[Paper Review] Adaptive Wing Loss for Robust Face Alignment via Heatmap Regression
GitHub : https://github.com/protossw512/AdaptiveWingLoss
Paper : https://arxiv.org/abs/1904.07399
이번에 리뷰할 논문은 ICCV 2019에 소개되었던 Adaptive Wing Loss 논문입니다.
Introduction
본 논문에서는 face alignment (= facial landmark localization)문제에 대해 heatmap regression 방법을 사용할 때 효과적인 Adaptive Wing loss를 소개합니다. 이 loss function은 foreground pixel과 background pixel의 불균형 문제를 해결하기 위해 등장하였고, 여기서 Adaptive가 의미하는 바는 background pixel에 대한 loss는 적게 일으키고, foreground pixel에 대한 loss는 크게 일으키는 것을 의미합니다. 이러한 방식으로 loss를 일으키면 landmark localization을 할 때 더 중요한 pixel에 집중하여 학습할 수 있도록 합니다.
또한 face alignment의 정확도를 향상 시키기 위해 boundary prediction 및 boundary coordinate가 있는 CoordConv를 소개합니다. 이러한 방식은 COFW, 300W, WFLW를 포함한 다양한 벤치마크에 대해 실험 했을 때 SOTA를 달성합니다. 또한 Adaptive Wing loss는 다른 Heatmap Regression 작업에 적용할 수 있으므로 용이합니다.
MSE의 단점
본 논문에서 MSE 단점을 아래와 같이 나열하고 있습니다.

위 그림과 같이 Heatmap Regression을 할 때 MSE loss를 사용하게 되면 아래와 같은 단점이 있다고 합니다.
- MSE 방식은 small error에는 민감하지 않기 때문에 Gaussian distribution을 정확하게 찾기가 힘듦 (흐릿하게 찾아짐)
- 학습하는 동안 모든 pixel은 동일한 loss function과 동일한 weight를 갖지만, background pixel은 전체 heatmap에서 차지하는 면적이 매우 큼
이 두 가지 단점의 결과로 그림 2c 처럼 흐릿하고 dilated heatmap을 예측하는 경향이 있습니다. 이러한 heatmap은 facial landmark를 잘못 추정하게 되는 결과를 가져오게 됩니다. 기존의 Wing Loss 같은 경우 coordinate regression을 개선하는데 큰 효과가 있었지만, heatmap regression에는 적용할 수 없다고 합니다. heatmap regression에 적용할 수 없는 이유는 background pixel의 small error는 상당한 gradient를 누적하여 training process를 분산시킨다고 하네요. 따라서 본 논문에서는 이러한 단점을 모두 해결할 수 있는 Adaptive Wing Loss를 제안하였습니다.
CoordConv를 추가한 이유
Stacked Hourglass(HG)와 같은 모델 구조는 top-down, bottom-up 구조를 가지는 CNN 블록으로 이루어져 있는데, 이 때 convolution 연산의 변환 불변성(translation invariance)으로 인해 network는 facial landmark에 유용한 좌표 정보를 제대로 학습할 수 없다고 합니다. 왜냐하면 사람의 얼굴 구조는 상대적으로 안정적이기 때문이라고 하네요. 안정적인 face 구조를 학습하기에는 CNN 방법은 조금 오버 스펙 느낌입니다.
그래서 Liuet al.이 제안한 CoordConv 방법을 사용했다고 합니다. CoordConv 방법은 x, y에 대한 좌표 정보를 같이 concatenate 해줍니다. 즉, 전체 좌표 정보와 이전 HG 모듈에서 예측한 boundary 정보만 모델에 인코딩합니다. 인코딩 된 좌표 정보는 localization 성능을 더욱 더 향상 시키는 결과를 가져왔다고 하네요.
CoordConv 구조는 아래와 같이 feature map에 coordinate 정보로 채워진 extra channel을 concatenate 한다고 합니다.

CoordConv 논문에 따르면 아래와 같이 학습된다고 합니다. 확실히 일반 conv layer를 사용하는 방법 보다 깔끔하게 prediction이 되는 것을 확인 할 수 있습니다.

본 논문에 적용시키면 아래와 같습니다.

Model
모델 구조는 아래와 같습니다. stacked HG는 GT bbox로 잘라낸 얼굴 이미지 사진을 입력으로 받고, 각 landmark에 대해 각각 하나의 예측된 heatmap을 출력합니다. facial boundary를 예측하기 위해 채널이 추가됩니다. network의 첫번째 convolution layer 전에 coordinate encoding 이 추가됩니다.

Adaptive Wing Loss for Face Alignment
원래 loss 같은 경우 gradient의 값이 크면 loss 함수가 큰 영향력을 가지고, gradient의 값이 작으면 loss 함수가 작은 영향력을 가지게 됩니다. 그렇다면 loss가 수렴할 조건은 $y$와 $\hat{y}$간의 차이가 0이 되는 것인데, 그러기 위해서는 모든 error의 영향력이 골고루 고려되어 균형있게 학습이 되어야 합니다. 즉 negative error와 positive error가 균형있게 학습되어야 합니다.
MSE loss
MSE 같은 경우 gradient가 linear하기 때문에 small error에서 small influence를 가지게 되고, 결과적으로 small error를 유지한 채 학습이 끝나게 됩니다.
L1 loss
L1 같은 경우 gradient가 constant 입니다. 따라서 small error와 large error가 모두 같은 influence를 가지게 됩니다. 또한 L1의 경우 0에서 미분 가능하지 않기 때문에 train도 불안정한 결과를 갖습니다.
Wing loss
이는 두 loss의 문제를 개선하기 위해 등장하였지만, 0에서 미분이 불가능하기 때문에 수렴하기가 어렵다고 하네요.
그래서 결국 여기서 필요한 loss function은 다음과 같은 형태를 가져야 합니다.
foreground
영향력이 증가하여 error를 줄이는데 집중하다가 error가 0에 가까워지면 영향력이 줄어들어 더 이상 큰 gradient를 발생시키지 않아야 함
background
error가 천천히 0으로 줄어들다가 small error에서 비교적 적은 영향력을 줌으로써 background에 더 이상 집중하지 않도록 해야함
즉, loss가 1에 가까울 수록 기존 small error의 영향이 증가해야하고, loss가 0에 가까울 수록 MSE 손실과 유사하게 동작해야 올바르게 face alignment를 학습할 수 있습니다. AW Loss는 다음과 같습니다.
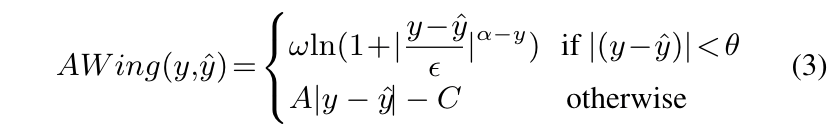
class AWing(nn.Module):
def __init__(self, alpha=2.1, omega=14, epsilon=1, theta=0.5):
super().__init__()
self.alpha = float(alpha)
self.omega = float(omega)
self.epsilon = float(epsilon)
self.theta = float(theta)
def forward(self, y_pred , y):
lossMat = torch.zeros_like(y_pred)
A = self.omega * (1/(1+(self.theta/self.epsilon)**(self.alpha-y)))*(self.alpha-y)*((self.theta/self.epsilon)**(self.alpha-y-1))/self.epsilon
C = self.theta*A - self.omega*torch.log(1+(self.theta/self.epsilon)**(self.alpha-y))
case1_ind = torch.abs(y-y_pred) < self.theta
case2_ind = torch.abs(y-y_pred) >= self.theta
lossMat[case1_ind] = self.omega*torch.log(1+torch.abs((y[case1_ind]-y_pred[case1_ind])/self.epsilon)**(self.alpha-y[case1_ind]))
lossMat[case2_ind] = A[case2_ind]*torch.abs(y[case2_ind]-y_pred[case2_ind]) - C[case2_ind]
return lossMat
Weighted loss map
또한 여기서 등장하는 개념이 Weighted loss map 라는 개념입니다. 우리가 생성하려는 heatmap 의 크기는 64x64이고 gaussian 커널의 크기는 7x7 이므로 실제 foreground 는 1.2% 밖에 되지 않는다고 하네요. 따라서 map을 아래와 같이 만듭니다. H는 groud truth heatmap 이고 값이 0.2 보다 큰 모든 픽셀은 1로 아닌 건 0으로 바꿉니다. 확실히 keypoint를 커버하는 영역이 늘어남으로 인해 foreground의 영향력이 커집니다.

Experiments
Evaluation Metric 은 Normalized Mean Error (NME)을 사용했다고 합니다.

실험 결과는 아래와 같습니다.


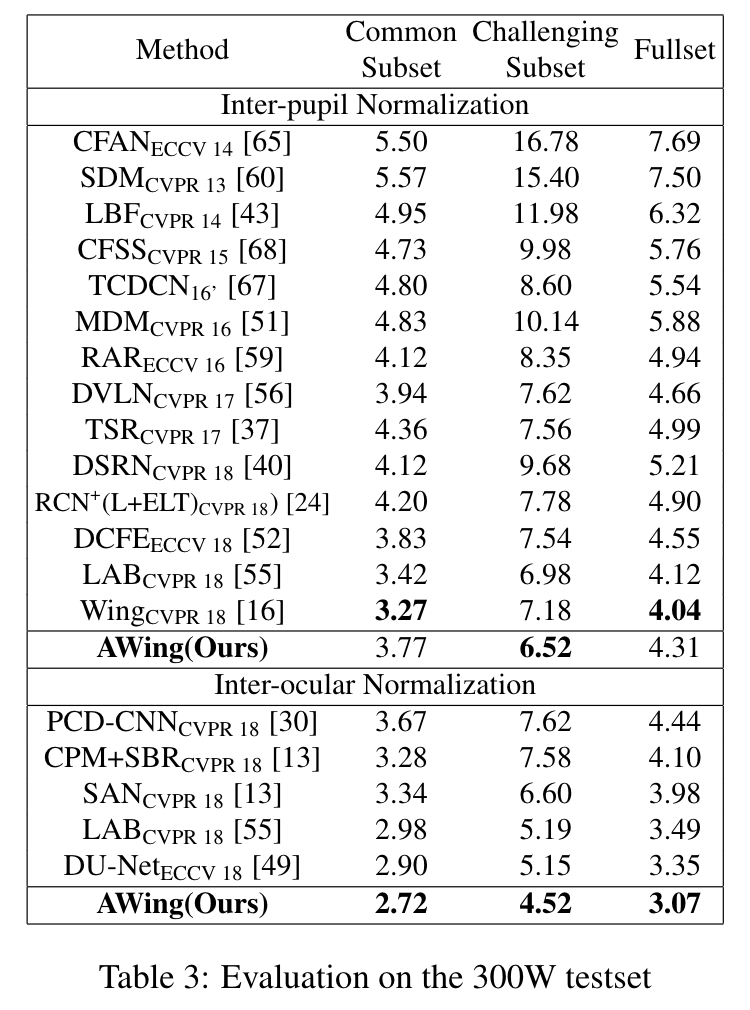
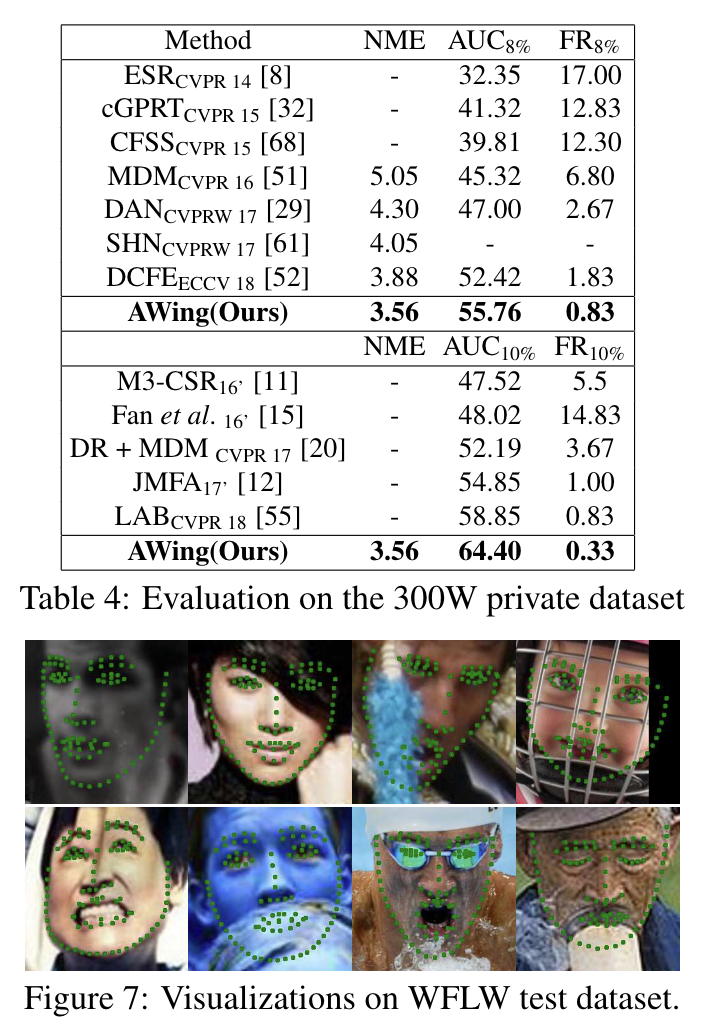
정량평가 결과는 아래와 같습니다.
