[Paper Review] CBAM : Convolutional Block Attention Module
CBAM 논문을 살펴보았다. 저자가 한국인이라서 그런지 몰라도 논문 이름부터 시작해서 논문이 잘 읽히는 편이었고, 이미 저자가 논문을 정리해 놓은 자료도 있어서 이해하기 수월했다. CBAM 논문은 BAM(Bottleneck Attention Module) 에 이어 나온 논문이다. 두 논문 모두 CNN의 성능 향상을 위한 Self-attention Module 을 제안하고 있다. 여기서는 CBAM 의 내용을 주로 다루기로 한다.
CNN 계열에서 Attention 개념은 주로 Image Captuioning 처럼 multi-modal 간의 관계를 이용한 feature selection 에서 많이 사용되었다고 한다. Attention 이라는 것 자체가 어떠한 특성에 대하여 "집중"하는 것인데, Image Classification 이나 Detection 문제에서 입력 영상에 따라 중요한 부분에 집중하는 것이 필요하다.
기존의 신경망 설계 측면에서는 depth / width / height 등의 관점에서 연구가 이루어졌지만, 최근 들어 Residual Attention Networks, Squeeze-and-Excitation, Non-local Neural Network 등에서 Attention 방법이 주목받고 있다. 이와 같이 CBAM 에서 제안한 Attention Module 은 아주 적은 오버헤드로도 매우 유의미한 성능 향상을 이끌어낸다고 한다.
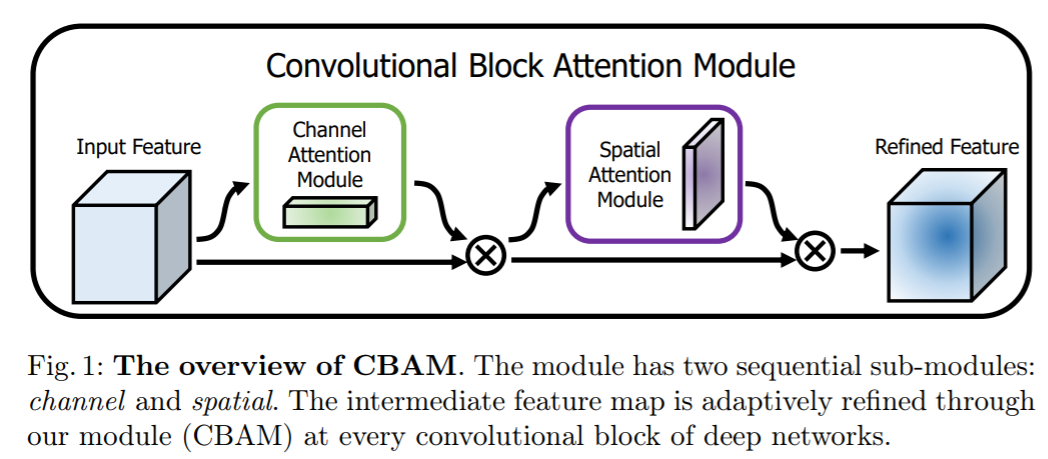
BAM 과 CBAM 모두 conv feature 를 입력으로 받고, 그에 대한 attention 을 계산한다. Sigmoid 로 normalize 된 attention map 은 conv feature 에 element-wise 곱 해진다. Sigmoid 대신 Softmax 같은 방식이 있겠지만 가장 중요한 특징을 찾는 것이 목적이 아니기 때문에 softmax 대신 sigmoid 를 사용한다. 아래 식에서 F 는 conv feature, M(F)는 생성된 attention map 을 나타낸다.

Residual Attension Networks 에서 encoder-decoder 방식을 이용해서 3D attention map 을 생성하는데 이는 연산량이 매우 많다는 단점을 가진다고 한다. 그래서 이 논문에서는 attention 의 효과를 입증하기 위해 적은 연산량으로도 큰 성능 향상을 이끌어내는 것이 중요하기 때문에 BAM 과 CBAM 은 3d attention map 을 channel-wise / spatial-wise 로 분해하여 계산하였다. 이는 단순한 pooling conv 로 이루어져 있으며, self-attention 을 모듈화 하여 어떠한 CNN 에 쉽게 끼워 넣을 수 있게 하였다고 한다. 그리고 두 모듈 다 기존 네트워크와 함께 end-to-end 학습이 가능하다고 한다.
BAM (Bottleneck Attention Module)

BAM 을 간단히 언급하자면, 여기서의 bottleneck 이라 함은 spatial pooling 이 이루어지는 부분인데, 이러한 과정은 feature map 의 spatial resolution 이 작아지게 된다. 이러한 구간에서 정보량이 줄기 전에 BAM 을 추가하여 attention 으로 중요한 부분의 값을 키우고, 덜 중요한 부분의 값을 줄이도록 하는 것이 BAM 의 핵심 특징이다. BAM 은 3d conv feature 를 입력으로 받고 attention 으로 refine 된 conv feature 를 출력한다. channel 축과 saptial 축의 attention 을 나누어 계산하고, 각 output 값을 더하고 sigmoid 를 통해서 입력과 같은 사이즈의 3d attention map 을 생성하게 된다. 입력 시 conv feature 와 attention map 을 곱해준 값을 기존 입력에 더해주는 형태로 진행된다. channel 축은 global average pooling 을 통해 각 채널의 global context 를 모아준다. 그리고 2-layer MLP(Multi-Layer Perceptron) 를 통과하여 입력 채널과 같은 사이즈를 출력하게 된다. spatial 축은 채널이 갖는 의미를 유지하기 위해서 conv 만으로 최종 2d attention 을 계산하게 된다. BAM 에서는 2개의 하이퍼파라미터가 있는데 채널의 압축 정도(r)와 공간 attention에서의 dilation value (d) 가 있다. 공간 attension 을 계산할 때는 일반적인 3x3 conv 보다 dilated(atrous) conv 가 더 넓은 context 모은다고 한다.
CBAM (Convolutional Block Attention Module)
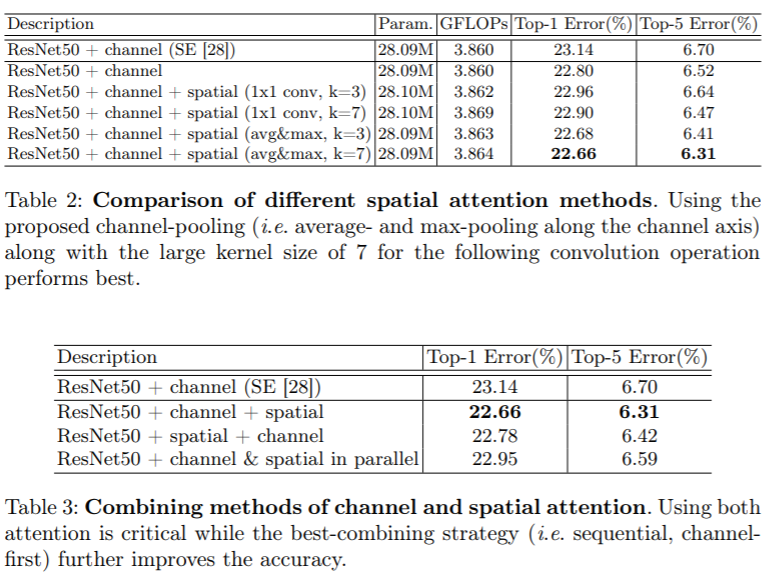
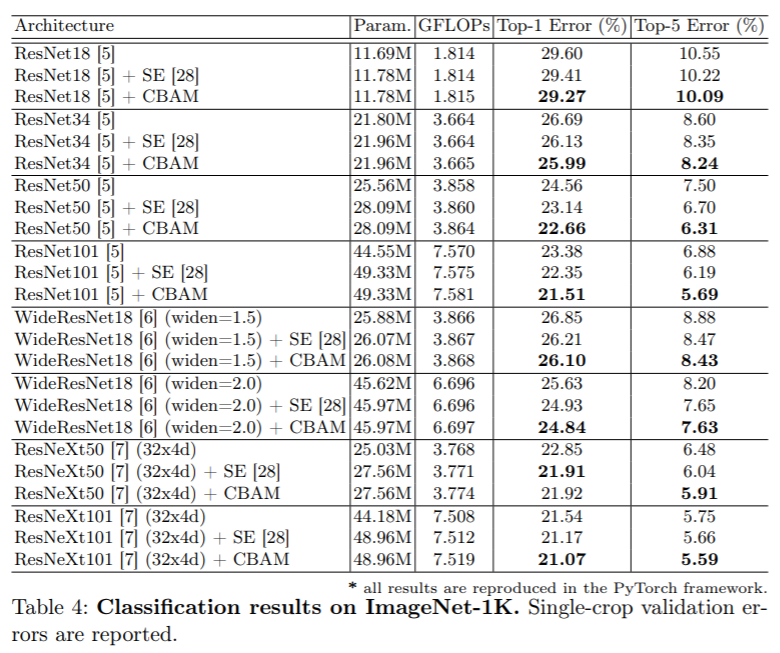
CBAM 은 BAM 의 후속 연구로서 기존 BAM 은 channel 과 spatial 을 하나의 3차원으로 더해서 구현하였지만, CBAM 은 순차적으로, channel 을 적용한 다음 spatial 을 적용하는 것이 더 나은 성능을 보인다고 한다.
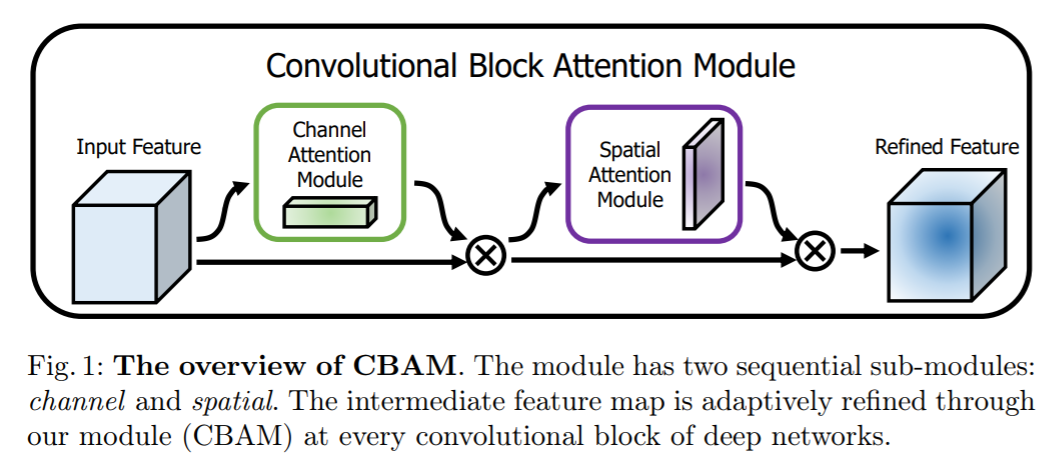
Channel Attention Module / Spatial Attention Module
channel attension 의 경우 기존 BAM 은 average pooling 을 사용하였지만, CBAM 은 average pooling, max pooling 두 가지를 결합하여 사용하였다. 두 가지 pooled feature 는 같은 의미를 공유하는 값이기 때문에 하나의 공유된 MLP 를 사용할 수 있으며, 파라미터 양을 줄일 수 있다. spatial attention 의 경우 단 하나의 conv 로 spatial attention 을 계산한다. spatial attention 이 channel attention 과 다른 점은 정보가 어디에 있는지를 중점으로 둔다는 것이다.


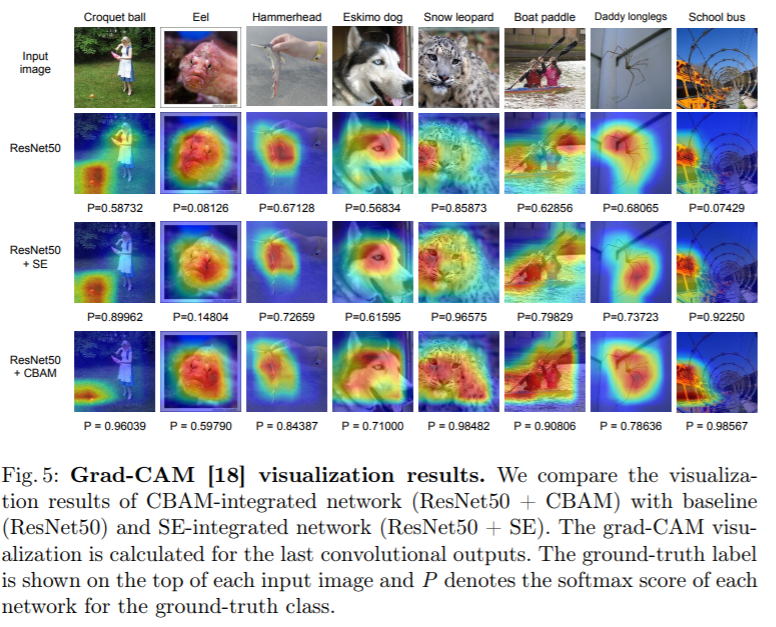
참고자료 1 : https://blog.lunit.io/2018/08/30/bam-and-cbam-self-attention-modules-for-cnn/
BAM and CBAM: self-attention modules for CNN
Intro 이번 글에서는 self-attention에 대하여 필자가 연구한 다음 두 논문을 다뤄보고자 합니다. Jongchan Park*, Sanghyun Woo*, Joon-Young Lee, and In So Kweon: “BAM: Bottleneck Attention Module” , in BMVC 2018 (Oral) Jo…
blog.lunit.io
참고자료 2 : https://norman3.github.io/papers/docs/bam_and_cbam.html
CBAM: Convolutional Block Attention Module
최종 출력은 \(R^{C \times H \times W}\) 이다.
norman3.github.io
참고자료 3 : https://arxiv.org/abs/1807.06521
CBAM: Convolutional Block Attention Module
We propose Convolutional Block Attention Module (CBAM), a simple yet effective attention module for feed-forward convolutional neural networks. Given an intermediate feature map, our module sequentially infers attention maps along two separate dimensions,
arxiv.org
'AI Research Topic > Deep Learning' 카테고리의 다른 글
| [Paper Review] BAM(Bottleneck Attention Module), CBAM(Convolutional-BAM) (0) | 2020.10.10 |
|---|---|
| [Deep Learning] 딥러닝에서 학습 시 학습률과 배치 크기 문제 (3) | 2020.06.22 |
| [Deep Learning] Activation Function : Swish vs Mish (1) | 2020.06.07 |
| [Deep Learning] MediaPipe (0) | 2020.06.03 |
| [Deep Learning] 딥러닝에서 사용되는 다양한 Convolution 기법들 (4) | 2020.05.18 |