[Model Optimization] Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations
Paper : https://arxiv.org/abs/2304.11267
Blog : https://ai.googleblog.com/2023/06/speed-is-all-you-need-on-device.html
Speed is all you need: On-device acceleration of large diffusion models via GPU-aware optimizations
Posted by Juhyun Lee and Raman Sarokin, Software Engineers, Core Systems & Experiences The proliferation of large diffusion models for image generation has led to a significant increase in model size and inference workloads. On-device ML inference in mobil
ai.googleblog.com
이번에 리뷰할 논문은 CVPR 2023에 소개된 Google LLC에서 제안된 Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations 입니다. On-device 환경에서 Diffusion 모델을 배포하기 위한 방법을 담고있습니다. Large diffusion model은 보통 10억 개 이상의 매개변수를 갖고 있어서 제한된 computing 능력, 메모리 리소스 등 문제가 있다고 하네요. 본 논문에서는 GPU 환경에서 Stable Diffusion 1.4 모델을 약 20회 정도 반복하여 추론 했을 때 512x512 이미지에 대해 INT8 quantization 없이 12초 미만으로 추론해내는 결과를 달성했다고 합니다.
GPU-Aware Optimizations
본 논문에서 주로 다루는 내용은 large diffusion model을 사용하여 텍스트로부터 이미지를 생성하는 작업입니다. 그 다음 stable diffusion의 특정 아키텍처에 대해 제안된 optimization 내용을 다루게 됩니다. text prompt로 추론을 수행할 때 원하는 설명을 넣게 되고, 추가 조건을 사용하여 reverse diffusion process가 진행됩니다. 즉, stable diffusion의 주요 구성 요소는 다음과 같이 textr embedder, noise generation, denoising neural network, image decoder가 포함됩니다.

Specialized Kernels: Group Norm and GELU
Group normalization (GN)은 UNet 아키텍처에서 등장하게 됩니다. 이러한 정규화 기법은 feature map의 채널을 더 작은 group으로 나누고, 각 그룹을 독립적으로 정규화하여 GN에 배치 크기에 덜 의존하고, 광범위한 배치 크기 및 다른 네트워크 아키텍처에 더 적합하게 적용될 수 있도록 작동됩니다. 아래 식과 같이 각 특성값
는 그룹의 평균값 및 분산 값으로 정규화 됩니다.

GN이 이루어지게 되면 reshape, mean, variance, normalize의 연산이 차례대로 일어나게 되는데, 본 논문에서는 intermediate tensor 없이 single GPU command로 GPU Shader 형태의 고유한 커널을 설계했습니다.
Gaussian Error Linear Unit (GELU)는 BERT, GPT, ViT 모델 등에서 ReLU 대신 사용되는 activation function인데, 아래 식과 같이 multiplication, addition, Gaussian error function과 같은 많은 계산을 포함하게 됩니다.


본 논문에서는 이 activation function을 split, multiplication 연산을 통해 GPU Shader를 구현하여 single draw call에서 실행할 수 있도록 했습니다.
Enhancing Attention Module Efficiency
Stable Diffusion의 text/image transformer는 text-to-image 생성 작업에 중요하게 작용하는 conditional distribution 모델링을 용이하게 하는데, 그럼에도 불구하고 self-cross-attention 메커니즘은 quadratic time, memory complexity로 인해 long sequence를 처리하기가 힘들다고 합니다. 그래서 이러한 computational bottleneck을 완화시키기 위해 2가지 최적화 방법을 제안합니다.
Partially Fused Softmax
attention computation은 UNect 구조에서 중간 레이어에 들어가게 됩니다. 아래 시식과 같이 Query, Key, Value 행렬로 이루어져있고, 일반적으로 N, M은 d보다 훨씬 크다고 하네요.
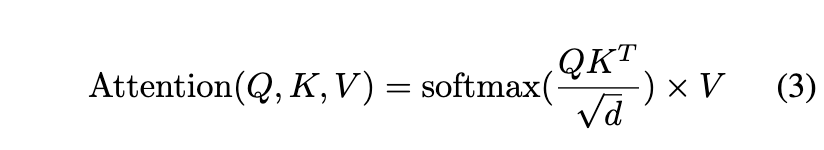
행렬에서 수행되는 softmax 연산은 2가지 단계로 나뉩니다. 첫번째는 reduction 연산, 두번째는 element-wise 연산입니다. reduction 연산 같은 경우 행렬 A의 각 행의 최대값과 수정된 지수 합 S의 계산을 의미합니다. 그 다음 벡터 L 및 S를 사용하여 행렬 A의 값을 정규화 하기 위해 element-wise 연산이 수행됩니다.
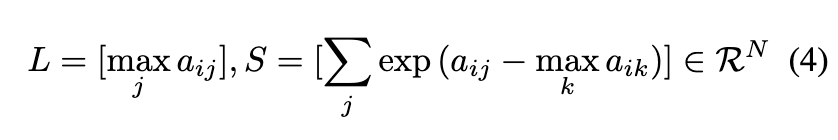
본 논문에서는 행렬 전체에서 softmax를 계산하지 않고, L 및 S 벡터를 계산하기 위해 reduction 작업을 위한 GPU Shader를 구현하여 크기 Nx2의 텐서를 생성합니다. softmax 계산은 행렬 V를 포함하는 다음 행렬 곱셈과 fuse 됩니다. 이러한 방식은 중간 과정의 메모리 사용량을 크게 줄일 수 있습니다.
FlashAttention
계산 복잡성을 줄이기 위해 모델의 품질을 약간 떨어뜨리고, module latency를 개선하려고 시도하는 approximate attention 방법들이 있는데, 반대로 FlashAttention은 tiling을 활용하여 GPU high bandwidth memory(HBM)와 on-chip SRAM 사이의 메모리 읽기/쓰기를 최소화 하는 IO-aware attention을 제안합니다. 이러한 방식은 표준 attention 방식보다 HBM access가 적기 때문에 다양한 SRAM 크기의 최적이고, 전반적으로 효율성이 향상된다고 하네요.
Winograd Convolution

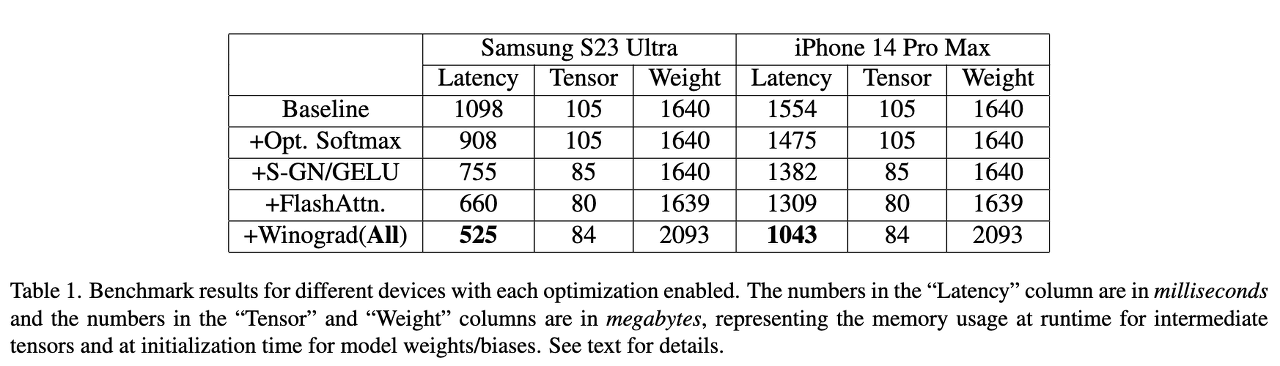
Winograd convolution은 conv 연산을 일련의 행렬 곱셈으로 변환한다고 합니다. 이는 변환 행렬을 신중하게 선택하기 때문에? 곱셈 연산을 많이 줄일 수 있다고 합니다. 그러나 더 큰 크기의 타일 크기를 사용할 때 메모리 사용량과 수치 오류가 증가한다고 하네요. stable diffusion의 backbone은 특히 이미지 디코더에서 3 x 3 conv layer에 크게 의존하며 레이어의 90%이상을 차지하게 됩니다. 그래서 본 논문에서는 3 x 3 conv layer에서 다양한 타일의 크기로 Winograd를 사용하는 potential benefit을 탐색합니다. 계산 효율성과 메모리 활용 사이의 최적의 균형을 제공하는 4x4 타일을 선택했다고 하네요.

Experiments
이 논문 외에도 파이토치 코리아에서 GPU 인식을 최적화 하여 스마트폰에서 Diffusion 모델을 구축하는 방식에 대한 글을 아래 링크에 정리해놓은 것이 있었습니다. 참고하시면 좋을 것 같습니다!
https://discuss.pytorch.kr/t/230616-ai/1827
[230616] 모두의연구소/아이펠이 전해드리는 오늘의 AI소식!
안녕하세요 국내 최대 오프라인 인공지능 커뮤니티 모두의연구소입니다! 오늘은 애플 기기에서 즐기는 Stable Diffusion, Eilixir를 이용한 Space 배포하기, 마지막으로 GPU 인식을 최적화해 스마트폰에
discuss.pytorch.kr
'AI Research Topic > Model Optimization' 카테고리의 다른 글
| [Model Optimization] ModelBench app (0) | 2023.08.18 |
|---|---|
| [Paper Review] FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization (0) | 2023.08.18 |