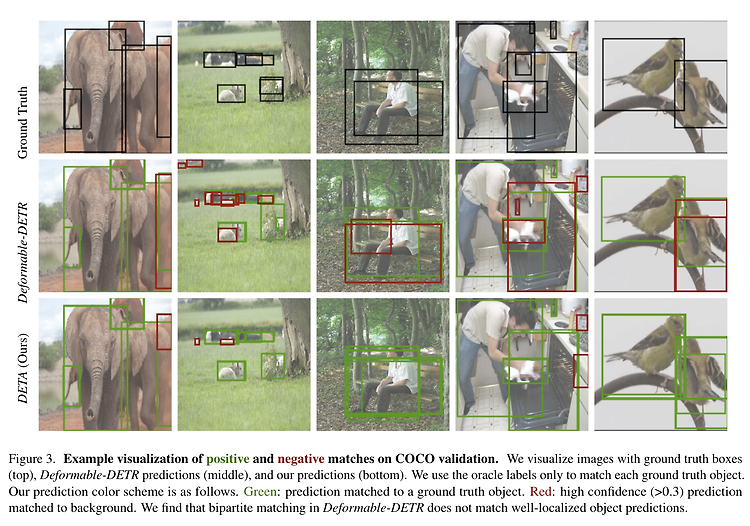
[Deep Learning] Weight Standardization (+ 2D, 3D 구현 방법)
Weight Standardization Paper : arxiv.org/abs/1903.10520 Micro-Batch Training with Batch-Channel Normalization and Weight Standardization Batch Normalization (BN) has become an out-of-box technique to improve deep network training. However, its effectiveness is limited for micro-batch training, i.e., each GPU typically has only 1-2 images for training, which is inevitable for many computer v arxi..
2020.12.20