[Deep Learning] Gradient clipping 사용하여 loss nan 문제 방지하기
Gradient clipping 을 하는 이유는 한마디로 학습 중 Gradient Vanishing 또는 Exploding 이 발생하는 것을 방지하여 학습을 안정화 시키기 위함이다.
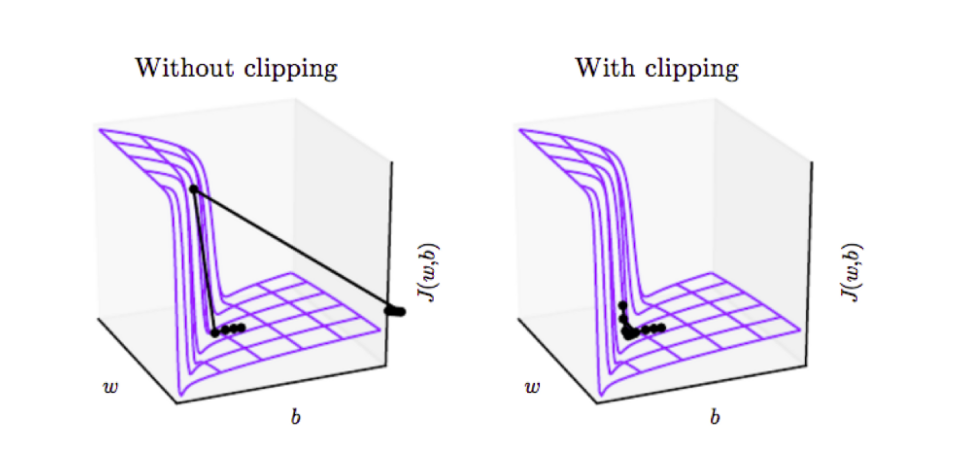
학습하고자 하는 모델이 RNN 이나 DNN 같은 강한 비선형 목적함수를 가지고 있을 경우에에 미분값은 매우 크거나 작아지는 경향이 있다. 이러한 결과는 여러개의 큰 가중치값을 곱할때 생기게 되는데, 이러한 가파른 지역에 다다르게되면, Backpropagation 과정에서의 Gradient Update Step 에서 파라미터들이 굉장히 크게 움직일 수 있다. 파라미터들이 크게 움직이게 되면 여태 진행했던 학습 Epoch 들이 무효화 될 수 있다. 즉 모델 학습 시 loss nan 문제를 겪을 수 있다.
Gradient는 현재 파라미터가 국부적인 지역안에서 Gradient Descent 알고리즘이 가야할 방향을 알려주게 되는데, 만약 이러한 국부지역을 벗어나게 된다면, 비용함수(Cost function)가 증가 할 수 있기 때문에 Parameter 업데이트시에 이러한 국부지역을 벗어나지 않도록 충분히 작은 Update Step 을 갖게 만들어야 한다.
이러한 문제를 해결하기 위해 Learning Rate를 매우 작게 설정할 수 있다. (e.g. 1e-5, ...) 이는 학습 속도를 매우 느리게 만들고,
잘못하면 local minima에 빠지게 만들 수 있다.
따라서 위의 솔루션보다 더 좋은 솔루션인 Gradient Clipping 을 사용할 수 있다. Gradient Clipping 의 개념은 Gradient의 최대 갯수를 제한하고, Gradient가 최대치를 넘게되면 Gradient의 크기를 재조정해서 Gradient의 크기를 조정하는 것이다. 이러한 Gradient Clipping은 최적화 알고리즘이 가야하는 방향은 그대로 유지하면서 업데이트되야하는 step의 크기(learning rate)를 자동으로 조정하게 된다.

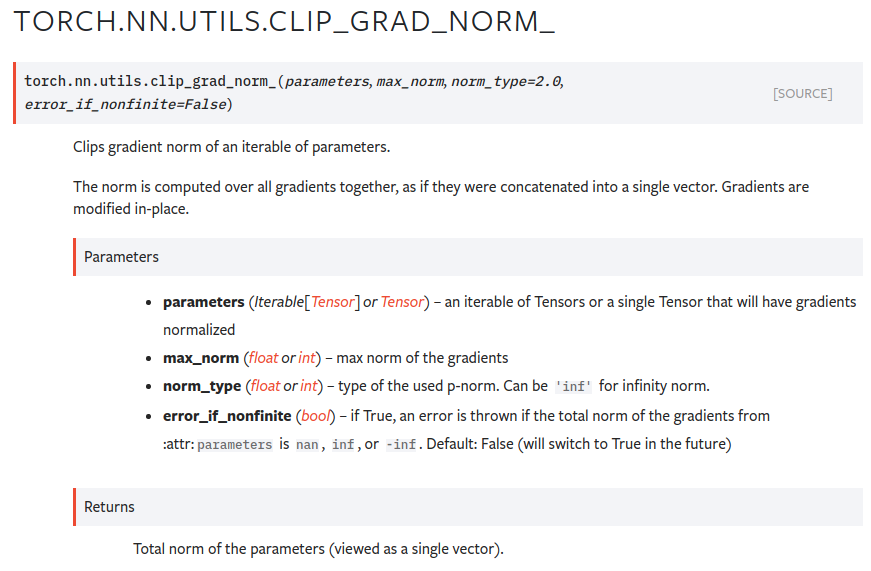
Pytorch에서 Gradient Clipping을 사용하는 방법은 아래와 같다.
# Since the gradients of optimizer's assigned params are unscaled, clips as usual:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
일반적으로 gradient clipping의 최대 gradient 갯수는 1로 설정 할 수 있다. (e.g. 5 or 10, ...)
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
with autocast():
output = model(input)
loss = loss_fn(output, target)
scaler.scale(loss).backward()
# Unscales the gradients of optimizer's assigned params in-place
scaler.unscale_(optimizer)
# Since the gradients of optimizer's assigned params are unscaled, clips as usual:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
# optimizer's gradients are already unscaled, so scaler.step does not unscale them,
# although it still skips optimizer.step() if the gradients contain infs or NaNs.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()
import warnings
import torch
from torch._six import inf
from typing import Union, Iterable
_tensor_or_tensors = Union[torch.Tensor, Iterable[torch.Tensor]]
[docs]def clip_grad_norm_(
parameters: _tensor_or_tensors, max_norm: float, norm_type: float = 2.0,
error_if_nonfinite: bool = False) -> torch.Tensor:
r"""Clips gradient norm of an iterable of parameters.
The norm is computed over all gradients together, as if they were
concatenated into a single vector. Gradients are modified in-place.
Args:
parameters (Iterable[Tensor] or Tensor): an iterable of Tensors or a
single Tensor that will have gradients normalized
max_norm (float or int): max norm of the gradients
norm_type (float or int): type of the used p-norm. Can be ``'inf'`` for
infinity norm.
error_if_nonfinite (bool): if True, an error is thrown if the total
norm of the gradients from :attr:``parameters`` is ``nan``,
``inf``, or ``-inf``. Default: False (will switch to True in the future)
Returns:
Total norm of the parameters (viewed as a single vector).
"""
if isinstance(parameters, torch.Tensor):
parameters = [parameters]
parameters = [p for p in parameters if p.grad is not None]
max_norm = float(max_norm)
norm_type = float(norm_type)
if len(parameters) == 0:
return torch.tensor(0.)
device = parameters[0].grad.device
if norm_type == inf:
norms = [p.grad.detach().abs().max().to(device) for p in parameters]
total_norm = norms[0] if len(norms) == 1 else torch.max(torch.stack(norms))
else:
total_norm = torch.norm(torch.stack([torch.norm(p.grad.detach(), norm_type).to(device) for p in parameters]), norm_type)
if total_norm.isnan() or total_norm.isinf():
if error_if_nonfinite:
raise RuntimeError(
f'The total norm of order {norm_type} for gradients from '
'`parameters` is non-finite, so it cannot be clipped. To disable '
'this error and scale the gradients by the non-finite norm anyway, '
'set `error_if_nonfinite=False`')
else:
warnings.warn("Non-finite norm encountered in torch.nn.utils.clip_grad_norm_; continuing anyway. "
"Note that the default behavior will change in a future release to error out "
"if a non-finite total norm is encountered. At that point, setting "
"error_if_nonfinite=false will be required to retain the old behavior.",
FutureWarning, stacklevel=2)
clip_coef = max_norm / (total_norm + 1e-6)
if clip_coef < 1:
for p in parameters:
p.grad.detach().mul_(clip_coef.to(p.grad.device))
return total_norm
def clip_grad_norm(
parameters: _tensor_or_tensors, max_norm: float, norm_type: float = 2.,
error_if_nonfinite: bool = False) -> torch.Tensor:
r"""Clips gradient norm of an iterable of parameters.
.. warning::
This method is now deprecated in favor of
:func:`torch.nn.utils.clip_grad_norm_`.
"""
warnings.warn("torch.nn.utils.clip_grad_norm is now deprecated in favor "
"of torch.nn.utils.clip_grad_norm_.", stacklevel=2)
return clip_grad_norm_(parameters, max_norm, norm_type, error_if_nonfinite)
[docs]def clip_grad_value_(parameters: _tensor_or_tensors, clip_value: float) -> None:
r"""Clips gradient of an iterable of parameters at specified value.
Gradients are modified in-place.
Args:
parameters (Iterable[Tensor] or Tensor): an iterable of Tensors or a
single Tensor that will have gradients normalized
clip_value (float or int): maximum allowed value of the gradients.
The gradients are clipped in the range
:math:`\left[\text{-clip\_value}, \text{clip\_value}\right]`
"""
if isinstance(parameters, torch.Tensor):
parameters = [parameters]
clip_value = float(clip_value)
for p in filter(lambda p: p.grad is not None, parameters):
p.grad.data.clamp_(min=-clip_value, max=clip_value)
참고자료 1 : https://pytorch.org/docs/stable/notes/amp_examples.html#gradient-clipping
Automatic Mixed Precision examples — PyTorch 1.9.0 documentation
Shortcuts
pytorch.org
참고자료 2 : https://dhhwang89.tistory.com/90
[번역:: Gradient Clipping] Why you should use gradient clipping
최근 자율주행차량 논문을 읽다가 계속해서 Gradient Clipping이라는 단어가 나와서 공부를 하던 도중에 해당 블로그 글을 찾게되서 Gradient Clipping이 무엇인지에 대해서 해당 블로그 글을 번역해보려
dhhwang89.tistory.com
참고자료 3 : https://sanghyu.tistory.com/87
[PyTorch] Gradient clipping (그래디언트 클리핑)
Gradient clipping을 하는 이유 주로 RNN계열에서 gradient vanishing이나 gradient exploding이 많이 발생하는데, gradient exploding을 방지하여 학습의 안정화를 도모하기 위해 사용하는 방법이다. Gradient..
sanghyu.tistory.com