[Paper Review] FairMOT : A Simple Baseline for Multi-Object Tracking
Paper : https://arxiv.org/pdf/2004.01888v4.pdf
Github : https://github.com/ifzhang/FairMOT
ifzhang/FairMOT
A simple baseline for one-shot multi-object tracking - ifzhang/FairMOT
github.com




1. Introduction
MOT(Multi-Object Tracking)는 컴퓨터 비전 분야에서 longstanding goal 이다. MOT의 목적은 연속적인 프레임에서 여러 관심 객체의 궤적을 추정하는 것이다. 객체의 궤적을 잘 추적하게 되면 Action Recognition, Sport Videos Analysis, Elderly Care, Human Computer Interaction 와 같은 분야에서 널리 응용 될 수 있다.
SOTA 방법은 MOT 를 아래와 같이 두 가지 단계로 나눈다.
Object Detection Model
- 영상에서 관심있는 경계 상자(Bounding Box) 영역의 위치를 추정
Association Model
- 각 경계 상자에 대한 Re-identification(이하 Re-ID) 특징을 추출하여 정의된 특정 메트릭에 따라 기존에 존재하는 트랙 중 하나에 연결시킴
이러한 최근의 Object Detection 및 Re-ID 기술들이 발전함에 따라 추적 성능이 향상되고 있지만 이러한 두 단계 끼리 특징을 공유하지 않기 때문에 실시간 성능을 보장할 수 없다는 문제를 가진다. 최근 멀티 태스킹 학습 방식이 떠오름에 따라 객체를 탐지하고, Re-ID 특징까지 학습하는 One-Shot 방법이 나타나기 시작했다. 대부분의 특징이 두 모델에 공유되기 때문에 추론 시간을 크게 줄일 수 있다. 그러나 이러한 One-Shot 방법의 정확도는 Two-step 방법에 비해 현저히 떨어진다는 단점을 갖는다. 그래서 이 두 작업을 결합할 때, "어떠한 트릭"을 사용하여 정확도를 높이는 방식으로 학습해야한다.
MOT 정확도에 영향을 미치는 세 가지 중요한 요소는 다음과 같다.
(1) Anchors don't fit Re-ID
현재 one-shot tracker 는 모두 객체 탐지기 기반이기 때문에 anchor 를 기반으로 하고있다. 그러나 anchor 는 Re-ID 특징을 학습하는데 적합하지 않다. 왜냐하면 서로 다른 이미지 패치에 해당하는 multiple anchors 가 동일한 객체의 identity 를 추정할 필요가 있는데, 이로 인해 신경망에 심각한 ambiguity 가 발생 하기 때문이다. 즉, 주변에 다른 객체를 나타내는 여러 anchor 들은 학습 시 모호성을 줄 수 있다. 또한 feature map은 일반적으로 정확도와 속도의 trade off 를 위해 8번씩 down-sampling 된다. 이는 객체 중심이 객체의 identity 를 예측하기 위해 coarse anchor 위치에서 추출된 특징과 align 되지 않을 수 있기 때문에 탐지에는 적합하지만, Re-ID 에는 너무 coarse 하다는 문제점을 가진다. 따라서 high-resolution feature map 의 top 에서 픽셀 방식의 keypoint estimation (object center) 추정 및 identity classification 를 통해 이러한 문제를 해결한다.
(2) Multi-Layer Feature Aggregation
Re-ID 특징은 small 및 large 객체들을 모두 accommodate 하기 위해 low-level 및 high-level 특징들을 모두 활용해야한다. 본 논문에서는 스케일 변화를 처리하는 능력을 향상 시켜 one-shot 방법 기반으로 identity switch 를 줄였다. two-step 방법의 경우 cropping 및 resizing 작업 후 물체의 스케일이 비슷해진 채로 적용되기 때문에 스케일 문제를 개선 시킬 필요가 없다.
(3) Dimensionality of the ReID Features
이전의 Re-ID 방법들은 일반적으로 high dimensional feature 들을 학습하고, 벤치마크에서 좋은 결과를 얻어왔다. 하지만 본 논문에서는 Re-ID 보다 학습 이미지가 적기 때문에(Re-ID 데이터 세트는 잘린 이미지 만 제공하기 때문) lower-dimensional feature 가 MOT에 실제로 더 좋다는 사실을 발견하였다. 이러한 lower-dimensional feature 를 사용하면 small data 에 대한 overfitting 을 줄이고, tracking robustness 를 향상 시킬 수 있다.

먼저, anchor-free obejct detection 방법을 통해 high-resolution feature map에서 object center 를 추정한다. anchor 를 제거하게 되면 ambiguity 문제가 완화되고, high-resolution feature map 을 사용하여 Re-ID 특징을 object center 에 더 잘 align 시킬 수 있다. 그 다음 객체의 identity 를 예측하는데 사용되는 픽셀 단위의 Re-ID 특징을 추정하기 위해 parallel branch 를 추가한다. 특히 계산 시간을 단축할 뿐만 아니라 feature matching 의 robustness 를 향상시키는 low-dimensional Re-ID 특징을 학습하게 된다. 본 논문에서는 backbone 에 Deep Layer Aggregation operator 를 사용하여 다양한 스케일의 객체를 처리하기 위해 여러 레이어의 특징들을 통합한다.
MOT Chanllenge 벤치 마크에 대해 평가 한 결과 2DMOT15, MOT16, MOT17, MOT20 데이터 세트에서 all online tracker 중에서 1위를 차지하였다. 또한, offline tracker 보다 성능이 뛰어나다. 이러한 접근 방식은 매우 simple 하며, 30 FPS 로 동작한다.
2. Approach

2.1 Backbone Network
정확도와 속도의 trade-off 를 위하여 ResNet-34 를 백본으로 설정하였다. 다양한 스케일의 객체를 수용하기 위해 Deep Layer Aggregation(DLA)이 백본에 적용된다. original DLA와는 달리, Feature Pyramid Network(FPN) 와 유사한 low-level 및 high-level feature 간에 더 많은 skip connection 이 존재한다. 또한 up-sampling 모듈의 모든 컨볼루션 레이어는 deformable convolution layer 로 대체되어 객체 스케일 및 포즈에 따라 receptive field 를 동적으로 조정할 수 있다. 이러한 변경 사항은 align 문제를 완화 하는데 도움을 줄 수 있다. 이 모델의 이름은 DLA-34 로 정한다. 입력 이미지의 크기를 H x W 라고 하면 output feature map 의 모양은 C x H' x W' 이며, 이 때 H' 는 H/4 이며, W'는 W/4 이다.
2.2 Object Detection Branch
객체 탐지는 high-resolution feature map 에서 center-based 의 bounding box regression task 를 수행한다. 특히 3개의 parallel regression head 가 백본 신경망에 추가되어 각각 heatmap, object center offset, bounding box size 를 추정한다. 각 head 는 3x3 conv(256 channel) 을 백본 신경망의 output feature map에 적용한 다음, final target 을 생성하는 1x1 conv 를 적용하여 구현된다.
Heatmap Head
- 이 head 는 객체 중심의 위치를 추정한다. landmark point estimation task 의 표준인 heatmap 기반 representation 이 여기서 사용된다. 특히 heatmap 의 dimension 은 1 x H x W 이다. heatmap 의 위치에 대한 response 는 ground-truth object center 로 붕괴될 경우의 반응으로 예상된다. heatmap 의 위치와 object center 사이의 거리에 따라 response 는 기하 급수적으로 감소한다.
Center Offset
- head 는 객체를 보다 정확하게 localization 한다. feature map 의 stride 는 non-negligible quantization error 를 유발할 수 있다. 객체 탐지의 성능의 이점은 미미할 수 있으나, Re-ID 의 특징은 정확하게 object center 에 따라 추출되어야 함으로 tracking 에서는 중요하다는 특징을 가진다. 실험에서 Re-ID 의 특징을 object center 와 carefull alignment 하는 것이 성능에 중요하다는 것을 발견하였다.
Box Size Head
- 이는 각 anchor 위치에서 target bounding box 의 높이와 너비를 추정한다. 이 head 는 Re-ID 특징과는 직접적인 관련이 없지만, localization 정확도는 객체 탐지 성능 평가에 영향을 미친다.
2.3 Identity Embedding Branch
identity embedding branch 의 목표는 다른 객체와 구별할 수 있는 특징을 생성하는 것이다. 이상적으로는 서로 다른 객체 사이의 거리가 같은 객체 사이의 거리보다 커야한다. 즉, 같은 객체는 다른 프레임 상에서의 위치가 가까이 붙어있는 편이 이상적이다. 다른 객체와 구별할 수 있는 특징을 생성하기 위해 백본 특징 위에 128개의 커널이 포함된 conv layer 를 적용하여 각 위치에 대한 identity embedding feature 를 추출한다. output feature map 인 E 는 128 x W x H 영역에 포함되며, Re-ID feature 인 x, y 에서의 E 는 128에 속하고, 객체의 x, y 는 feature map 으로부터 추출된다.
2.4 Loss Function
Heatmap Loss
- heatmap 의 손실함수는 이미지에서 GT box 인 b 에 대하여 object center 를 구한다. 그 다음 각각의 위치는 feature map 에서 stride 를 divide 함으로써 구한다. 그 다음 x, y에서 heatmap response 는 Mxy 에 의해 구해지는데, 여기서 N은 객체 수를 뜻하며, σ 은 standard deviation 을 뜻한다. 손실 함수는 pixel-wise logistic regression with focal loss 를 사용한다. 말로 설명하니까 힘들다. 영어와 수식을 보는게 낫겠다. .. .... . 여기서의 M은 추정된 heatmap 을 뜻하며, 알파와 베타는 파라미터이다...

Offset and Size Loss
- 본 논문에서는 출력의 size 를 S 라 표현하였고, offset 을 O 라고 표현하였다. 이미지에서 각 GT box 인 b 를 통해 size 를 계산 할 수 있다. 또한 GT offset 도 계산 할 수 있다. two head 에 대한 손실 함수는 l1 을 사용하였으며, 아래와 같다.

Identity embedding Loss
- 본 논문에서는 object identity embedding 을 classification task 로 둔다. 특히 학습 데이터 세트에서 same identity 의 모든 instance 는 하나의 클래스로 취급된다. 이미지의 각 GT box b 에 대해 heatmap 에서 객체 중심 좌표를 얻는다. 그러면 그 위치에서 identity feature vector 를 추출하여 class distribution vector p(k) 에 매핑하는 방법을 학습할 수 있다.
- GT class label 인 one-hot representation 를 Li(k) 로 표시한다. 그 다음 softmax loss 를 다음과 같이 계산한다. 여기서 K는 클래스의 갯수이다.

2.5 Online Tracking
Network Inference
- 신경망은 이전 "Towards real-time multi-object tracking." 논문에서와 같이 1088 x 608 크기의 이미지를 입력으로 넣는다. 예측된 heatmap 이외에도 heatmap score 를 기반으로 NMS(Non-Maximum Suppression)를 수행하여 peak keypoint 를 추출한다. heatmap score 가 임계 값 보다 큰 경우 keypoint 의 위치를 유지한다. 그 다음 추정된 offset 과 box 의 크기를 기반으로 bounding box 를 계산한다. 또한 추정된 object center 에서 identity embedding 을 추출한다.
Online Box Linking
- 본 논문에서는 표준 온라인 추적 알고리즘을 사용하여 box linking 을 수행한다. 첫번째 프레임의 estimated box 를 기반으로 여러 tracklet 을 초기화 한다. 다음 프레임에서는 Re-ID 특징 및 IoU 로 측정한 거리에 따라 box 를 기존 tracklet 에 연결한다. 또한 Kalman Filter 를 사용하여 현재 프레임에서 tracklet 의 위치를 예측한다. linked detection 에서 너무 멀면 해당 cost 를 무한대로 설정하여 탐지를 큰 움직임으로 연결되는 현상을 효과적으로 방지한다. apperance variation 을 처리하기 위하여 각 time step 에서 추적기의 appearance feature 를 업데이트 한다.
3. Experiments
3.1 Implementation Details
Zhou, Xingyi, Dequan Wang, and Philipp Krähenbühl. "Objects as points." arXiv preprint arXiv:1904.07850 (2019).
위 논문에서 제안한 DLA-34 의 변형을 기본 백본 신경망으로 사용한다. COCO detection dataset 에서 사전 학습 된 모델 파라미터는 모델을 초기화 하는데 사용된다. 또한 Adam optimizer 를 통해 모델을 30 epoch 에 대해 learning rate 1e-4 로 설정하여 학습시켰다. 학습 속도는 20 and 27 epoch 에서 1e-5 및 1e-6 으로 감소한다. 배치 크기는 12로 설정되며, rotation, scaling 및 color jittering 을 포함한 augmentation 을 적용하였다. 입력 이미지의 크기가 1088 x 608 로 조정되고 feature map resolution 은 272 x 152 이다. 두 개의 RTX 2080 GPU를 이용한 학습은 약 30 시간이 소요된다.
3.2 Ablative Study
Anchor-based vs. Anchor-free
- 이 전의 one-shot tracker 는 mis-alignment 로 고통받는 anchor 를 사용하였다. 본 논문에서는 detection branch 를 Towards real-time multi-object tracking 에서 사용된 anchor 기반 방법으로 대체함으로써 수치를 검증하기로 하였다. 공정한 비교를 위하여 두 가지 접근 방식의 나머지 요소는 동일하게 구성되며, anchor 기반 방법은 작은 데이터 세트를 사용할 때 매우 나쁜 결과를 얻었으며 표 1과 같다.

- 위 표에서와 같이 anchor-based 방법이 anchor-free 방법보다 일관되게 낮은 MOTA 점수를 얻는 것을 볼 수 있다. 예를 들어 stride 가 8인 경우 anchor-free 방법은 TPR(True Positive Rate) 이 85.5% 으로 훨씬 더 나은 TPR 점수를 달성한다. 이에 주된 요인은 anchor 와 obejct center 사이의 alignment 가 잘못 되면, 신경망 학습에 심각한 모호성이 생기기 때문이다. anchor-based 방법에 대해 feature map resolution 을 높이면 MOTA 점수도 저하된다. high-resolution feature map 을 사용하면 더 많은 양의 anchor unalign 되기 때문에 신경망 학습이 더욱 어려워진다. anchor 수가 크게 증가하면 GPU 메모리 용량을 초과하기 때문에 stride 2 의 대한 결과는 표시하지 않았다고 한다.
- anchor-free 접근법은 mis-alignment issue 를 덜 겪고, anchor-based 방법 보다 현저히 더 나은 MOTA 점수를 달성한다. 특히 stride 4 로 인해 ID switch 수가 137개에서 93 개로 줄어든다. stride 8에서 4로 줄이면 더 많은 이점이 있다는 것이다. stride 를 2로 줄이면 더 낮은 수준의 feature 가 유입되어 representation 이 appearance variation 에 less robust 해지므로 결과가 저하된다.
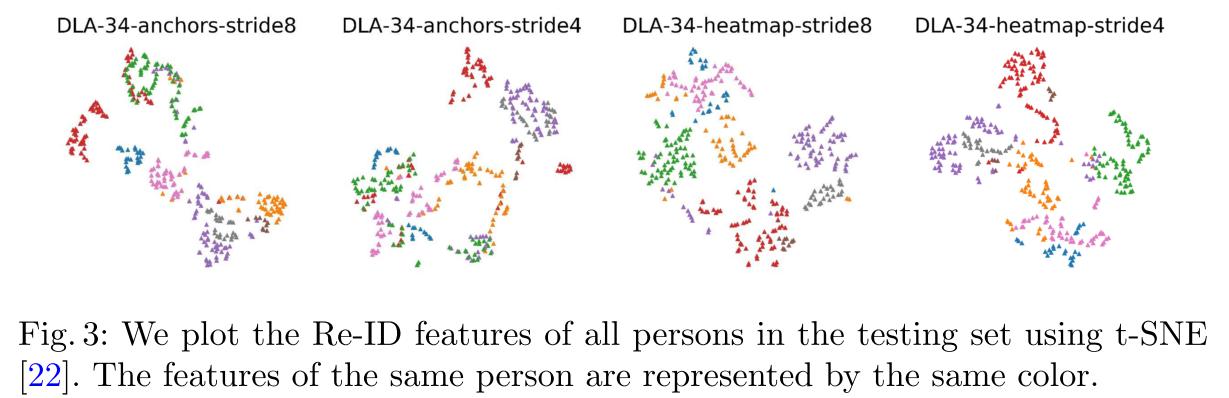
- 또한 아래 그림 3에서 다양한 모델로 학습한 Re-ID 특징을 시각화 하였다. 특히 stride 4인 경우의 anchor-based 접근 방식은 서로 다른 ID의 특징이 혼합되어있음을 볼 수 있다.
Multi-Layer Feature Aggregation
- 백본 신경망에서 multi-layer feature aggregation 의 영향을 평가한다. 특히 vanilla ResNet, FPN, HRNet, DLA-34 와 같은 다수의 백본을 평가하였으며, 접근법의 나머지 요소들은 동일하게 구성되었다. final feature map 의 stride 는 4 로 설정되었으며, vanilla ResNet 에 3개의 up-sampling 작업을 추가하여 stride-4 feature map 을 얻는다. 본 논문에서는 2DMOT15 데이터 세트의 학습 부분을 5개의 학습 비디오와 6개의 검증 비디오로 나누었다. cost computation 을 줄이기 위하여 대규모 훈련 데이터 세트는 사용되지 않는다.

- 위와 같이 ResNet-34 보다는 ResNet-50이 더 좋은 MOTA 점수를 나타낸다. 그러나 자세한 메트릭을 살펴보면 Re-ID 특징에서는 더 큰 사이즈의 신경망에서 얻는 이점을 얻지는 못한다. 결론적으로 multi-layer fusion 이 identity embedding 개선 측면에서 더 깊은 신경망을 사용하는 것 보다 확실한 이점을 가지고 있다는 것을 보여준다. ResNet-34를 기반으로 구축된 DLA-34는 훨씬 더 나은 MOTA 점수를 나타낸다. 특히 TPR 은 35.0% 에서 67.3%로 증가하여였으며, IDs 가 크게 감소한 것을 볼 수 있다. 그런데 HRNetV1 뿐만 아니라 V2 모델도 매우 강력한 탐지 결과를 내놓는다.
- 하지만 DLA-34에는 이에 비해 더 차별화된 Re-ID 특징이 있다. DLA-34 모델에서 deformable convolution 을 사용하는 이유는 작은 객체에 대한 down-sampling 으로 인한 mis-alignment 문제를 완화 시킬 수 있다. 아래 표3 에서 볼 수 있듯 DLA-34가 small and middle 객체에서 HRNetV2 보다 성능이 뛰어남을 알 수 있다.

The Re-ID Feature Dimension
- 이전 연구에서는 보통 ablation study 없이 512 dimensional feature 를 학습한다. 그러나 실험에서 feature dimension 이 중요한 역할을 한다는 것을 찾아냈다. 일반적으로 overfitting 을 피하기 위하여 high-dimensional Re-ID feature 를 학습하려면 대량의 학습 이미지가 필요하다. 이전의 two-step 접근 방식은 crop 된 이미지로 이루어진 대규모의 데이터 세트를 활용할 수 있기 때문에 이러한 문제가 덜 발생했으나, one-shot 방식은 자르지 않은 원본 이미지를 필요로 하기 때문에 이와 같은 데이터를 사용할 수 없다. 이를 위한 솔루션으로는 Re-ID 특징의 dimension 을 줄여 데이터에 대한 의존성을 줄일 수 있다.

- 위와 같이 dim 이 512 에서 128 로 감소하였을 때 모든 요소들이 일관적으로 개선되었다. 64 로 더 줄이게 되면 Re-ID 특징의 representative ability 이 손상되기 때문에 TPR 이 감소한다. MOTA 점수의 변화는 미미하지만, 실제로 IDs 의 수는 크게 줄어든다. 이는 실제로 사용자가 tracker 를 사용할 때 직관적으로 느낄 수 있는 척도라고 보면 된다. Re-ID feature dimension 을 줄임으로써 inference speed 도 약간 개선된다. lower-dimensional Re-ID feature 를 사용하는 것은 소수의 학습 데이터를 사용할 경우에만 적용된다. 데이터 수가 증가하게 되면 이러한 효과는 감소된다.
3.3 The State-of-the-arts
One-Shot MOT Methods
One-shot MOT 방법인 JDE 및 TrackRCNN 의 방법과 비교한 결과는 아래와 같다. 추론 속도는 모두 실시간 성능을 보장한다.
1. Wang, Zhongdao, et al. "Towards real-time multi-object tracking." arXiv preprint arXiv:1909.12605 (2019).
2. Voigtlaender, Paul, et al. "MOTS: Multi-object tracking and segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2019.

Two-Step MOT Methods
two-step 기반 방법들과 비교한 결과는 다음과 같다. public detection result 를 사용하지 않기 때문에 "private detector" protocol 을 사용한다. 테스트 하기 전에 각 데이터 세트에서 10 epoch 에 대한 모델을 fine-tuning 한다. 모든 결과는 MOT challenge evaluation server 에서 얻고, 본 논문의 접근 방식은 2DMOT15, MOT16, MOT17, MOT20 데이터 세트에서 1위를 차지한다. 본 논문의 접근 방식이 매우 간단한 점을 고려해봤을 때 매우 좋은 결과를 나타낸다. 또한 RAR15 및 POI 와 같은 고성능 tracker 는 본 논문의 방법보다 느리다.

4. Conclusion
one-shot multiple object tracking 을 위한 simple baseline 을 제시하였다. 본 논문에서는 이전의 one-shot 방식에서 two-step 방식과 비교할만한 결과를 못얻는지에 대한 연구부터 시작하였으며, object detection 및 Re-ID 에 anchor 를 사용하는 것이 성능을 저하시킨다는 것을 발견하였다. 특히 객체의 다른 부분에 해당하는 여러개의 주변 anchor 들은 신경망 훈련에 모호성을 유발한다. 또한 본 논문의 tracker 는 30 fps 를 달성하며, anchor-free 방식의 SOTA tracker 를 제시하였다.
'AI Research Topic > Object Understanding' 카테고리의 다른 글
| [Paper Review] An Image is Worth 16X16 Words : Transformers for Image Recognition at Scale (2) | 2020.11.01 |
|---|---|
| [Object Segmentation] ASPP : Atrous Spatial Pyramid Pooling (0) | 2020.07.19 |
| [Object Tracking] Two-Step MOT vs One-Shot MOT (0) | 2020.06.22 |
| [Object Detction] 3D Object Detection, Google Objectron (3) | 2020.05.27 |
| [Object Detection] Soft NMS (0) | 2020.03.08 |