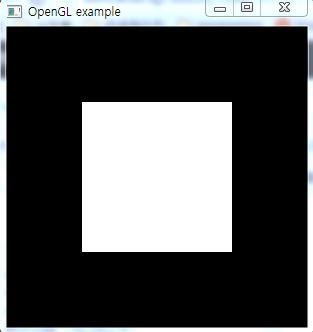
OpenGL 사각형그리기 예제2 - glViewport
OpenGL 사각형그리기 예제2 소스코드 #include #include #include #include void MyDisplay(){ glClear(GL_COLOR_BUFFER_BIT); // GL상태변수 설정, 프레임 버퍼를 초기화 // 초기화 될 색은 glutClearColor에서 사용된 색 glViewport(0, 0, 300, 300); glColor3f(1.0, 1.0, 1.0); // glBegin(GL_POLYGON); // 입력요소 기본정의 glVertex3f(-0.5, -0.5, 0.0); glVertex3f(0.5, -0.5, 0.0); glVertex3f(0.5, 0.5, 0.0); glVertex3f(-0.5, 0.5, 0.0); glEnd(); glFlush(); } int m..
2015.11.22