[Paper Review] ECA-Net : Efficient Channel Attention for Deep Convolutional Neural Networks
Paper : https://arxiv.org/pdf/1910.03151.pdf
Github : https://github.com/BangguWu/ECANet
BangguWu/ECANet
Code for ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks - BangguWu/ECANet
github.com

ECA-Net 은 기존에 알려져있는 SENet 보다 성능이 좋아서 Object Detection, Image Classification, Object Segmentation 분야에서 사용되고 있는 모델이다.
기존 일반적인 CNN 구조에서는 Local Receptive Field 만을 가지고 학습을 하기 때문에 전체적인 정보인 Global Feature 를 고려하지 못한다는 한계점을 가지고 있다. 그래서 아래 사진과 같이 이미지 인식 분야에서는 관심 객체에 대하여 분류를 하거나 검출을 할 때 관심 객체를 어떻게 잘 찾아내느냐(Localization 및 Clssification)가 관건이 된다.
Self-Attention
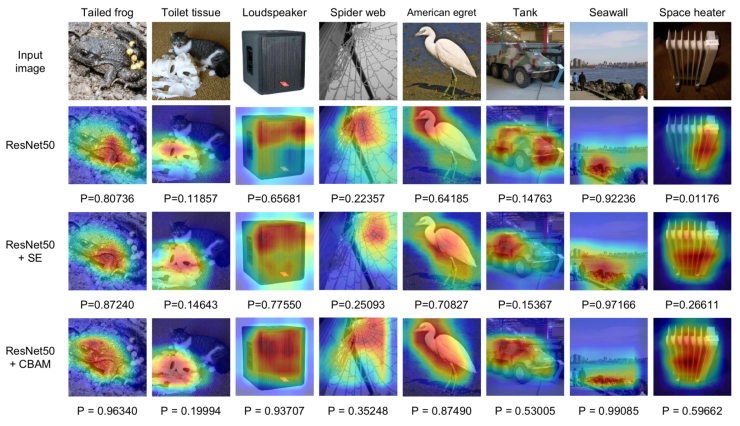
따라서 Attention 이라는 개념이 등장을 하게 되는데, 말 그대로 어떤 특징에 대하여 집중하는 것 이라고 할 수 있다. 주로 이미지에 대한 해석 분야나 이미지에 대한 설명을 자동으로 추출하는 Captioning 분야에서 주로 사용된 개념이다. 그런데 이 개념이 Image Clasification 및 Object Detection 에도 Self-Attention 이 적용이 되기 시작했다.
이전의 Attention 은 Input 부터 Output 까지 일어나는 과정 전체가 Attension 범위였다면, 이후의 Self-Attention 은 네트워크 일부 모듈에서 Attention 이 일어나는 것을 뜻한다.
이렇듯 Image Classification 및 Object Detection 분야에서 입력 영상에 따라 집중해서 봐야할 부분이 다르기 때문에 Attention 개념은 중요하다. ECANet 도 이러한 Attention 기법을 적용한 네트워크로서 아주 적은 오버헤드만으로 유의미한 성능 향상을 이끌어 낸다고 한다. 이 네트워크 말고도 대표적인 Self-Attention 개념으로 SENet, BAM 및 CBAM 이라는 모듈이 있다.
BAM 및 CBAM 은 이전 포스팅 참조
2020/10/10 - [AI Research Topic/Deep Learning] - [Deep Learning] BAM 및 CBAM 설명
[Deep Learning] BAM 및 CBAM 설명
BAM 및 CBAM 개요 Self-Attention 의 대표적인 네트워크인 BAM(Bottleneck Attention Module) 및 CBAM(Convolutional-BAM) 모듈을 잠깐 설명하도록 하겠다. 일단 두 모듈 모두 3D Attention Map 을 Channel-wise /..
eehoeskrap.tistory.com
SENet (Squeeze and Excitation Networks)
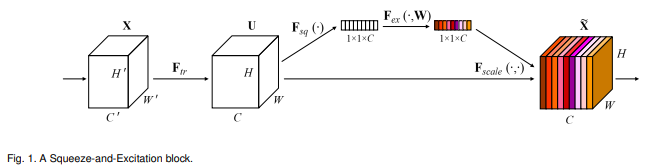
ECANet 논문에서는 SENet 을 분석함으로써 SENet 보다 개선된 점을 설명한다. SENet 은 기존 네트워크를 거진 feature map 들을 feature recalibration 한다. 이전 CNN 구조를 보면 channel 의 feature 를 고려하지 못하고 있다는 한계점이 있는데, 이런 global feature 를 고려하면서도 중요한 정보를 놓치지 않도록 나온 것이 SENet 이다. 이는 크게 squeeze 단계와 excitation 단계로 나뉘게 된다.
간단히 말하자면 Squeeze 단계 에서는 각 feature map 에 대한 전체 정보를 요약하게 되고, Excitation 단계에서는 각 feature map 의 중요도를 scale 해주는 단계로 이루어진다.

Squeeze
- Global Information Embedding 을 통해 각 채널들의 중요한 정보만을 추출
- Global Average Pooling 을 사용하여 1 x 1 x C 의 feature map 으로 압축
Excitation
- Adaptive Recalibration 즉, Squeeze 연산을 통해 압축된 정보들의 채널 간 의존성을 계산
- 두 번의 Fully-connected Layer 와 비선형 활성화 함수를 통해 중요한 특징 부분을 강조
- 이 과정에서 Dimension Reduction 발생
Squeeze 단계에서는 말 그대로 짜내는 연산을 하게 되는데 각 채널의 중요한 정보만 추출해서 가져가겠다는 의미이다. Local Receptive Field 가 매우 작은 네트워크 하위 부분에서는 중요한 정보를 추출하는 것이 매우 중요하다. 논문에서는 가장 중요한 정보를 추출하는 가장 일반적인 방법으로 GAP(Global Average Pooling)을 사용한다. 이를 사용하게 되면 global spatial information 을 channel descriptor 로 압축 시킬 수 있다고 한다. 논문의 저자들은 간단한 방식으로 정볼르 압축하기 위해 GAP 를 사용했다고 하지만 다른 방법도 사용 할 수 있다고 한다. 이렇게 Squeeze 단계에서는 중요한 정보를 압축하여 전체 정보를 요약하게 된다.
Excitation 단계에서는 앞서 Squeeze 단계에서 중요한 정보를 압축했다면, Re-calibration 단계를 거치게 된다. 이 과정에서 채널 간 의존성을 계산하게 되는데 논문에서는 fully connected layer 와 비선형 함수를 조절하는 것으로 이를 계산한다고 한다. fully connected layer 는 2개로 이루어져 있고, 이 과정에서 연산량을 줄이기 위해 dimension reduction 이 일어나게 된다.
ECA-Net : Efficient Channel Attention for Deep Convolutional Neural Networks
- 기존 Self-attention 기반 CNN 모델의 문제점
- Channel Attention 은 CNN의 성능을 높이는데 크게 기여하였으나, 모델 복잡도가 높음
- SENet 모델 분석
- Dimension Reduction 을 피하는 것이 channel attention 을 학습하는데 중요
- Cross-channel interation 이 모델의 복잡도를 매우 낮춤과 동시에 성능을 유지할 수 있다는 것을 발견
- ECANet
- 성능과 복잡도 사이의 trad-off 를 극복
- 적은 수의 parameters 만으로도 뚜렷한 성능 향상 효과
- 효율적인 1D Convolution 을 통해 Dimension Reduction 없이 Local Cross-channel Interaction 할 수 있는 방법을 제안
ECANet 은 앞서 설명한 SENet 의 문제점을 분석하여 이를 해결하고자 제안한 방법인데, SENet 에서 연산량을 줄이기 위한 fully connected layer 에서 dimension reduction 이 일어나는데, 이것이 오히려 channel 과 weight 간의 직접적인 연관성을 파괴 한다고 말하고 있다. 따라서 ECANet 에서는 dimension reduction 이 일어나지 않게 하였고, 그 대신 model complexity 를 낮추기 위한 새로운 방법을 제안하고 있다.
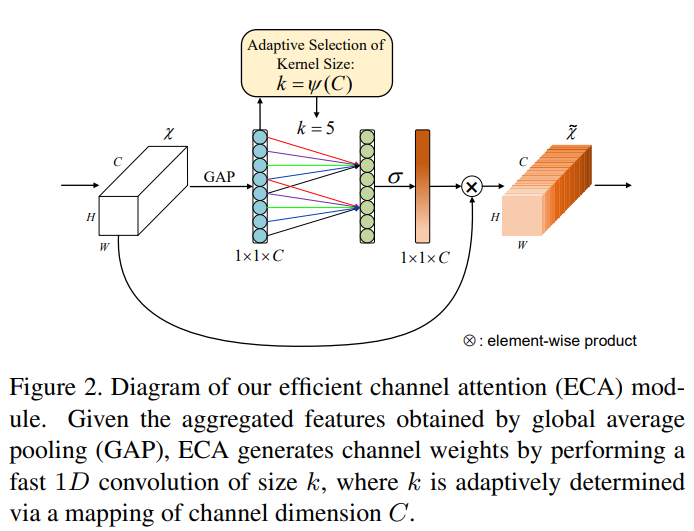
ECANet 과 SENet 을 비교한 그림은 아래와 같다.

위와 같이 global average pooling(GAP) 을 사용하여 추출된 특징이 주어지면 SE block 은 두 개의 FC layer 를 사용하여 가중치를 계산한다. 이와는 달리 ECA module 은 커널 k 사이즈 만큼의 1D Convolution 을 사용하여 채널 가중치를 생성한다. 이 연산은 1D conv 이기 때문에 매우 빠르다는 장점이 있으며, 여기서 k 는 channel dimension C의 함수를 통해 adaptive 하게 결정된다.
따라서 이 논문의 contribution 은 정리하자면 아래와 같다.
- GAP 를 사용하여 특징을 추출 한 후, SENet 의 2개의 FC layer 대신 커널 K 사이즈 만큼의 1D Convolution 을 사용하여 효율적으로 Dimensionality Reduction 없이 Channel Attention 을 수행함으로써 채널 가중치를 계산
- SENet 에서 FC Layer 로 발생하는 dimension reduction 없이 channel 과 weight 간의 직접적인 연관성을 연결
- 1D Convolution 만으로 주변 local 영역만을 고려하는 커널을 사용하여 model complexity 를 낮추었음
- ECA module 은 기존 SE block 을 대체 가능, 즉 Inception 모듈이나 ResNet 모듈에 사용 가능
Coverage of Local Cross-Channel Interaction
ECA Module 은 local cross-channel interaction 을 적절하게 설정하는 것을 목표로 하기 때문에 Interaction 의 coverage 를 잘 결정하는 것이 필요하다. 그래서 결국 kernel size 인 k 값을 적절하게 사용하는 것이 중요하다. k 라는 값은 쉽게 생각했을 때 특징을 얼만큼 볼거냐 라는 것을 뜻하는데, k 값을 통해 결정되는 interaction 이 포함되는 범위는 channel 의 수인 C 와 비례하는 것이 일반적이다.
이 때 k와 C 사이의 mapping function 을 아래와 같이 나타낼 수 있다.

그런데 이는 간단한 선형 함수(Linear Function) 인데, 이는 너무 간단하여 interaction 의 coverage 를 정하는데 한정적이라고 할 수 있다. 따라서 C를 일반적으로 2의 배수로 설정하는 것에 착안하여 아래와 같이 non-linear function 으로 설정할 수 있다.
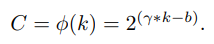
이 때 C에 대한 함수로 바꾸면 아래 식과 같이 나타 낼 수 있다.

기존 방법들과 ECA 를 세가지 측면에서 비교한 표는 다음과 같다.
- Dimension Reduction
- Cross-channel Interaction
- Lightweight

아래 표를 보면 ECA-Net 이 parameters 수 대비 성능 향상 폭이 매우 큰 것을 확인 할 수 있다.
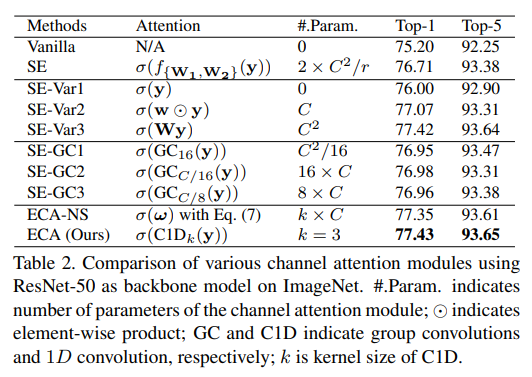
논문에 나와있는 pytorch 구현은 아래와 같다.

실제 github 에 구현되어있는 코드는 아래와 같다.
import torch
from torch import nn
from torch.nn.parameter import Parameter
class eca_layer(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x: input features with shape [b, c, h, w]
b, c, h, w = x.size()
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
Experiments

위 표는 network parameter 관점에서 ImageNet 을 이용하여 attention 방법들을 비교한 표이다. 확실히 SENet 보다 파라미터 수가 3.40M -> 3.34M 으로 작으면서도 성능도 72.42 -> 72.56 으로 높다는 것을 확인 할 수 있다. FPS 도 당연히 빠르다. 2개의 FC Layer 보다 1D Convolution 이 효율적이라는 것을 증명해준다.
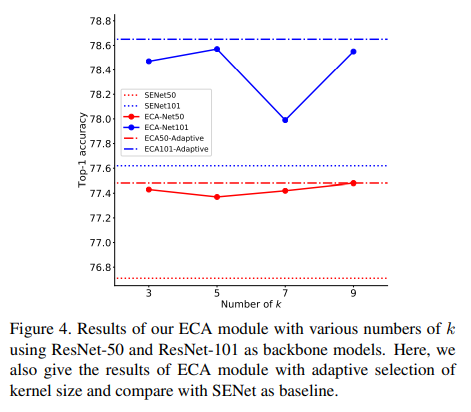
위 표에서는 kernel k 의 효과에 대한 실험인데, ResNet 50 이나 101 을 Backbone 으로 사용했을 때 각 k=9 및 k=5 에서 최상의 결과를 얻는다고 한다. 그래프를 보면 ResNet-101 에서 정확도 변동 폭이 ResNet-50 보다 더 큰 결과를 확인할 수 있는데, 이는 깊은 네트워크가 고정된 커널 크기에 더 민감하기 때문이라고 설명하고 있다. 이 부분에 있어서는 Trade-off 가 존재하므로 kernel k 값을 잘 설정해주어야 할 듯 싶다.
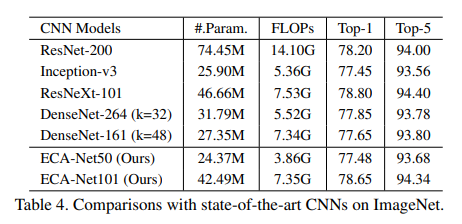
아래 표4 는 ImageNet 데이터 세트를 사용하여 Image Classification 분야에서 비교한 결과이다. 다른 결과들에 비해 Image Classification 분야에서는 SOTA 성능이 아니다. 하지만 파라미터가 비교적 적은 것에 비해 정확도가 높은 것은 눈여겨 볼 만 하다.
아래 표 5는 COCO val2017 데이터 세트를 사용하여 Object Detection 분야에서 비교 한 결과이다.

아래 표6 은 COCO val2017 데이터 세트를 사용하여 Instance Segmentation 분야에서 비교한 결과이다.

ECA-Net 의 주요 내용을 정리해보자면 아래와 같다.
- 모델 복잡성이 낮은 Deep CNN에 대해 효율적인 Channel Attention 을 학습하는 모델
- 채널 차원의 비선형 매핑(non-linear)을 통해 커널 크기를 adaptive 하도록 kernel k 를 결정 하여 효율적인 1D Convolution 을 통해 Channel Attention 모듈을 생성
- Extremely lightweight plug-and-play block
- Object Detection, Instance Segmentation 작업에서 우수한 성능을 보여줌
참고자료 1 : cdm98.tistory.com/53
[Review] ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks (하루논문 P07)
하루에 논문 한편씩, 핵심만 읽고 요약하기 : Paper 07 Paper Link : Link (CVPR2020) Official Code : https://github.com/BangguWu/ECANet 1. Abstract 최근에 channel attention은 CNN의 성능을 높이는데 크..
cdm98.tistory.com
참고자료 2 : arxiv.org/pdf/1709.01507.pdf
'AI Research Topic > Computer Vision Basics' 카테고리의 다른 글
| [Image Processing] 구조적 요소(Structuring Element) 및 팽창, 침식, 닫힘, 열림 연산 (0) | 2020.11.14 |
|---|---|
| [Paper Review] DCNv2 : Deformable Convolutional Networks v2 (3) | 2020.11.01 |
| [Paper Review] BAM(Bottleneck Attention Module), CBAM(Convolutional-BAM) (0) | 2020.10.10 |
| [Dataset] 이미지 인식에 유용한 데이터셋 정리 (2020.09.14) (0) | 2020.09.14 |
| [Dataset] MCL DATASETFOR VIDEO SALIENCY DETECTION (0) | 2020.09.11 |