[SQLD] 제22회 SQL 개발자 자격시험 합격후기 (SQLD, 공부법)
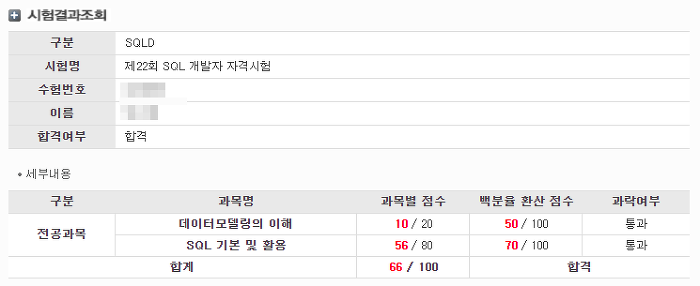
간단히 말하면 SQLD는 SQL 개발자 자격 시험이고, 접수비는 5만원, 1년에 시험 4번(3, 6, 9, 12월 시행), 필기 1번으로 끝, 합격자 발표 시험 보고 한달 후 발표, 책도 5만원, 자격증 발급 따로 없음(2016년도부터 온라인 자격증으로 대체), 정보처리기사보다 어려운 시험, 전공자라면 짧게는 2주, 넉잡아 4주 공부하길, 시험은 서울지역의 경우 동국대에서 봄, 수원사는데도 동국대가 제일 가까웠던 듯, 객관식 1과목 10문제 2과목 40문제, 그 중 주관식 8문제, 총 50문제 객관식+주관식 형식으로 출제된다. SQLD 시험 후기SQLD 시험을 본지도 어언 한달이 지났다. 개강하고서 9월 10일에 동국대(서울 지역)로 시험을 보러 갔는데 지하철에 사람이 어쩜 그렇게 많은지 지옥같다고 생각..
2016.10.12