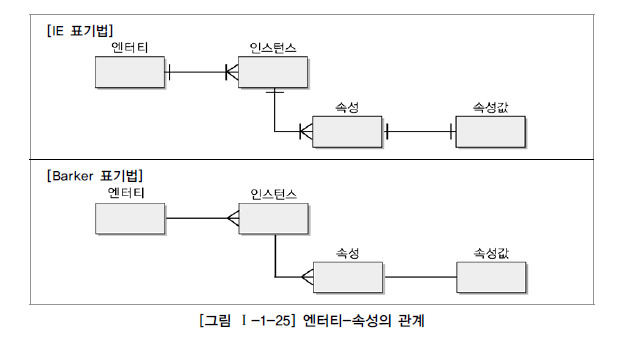
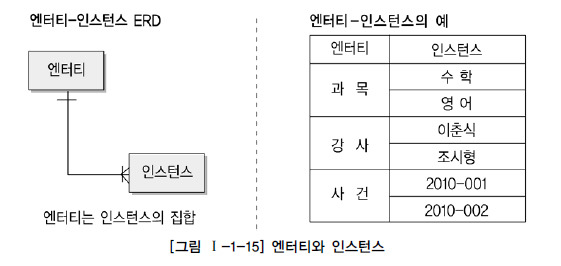
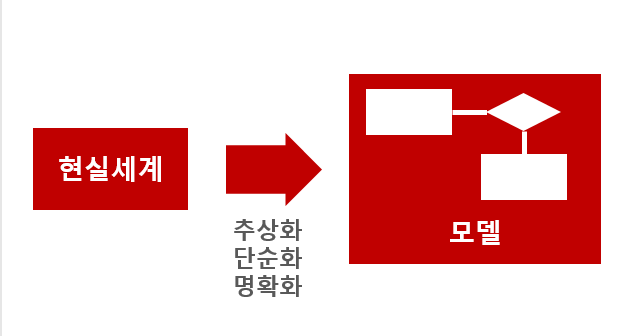
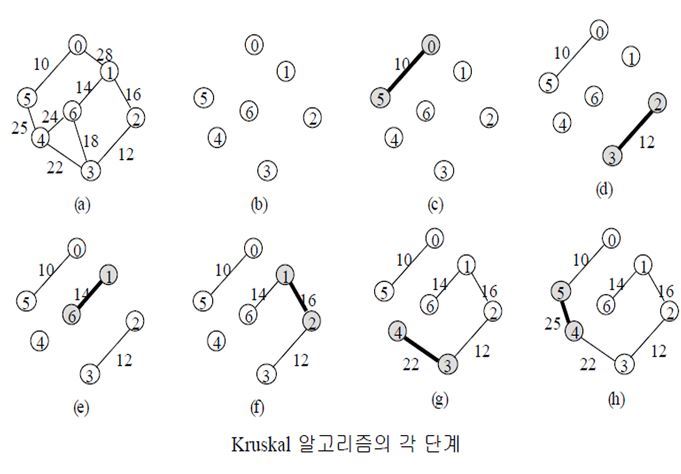
Greedy Algorithm (탐욕 알고리즘, 그리디 알고리즘)
Greedy Algorithm은 해답에 포함될 원소들을 차례로 선택하는 과정을 거치게 되는데, 각 단계에서는 전체적인 상황을 종합적으로 판단하고, 고려하여 결정하는 것이아니라 현 시점의 정보를 바탕으로 가장 이익이 되는 원소들을 선택하는 방법이라고 할 수 있다. 복잡한 과정을 거치지 않고, 상황을 종합적으로 판단하는게 아니기 때문에 매우 빠른 알고리즘이라고 할 수 있다. 이러한 Greedy Algorithm은 '최적화 문제(optimization problem)'를 해결하기 위한 방법의 일환으로서, 예를들어 최소비용신장트리를 구하는 문제를 예로 들 수 있다. 주어진 문제에 대해 최적해를 구하는데 있어서, 문제가 부문제들로 쪼개지고, 그러한 각 부문제들의 최적해로부터 효율적으로 최적해를 구하게 될 때 Gr..
2016.04.11