[Paper Review] RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose
Paper : https://arxiv.org/pdf/2303.07399v1.pdf
GitHub : https://github.com/open-mmlab/mmpose/tree/1.x/projects/rtmpose
GitHub - open-mmlab/mmpose: OpenMMLab Pose Estimation Toolbox and Benchmark.
OpenMMLab Pose Estimation Toolbox and Benchmark. Contribute to open-mmlab/mmpose development by creating an account on GitHub.
github.com
오늘 리뷰할 논문은 Shanghai AI Lab에서 소개한 "RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose" 입니다. 유명한 MMPose 기반으로 되어있으며, 여러 트릭이 담겨져있는 논문이라 참고할 내용이 많을 것 같아서 읽게 되었습니다. COCO 데이터세트에서 75.8% AP 및 CPU 환경(Intel i7-11700 CPU)에서 90+ FPS를 달성하고, GPU 환경(NVIDIA GTX 1660 Ti GPU)에서는 430+ FPS를 달성한다고 합니다. COCO-WholeBody 데이터에서는 130+ FPS 속도로 67.0% AP를 달성한다고 하네요.
아래는 결과인데요, 굉장히 다양한 동작에 대해서도 robust 한 결과를 볼 수 있습니다. 가까운 이미지에서도 잘 되네요!

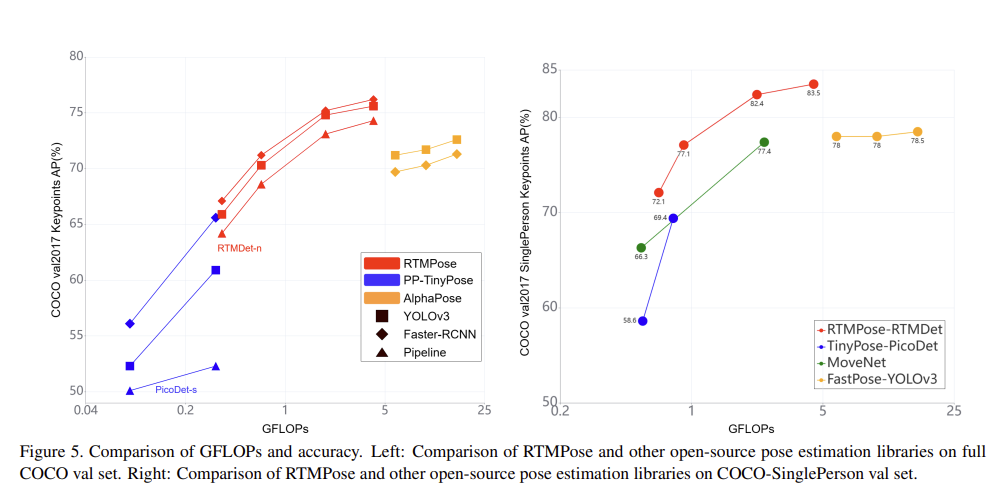
이 논문의 RTMPose의 명칭은 Real-Time Models for Pose estimation 입니다. 이는 top-down paradigm을 따릅니다. 그럼에도 불구하고 inference speed의 bottleneck이 없도록 구현했다고 하네요. backbone은 CSPNeXt으로 되어있고, deployment-friendly 하기 때문에 사용했다고 합니다. 또한 RTMPose는 SimCC 방법을 사용합니다. 이는 heatmap 방식과 비교했을 때 높은 정확도를 달성하고, prediction을 위해 2개의 FC Layer를 사용하는 등 아주 심플한 구조로 이루어져있습니다. 또한 inference 과정을 최적화 하기 위해 skip-frame detection strategy를 사용했다고 합니다. RTMPose 모델은 t, s, m, l 사이즈의 모델로 나뉘어 performance-speed 간의 trade-off 를 갖습니다. 그리고 PyTorch, ONNX Runtime, TensorRT, ncnn 환경에서 모두 테스트 되었다고 합니다. 아래 그림을 보시면 성능이 굉장합니다...
모델 구조는 다음과 같은 방식으로 구성되어있습니다. 모델에는 Conv Layer, FC Layer가 포함되어 있으며, GAU(Gated Attention Unit)을 사용합니다. 이를 이용하여 K keypoint representation을 refine 하는 듯 합니다. 그 다음 Pose에 대해 x, y 축 각각이 구해지면 이를 concat 하는 방식입니다.
SimCC 방법 자체가 간단히 말하면 x, y 좌표를 각 classification 하는 과정이라고 볼 수 있습니다. 굉장히 light한 구조입니다. 그렇다 보니, Classification Task에서 사용하는 Gaussian Label smoothing 방법을 사용할 수 있습니다. 이는 성능 향상을 가져온다고 하네요. 아래 그림을 보시면 느낌이 오실겁니다... 이렇게 visualization 해서 보니까 이해가 쉽네요.

RTMPose 에서는 SimCC 방법에서 cost가 많이 드는 upsampling layer를 제거한 버전을 사용 했다고 합니다. 그 결과 trimmed SimCC가 기존 SimCC 방법 및 heatmap baseline 방법 보다 훨씬 더 낮은 복잡성을 갖는데도 불구하고 여전히 정확도가 높다고 하네요. 그 다음 ResNet-50 backbone 보다 컴팩트한 CSPNext-m backbone으로 교체하여 모델 크기를 더욱 줄이고, 가볍게 만들었습니다.
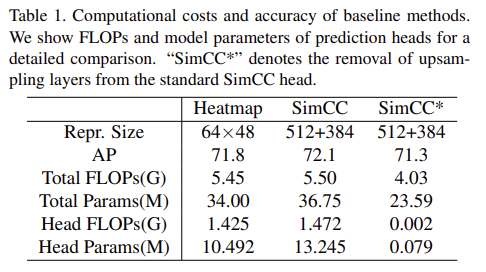
Pre-training은 UDP 방법을 채택하여 pre-training 했다고 합니다. 이는 모델의 성능을 69.7% AP 에서 70.3% AP 까지 끌어올려줬다고 하네요. 무슨 방법인지 나중에 찾아봐야겠습니다. 또한 Exponential Moving Average (EMA)를 사용하여 overfitting을 완화시켰다고 하네요. Flat Cosine Annealing도 사용하여 성능을 올렸구요. normalization layer 및 bias에 대해서도 weight decay를 사용했다고 하네요. 좋은 방법은 다 가져다 쓴 것 같습니다.
또한 strong-then-weak two-stage augmentation 전략을 사용했다고 합니다. 데이터 로더를 180 에폭 정도는 빡세게 주고나서, 30 에폭 정도는 약하게 줬다고 하네요. AID 방법에 따르면 cutout 방법은 모델이 이미지 텍스쳐에 과적합되는 것을 방지하고 pose structure 정보를 학습하도록 권장한다고 합니다. 그리고 30 에폭 정도 데이터 로더의 변형을 약하게 줄때는 모델이 실제 이미지 분포와 더 가깝게 일치하도록 augmentation을 했다고 하네요.
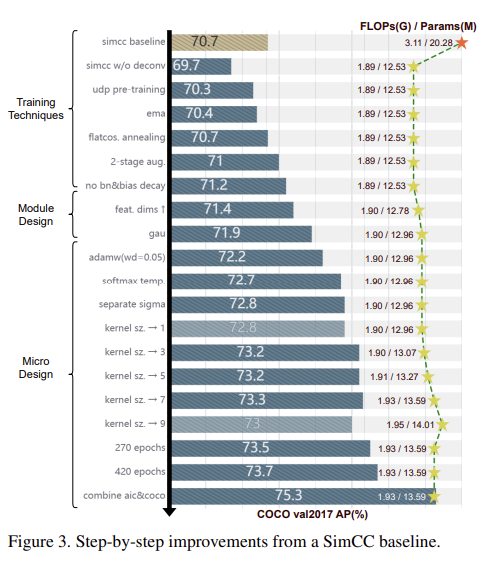
아래 그림은 Step-by-step improvement를 보여주는 그림입니다.
Loss function은 coordinate classification을 위해 SORD 방법에서 제안한 soft label encoding 방법을 따른다고 합니다.
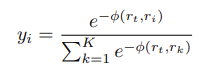
여기서 ϕ(rt,ri)는 rt의 true metric value가 rank에서 얼마나 멀리 떨어져 있는지에 대한 패널티를 부여하는 metric loss function 입니다. 이 과정에서 unnormalized Gaussian distribution을 클래스 간 거리 메트릭(inter-class distance metric)으로 사용한다고 하네요.
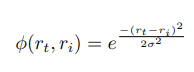
그 다음 model output 과 soft label에 대해 softmax를 적용할 때 temperature를 추가하여 normalized distribution shape을 추가로 조정한다고 합니다. 이 때 τ 값은 0.1을 사용하였을 때 성능이 71.9% 에서 72.7%로 올랐다고 합니다.
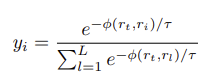
그 외에 Inference 과정에서 BlazePose에서 사용하는 skip-frame detection 방법을 사용하고, OKS-based pose NMS 및 OneEuro filter를 사용한다고 하네요.
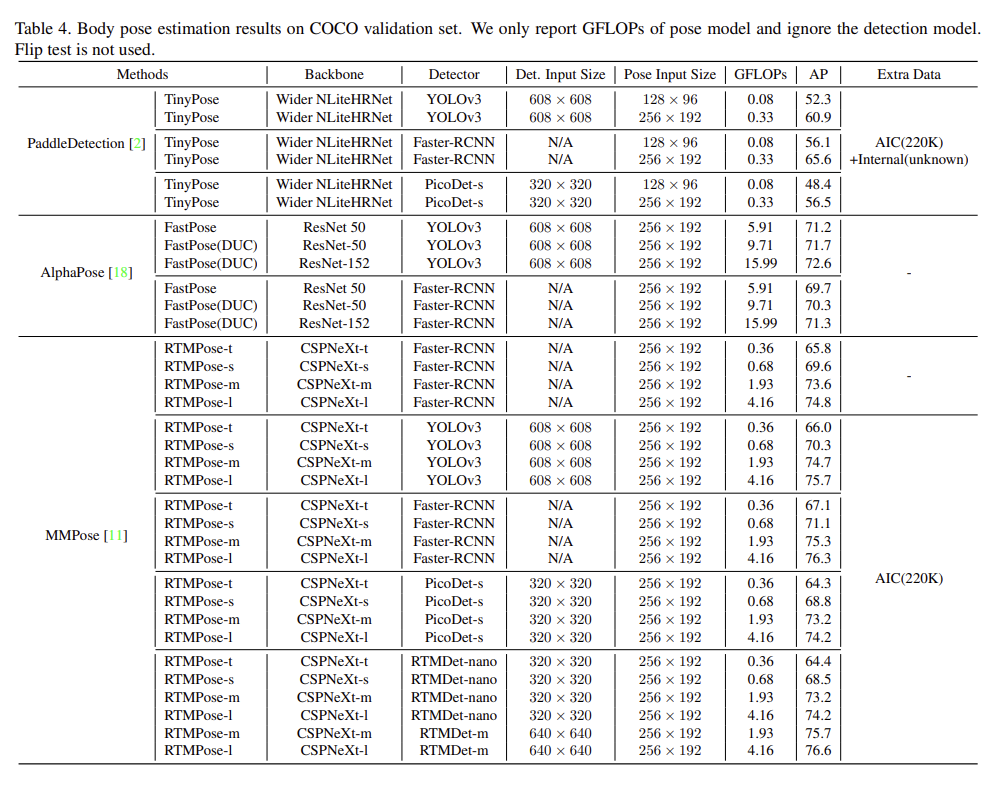
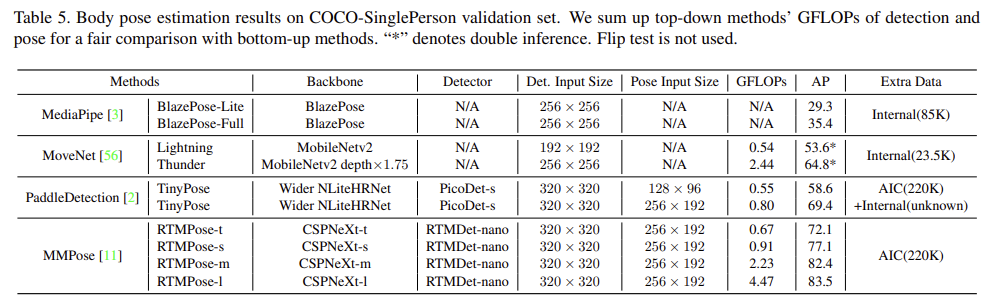
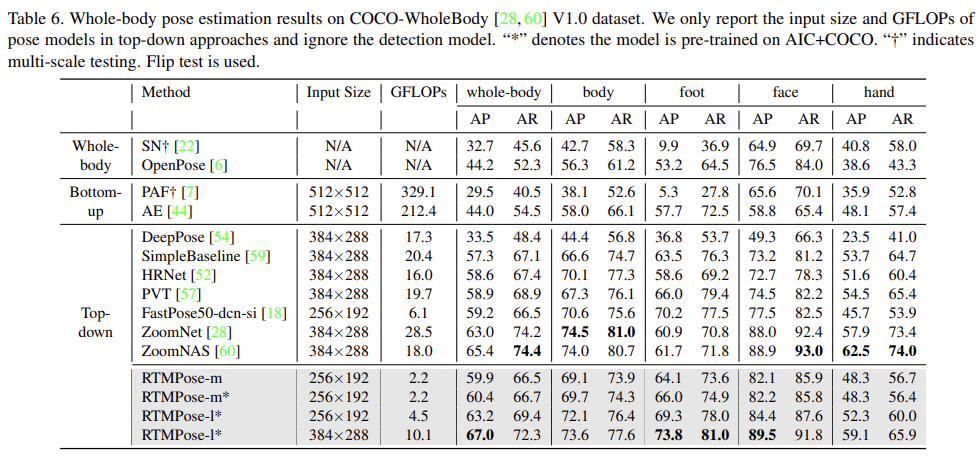
실험결과는 아래와 같습니다.
'AI Research Topic > Human Pose Estimation' 카테고리의 다른 글
꾸준희님의
글이 좋았다면 응원을 보내주세요!