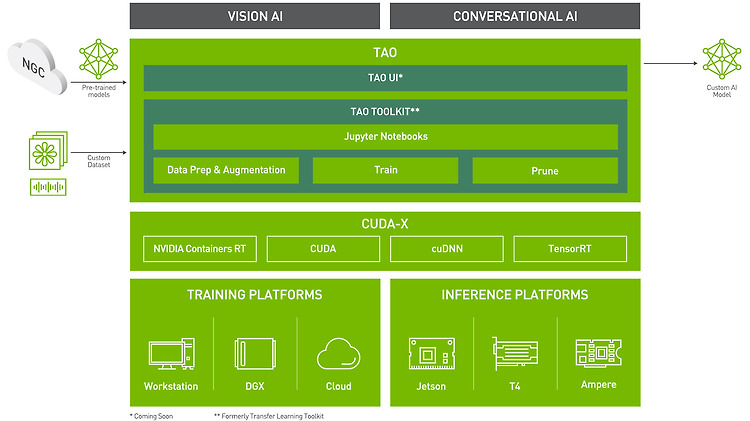
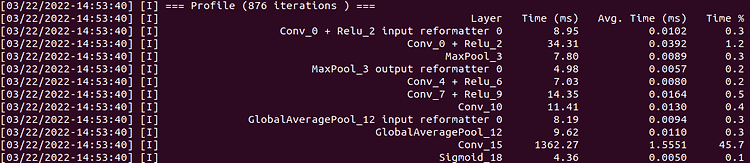
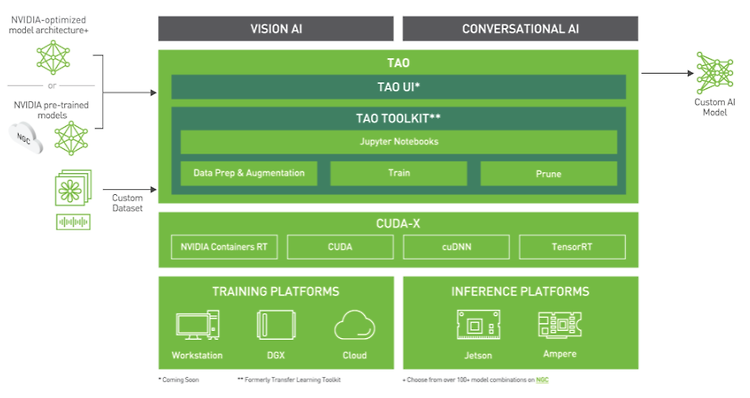
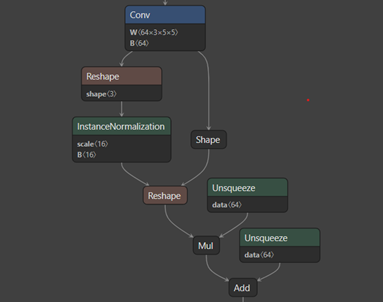
[NVIDIA TAO Toolkit] TAO Toolkit 개요
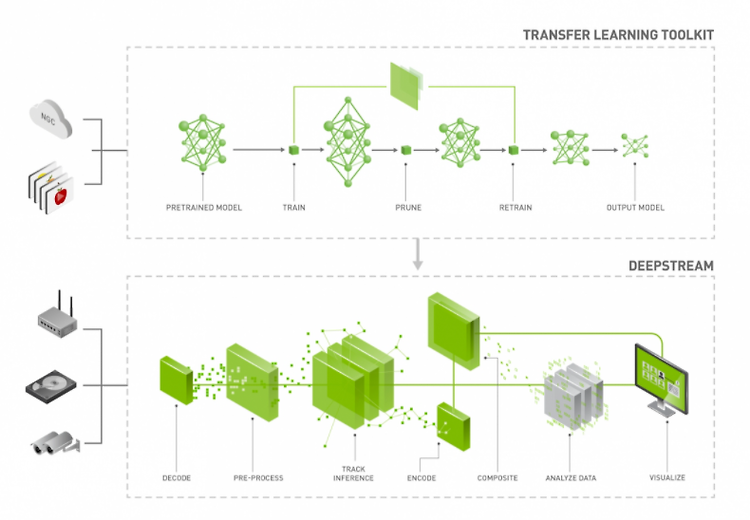
NVIDIA TAO Toolkit을 이용하여 사전 훈련된 NVIDIA 모델에 custom dataset을 적용하여 Computer Vision(이하 CV) 모델을 만들거나 Conversational AI(이하 Conv AI) models을 만들 수 있는 툴킷이다. 비전 분야에서는 주로 object detection, image classification, segmentation, keypoint estimation 등의 모델들을 fine-tuning 할 수 있다. 특히 pre-trained 모델에 새로운 클래스를 추가할 수도 있고, 다양한 케이스에 맞게 다시 학습 시킬 수 있으며, TAO Toolkit은 학습과 관련된 hyperparameter들을 수정하여 custom AI model을 생성할 수 있다...
2022.05.03