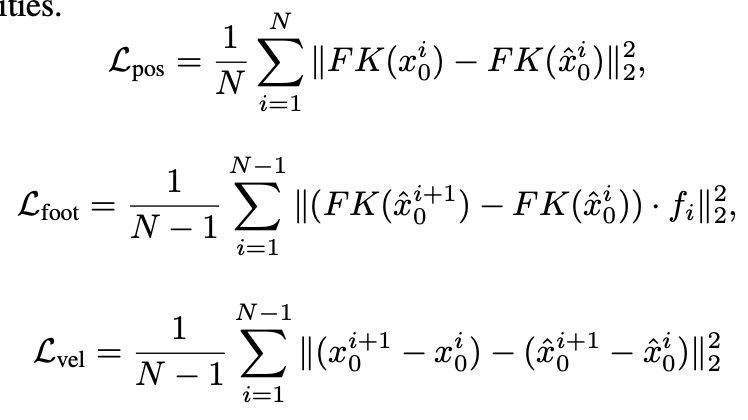
joint rotation을 예측하는 경우 $F K (\cdot) $은 joint rotation을 joint position으로 변환하는 kinematic function을 나타냅니다. 그렇지 않으면 identity function을 나타냅니다. $f_i \in \left\{ 0, 1 \right\} ^J$는 각 frame i에 대한 binary foot contact mask 입니다. footd에만 해당되며 ground에 닿았는지 여부를 나타내고, binary GT data에 따라 설정됩니다. ground에 닿았을 때 velocity를 무효화하여 발이 미끄러지는 현상(foot-sliding effect)를 완화합니다. total loss는 아래와 같습니다.
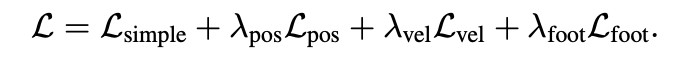
Model
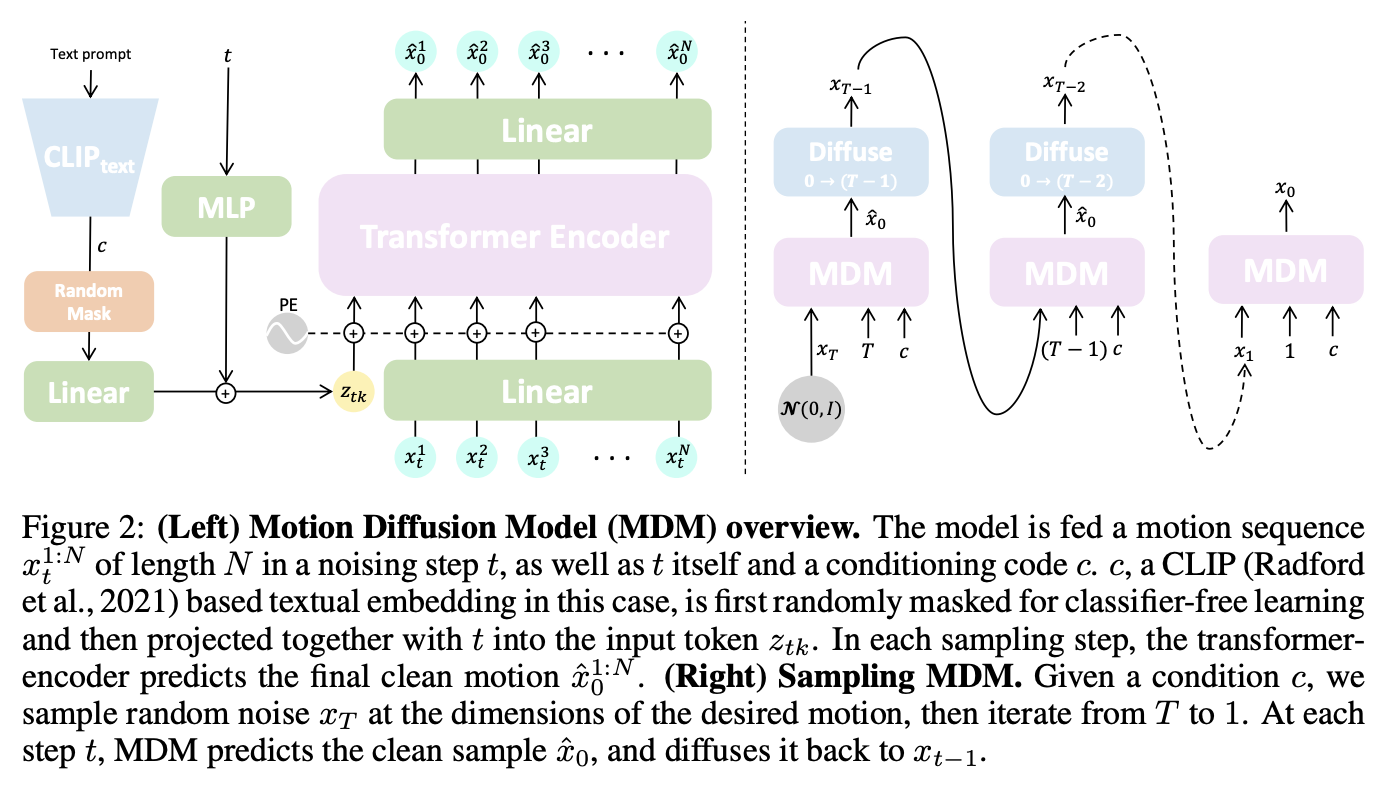
모델 G는 아래 그림과 같습니다. encoder-only architecture로 straight forward trans-former (Vaswani et al., 2017)를 구현합니다. transformer architecture는 temporally aware 되게 임의의 length motion을 학습할 수 있으며 motion domain에 대해 well-proven 입니다. noise time-step 및 condition code care는 각각 별도의 feed-forward network에 trasnformer dimension으로 투영된 다음 합산되어 token $z_{tk}$를 산출합니다. noise가 있는 입력 $x_t$의 각 frame은 transformer dimension으로 선형적으로 투영되고 standard positinal embedding으로 합산됩니다. $z_{tk}$와 투영된 frame은 encoder로 공급됩니다. 첫번째 output token을 제외하고 encoder 결과는 원래 motion dimension으로 다시 투영되며 prediction $\hat{x}$ 역할을 합니다. CLIP으로 text prompt를 encoding하여 text-to-motion을 구현하고 class 별로 embedding을 사용하여 action-to-motion을 구현합니다.
Sampling
$p(x_0 | c)$로부터 sampling은 Ho et al. 방법에 따르면 반복적인 방식으로 수행됩니다. 모든 time step $t$에서 clean sample을 예측하고 $x_{t-1}$로 다시 noise 처리 합니다. 이는 $t_0$이 달성될 때 까지 $t = T$ 에서 반복됩니다. 본 논문의 모델 G를 classifier-free guidance로 학습합니다.
실제로 G($x_t$, t,∅)가 $p(x_0)$에 근접하도록 sample 10%에 대해 c=∅를 무작위로 설정하여 conditioned and unconditioned distribution을 모두 학습합니다. 그 다음 G를 sampling 할 때 다음을 사용하여 두 변형을 보간하거나 extrapolating 하여 diversity and fidelity의 trade-off를 만족할 수 있습니다.
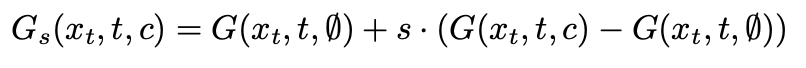
Editing
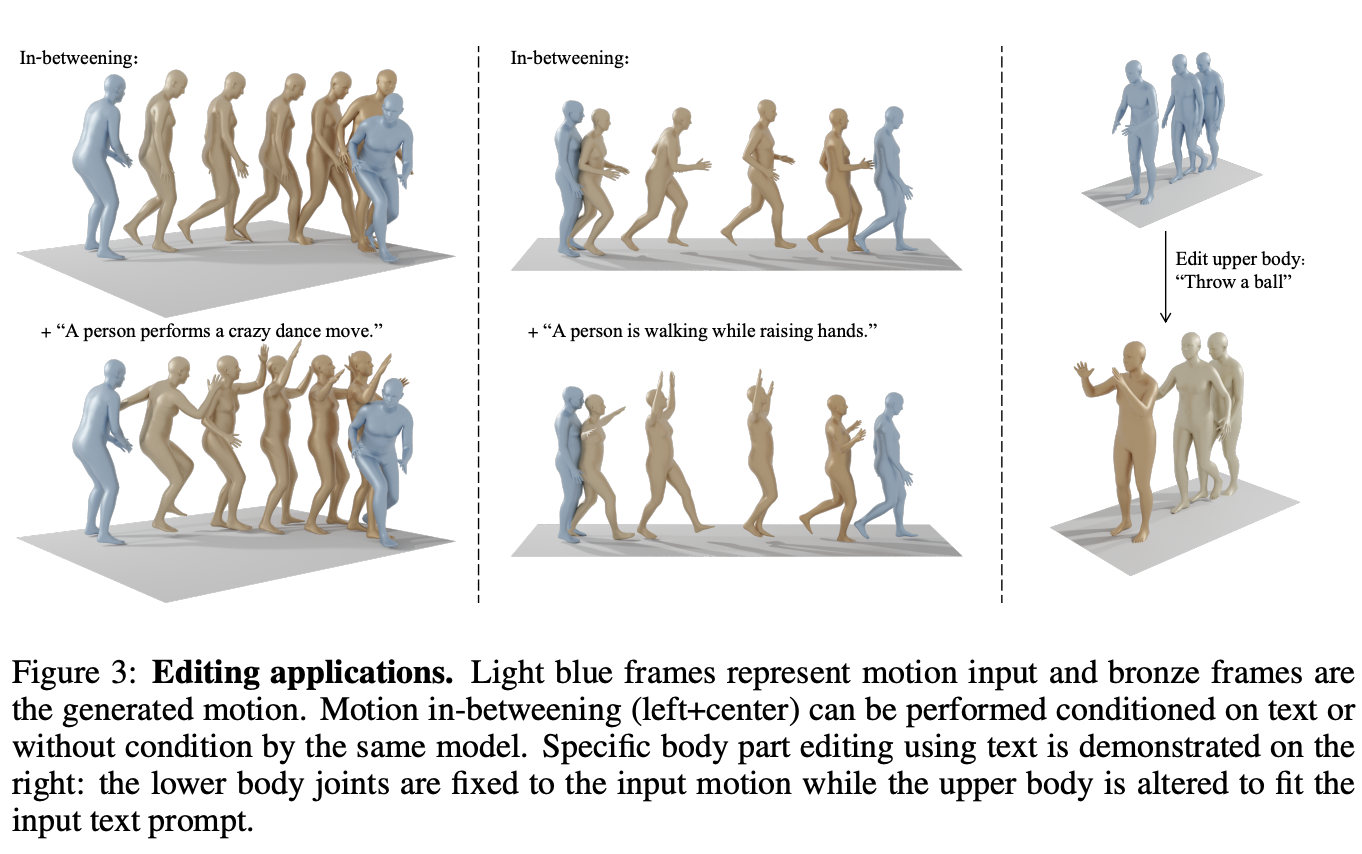
motion data에 diffusion inpainting을 적용하여 temporal domain에서 motion in-betweening을 가능하게 하고, spatial domain에서 body part editing을 가능하게 합니다. editing은 training 없이 sampling 중에만 수행됩니다. motion sequence input의 subset이 주어지면, 모델을 sampling 할 때 각 iteration에서 $x_0$을 motion의 input part로 ovewrite 합니다. 이는 누락된 부분을 완성시키면서 원래 input의 일관성을 유지하도록 생성하게끔 합니다. temporal setting에서 motion sequence의 prefix, suffix frame을 input으로 하고 motion in-betweening 문제를 해겨합니다. 또한 conditionally or unconditionally (by setting $c=∅$)로 설정할 수도 있고, spatial setting에서 동일한 completion technique을 사용하여 body의 일부는 그대로 유지하면서 condition $c$에 따라 합성될 수 있음을 보여주게 됩니다.
아래 그림에서 파란색 프레임은 motion input을 나타내고, 청동색은 generated motion을 나타냅니다. Motion in-betweening (left+center)은 동일한 모델에 의해 text or without condition으로 수행될 수 있습니다. 또한 lower body joints는 고정되고 upper body는 input text prompt에 맞게 변경될 수 있습니다. 아래 그림을 보시면 "Throw a ball" 이라고 text prompt를 주었을 때 하체는 고정되고 상체만 움직이는 것을 볼 수 있습니다. 👏🏻👏🏻👏🏻
Experiments
1. Text-to-motion
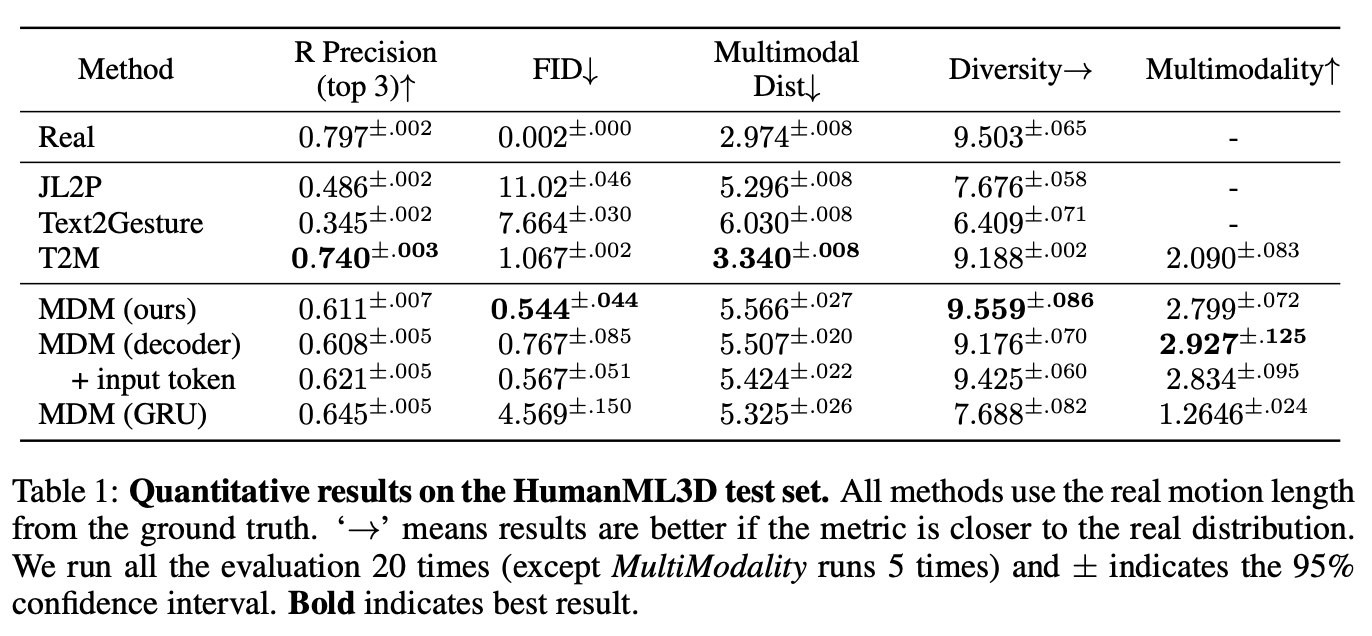
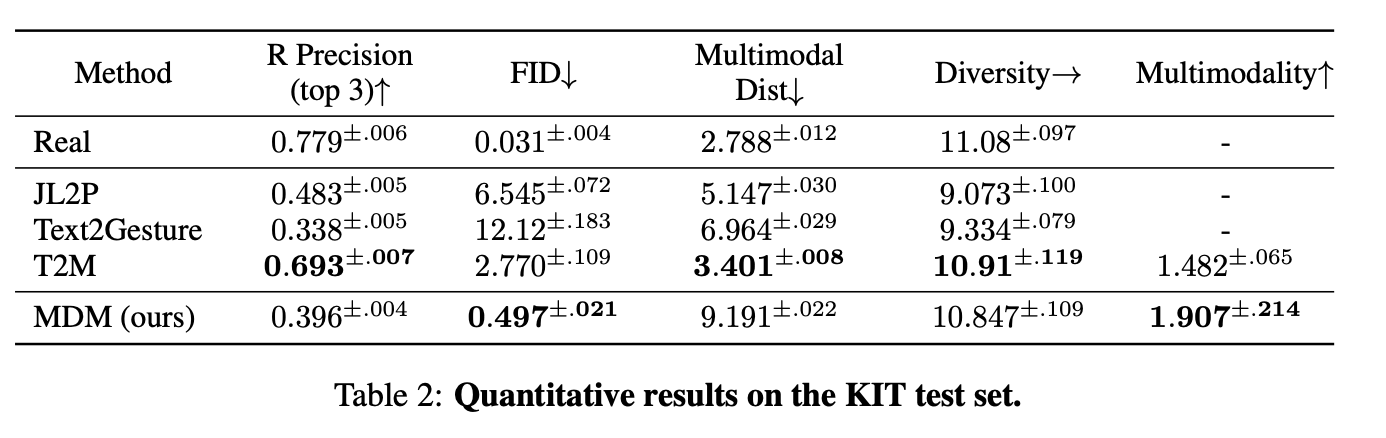
Text-to-motion은 input text prompt가 주어지면 motion을 생성하는 작업입니다. output motion은 textual description과 data distribution의 valid sample의 구현입니다. 또한 각 text prompt에 대해 단일 결과가 아니라 일치하는 motion 의 분포도 평가합니다. Guo 등이 제안한 metric에 대해 KIT(Plappert et al., 2016) 및 HumanML3D(Guo et al., 2022a)라는 두 가지 주요 벤치마크를 사용하여 모델을 평가합니다.
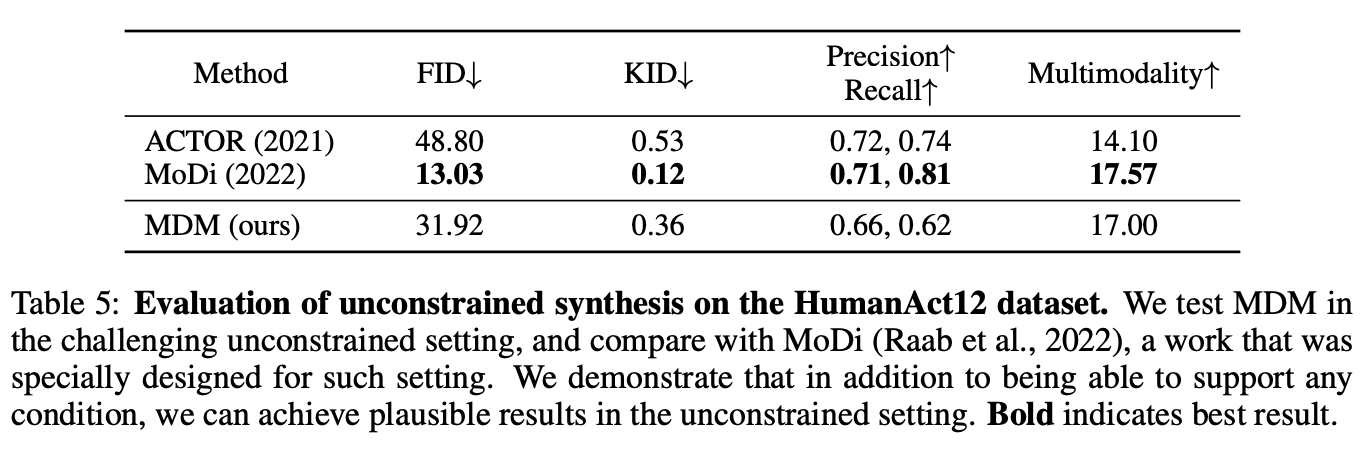
2. Action-to-motion
Action-to-motion은 scalar로 표시되는 input action class가 지정된action을 생성하는 작업입니다. output motion은 input action을 충실하게 애니메이션화해야 하며 동시에 자연스럽고 데이터 세트의 분포를 반영해야 합니다. 이를 평가하기 위해 일반적으로 두 가지 데이터세트 HumanAct12(Guo et al., 2020) 및 UESTC(Ji et al., 2018)가 사용됩니다