[Paper Review] BAM(Bottleneck Attention Module), CBAM(Convolutional-BAM)
BAM 및 CBAM 개요
Self-Attention 의 대표적인 네트워크인 BAM(Bottleneck Attention Module) 및 CBAM(Convolutional-BAM) 모듈을 잠깐 설명하도록 하겠다. 일단 두 모듈 모두 3D Attention Map 을 Channel-wise / Spatial-wise 로 분해하여 계산한다. 연산 및 파라미터 오버헤드는 1~2% 수준으로 매우 미미한 편이라고 한다. 이 두 모듈 모두 아주 단순한 pooling 및 convolution 으로 이루어져있다.
BAM (Bottleneck Attention Module)
위와 같이 BAM 은 각 네트워크의 bottleneck 에 위치하게 된다. 여기서의 bottleneck 은 spatial pooling 이 이루어지는 부분이다. spatial pooling 은 CNN의 abstraction 과정에서 필수적인 부분이며, feature map 의 spatial resolution 이 작아지게 된다. 이러한 구간에서 정보량이 줄기 전에 BAM을 추가하여 attention 으로 중요한 부분의 값을 키우고, 덜 중요한 부분의 값은 줄이도록 하는 기법이다.
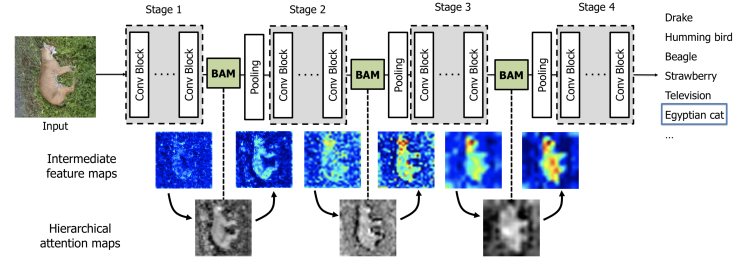
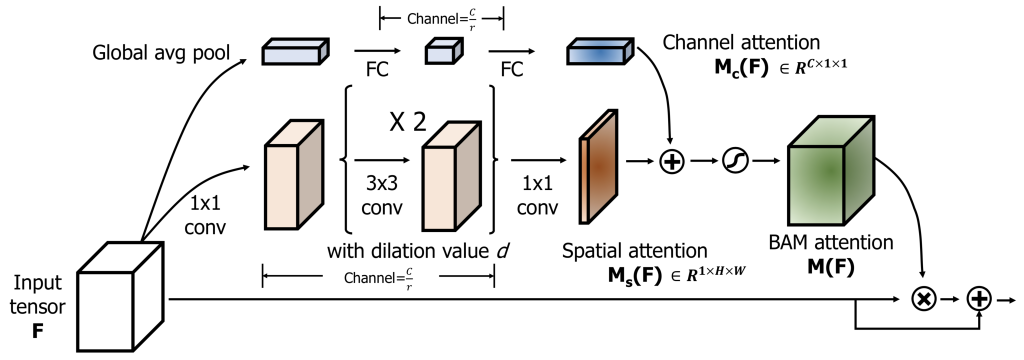
BAM은 3D conv feature 를 입력으로 받고 attention 으로 refine 된 conv feature 를 출력한다. 이는 channel 축과 spatial 축의 attention 을 나눠 계산하고 각 output 값을 더하고 sigmoid 를 통해서 입력과 같은 사이즈의 3D attention map 을 생성하게 된다. channel 축은 global aberage pooling 을 통해서 각 채널의 global context 를 모아준다. spatial 축은 채널이 갖는 의미를 유지하기 위해 conv 만으로 최종 2d attention 을 계산하게 된다.
여기서 2가지 hyper parameter 가 있는데 채널 압축 정도(r) 와 공간 attention 에 대한 dilation value(d) 가 있다. 채널 압축 정도는 연산량을 줄이기 위한 channel 을 줄이는 값이고, 최적의 값은 16 이라고 한다. 그리고 공간 attention 을 계산할 때 중요한 것은 global 한 attention 을 위해 context 정보를 모으는 것 인데, 일반적인 3x3 conv 보다 dilated(atrous) conv 가 더 넓은 context 를 모은다고 알려져 있다고 한다. 그래서 d 값이 너무 작으면 context 를 적게 볼 것 이고, 너무 크면 지역적 정보를 못볼 수 있기 때문에 최적의 값은 4라는 것을 실험을 통해 찾았다고 한다.
CBAM (Convolutional-BAM)
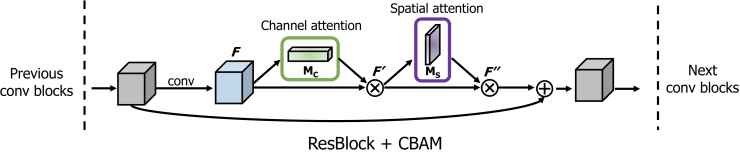
CBAM은 BAM 의 후속 연구로, 더욱 향상된 성능을 보여준다. 기존 BAM 은 channel 및 spatial 을 하나의 3D 로 더해서 구현하였지만, CBAM 은 순차적으로 channel attention 을 먼저 적용하고 spatial attention 을 후에 적용하는 것이 더 나은 성능을 보인다고 설명하고 있다. channel attention 의 경우 기존 BAM 은 average pooling 을 사용하였지만, CBAM은 average pooling, max pooling 두 가지를 결합하여 사용하였다. spatial attention 또한 대칭적으로 구성되며, 단 하나의 conv 으로 spatial attention 을 계산한다.
CBAM 에 대한 자세한 설명은 아래 포스팅 참조
이렇듯 BAM , CBAM 네트워크 구조는 단순한 pooling 및 convolution 으로 이루어져있으며, self-attention 을 모듈화 하여 어떠한 CNN에도 쉽게 넣을 수 있도록 하였다. 두 모듈 다 기존 네트워크와 함께 end-to-end training 이 가능하게 하였다.
참고자료 1 : blog.lunit.io/2018/08/30/bam-and-cbam-self-attention-modules-for-cnn/
BAM and CBAM: self-attention modules for CNN
Intro 이번 글에서는 self-attention에 대하여 필자가 연구한 다음 두 논문을 다뤄보고자 합니다. Jongchan Park*, Sanghyun Woo*, Joon-Young Lee, and In So Kweon: “BAM: Bottleneck Attention Module” , in BMVC 2018 (Oral) Jo…
blog.lunit.io
'AI Research Topic > Computer Vision Basics' 카테고리의 다른 글
| [Paper Review] DCNv2 : Deformable Convolutional Networks v2 (3) | 2020.11.01 |
|---|---|
| [Paper Review] ECA-Net : Efficient Channel Attention for Deep Convolutional Neural Networks (0) | 2020.10.10 |
| [Dataset] 이미지 인식에 유용한 데이터셋 정리 (2020.09.14) (0) | 2020.09.14 |
| [Dataset] MCL DATASETFOR VIDEO SALIENCY DETECTION (0) | 2020.09.11 |
| [Deep Learning] 딥러닝에서 학습 시 학습률과 배치 크기 문제 (3) | 2020.06.22 |