[Transformer] Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
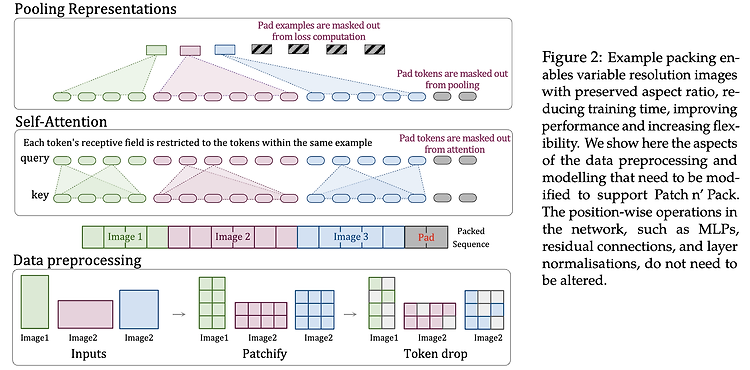
Overview 얼마전 Google DeepMind에서 "Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution" 라는 논문이 나왔습니다. 기존 컴퓨터 비전 모델에서는 이미지를 처리하기 전에 고정된 해상도로 이미지 크기를 설정하게 되고, ViT(Vision Transformer)와 같은 모델은 flexible sequence-based modeling을 하기 때문에 다양한 input sequence length를 제공하게 됩니다. 본 논문에서는 임의의 해상도와 종횡비(aspect ratio)를 처리하기 위해 학습 중에 sequence packing을 사용하는 NaViT(Native Resolution ViT)를 제안합니..
2023.07.21