[Object Detction] 3D Object Detection, Google Objectron
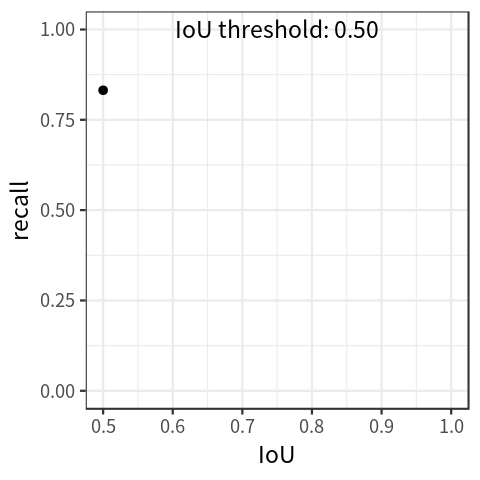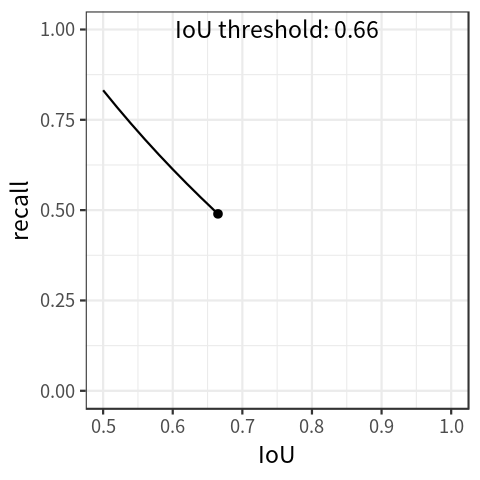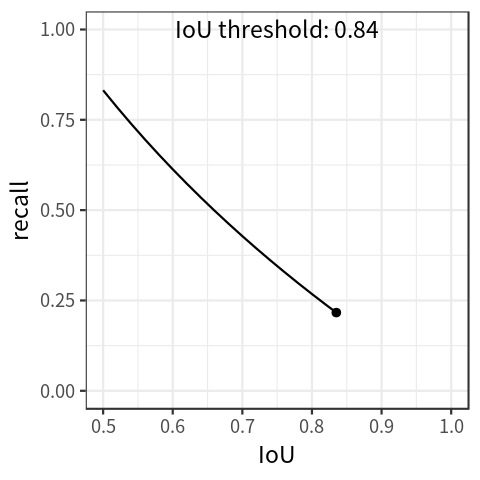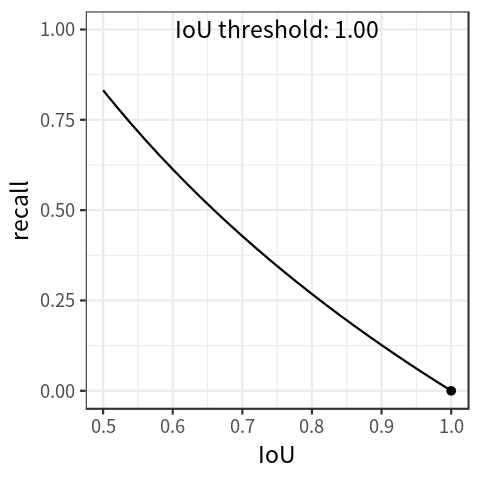
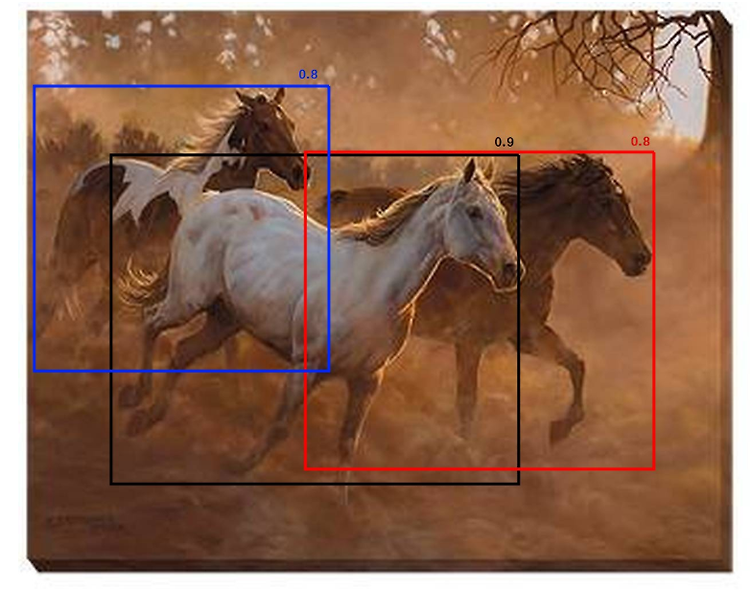
Object Detection 분야는 대부분 2차원 객체 탐지만을 다루고 있다. 2차원 객체를 탐지하는 것은 2차원 바운딩 박스만 있지만, 3차원 객체 탐지로 범위를 확장한다면, 물체의 크기 및 위치, 방향 등을 알 수 있으므로 자율 주행 및 이미지 검색, 증강 현실에서 다양한 분야에 응용 할 수 있다. 가령, 2D Human Pose Estimation 분야에서 3차원 정보가 아주 조금 필요한 도메인이라면, 3D Human Pose Estimation 까지 연구의 범위를 확장 안하고도 문제를 해결 할 수 있지 않을까 라는 생각을 했다. 즉, 사람에 대한 2차원 바운딩 박스 정보를 3차원으로 추출 할 수 있다면, 꽤 vanilla 적인 접근으로 여러가지 문제를 해결할 수 있지 않을까 ㅎㅎ 심지어 이건 모..
2020.05.27