[Paper Review] Toward fast and accurate human pose estimation via soft-gated skip connections
Bulat, Adrian, et al. "Toward fast and accurate human pose estimation via soft-gated skip connections." arXiv preprint arXiv:2002.11098 (2020).
Paper : arxiv.org/abs/2002.11098
Toward fast and accurate human pose estimation via soft-gated skip connections
This paper is on highly accurate and highly efficient human pose estimation. Recent works based on Fully Convolutional Networks (FCNs) have demonstrated excellent results for this difficult problem. While residual connections within FCNs have proved to be
arxiv.org
1. Introduction
인간 자세 추정(Human Pose Estimation) 분야는 컴퓨터 비전 분야에서 가장 까다로운 문제중 하나이며 방대한 계산 리소스를 필요로 한다. 또한 많은 응용 분야에서 정확도 보장은 필수적이다. 기존에 존재하는 인간 자세 추정 방법들은 MPII, LSP, COCO 등의 까다로운 벤치마크에서 좋은 성능을 자랑하지만 메모리(in term of # parameters) 및 계산 능력(in terms of flops)을 고려한 방법들은 많이 연구가 되고 있지 않다. 따라서 본 논문에서는 가장 자세 추정 분야에서 기본적인 요소인 Skip Connection 에 주목하여 Residual Connection 을 재해석 하는 것이 필요하다고 주장하고 있다. 가장 간단한 것 부터 개선해보자는 취지이다.
그래서 나온 아이디어가 Gated Skip Connection 이다.

이는 모듈 내의 각 채널에 대한 데이터의 흐름을 제어하기 위하여 채널 별로 학습 가능한 매개변수가 존재하는 gated skip connection 을 제안하였다. 이는 기존에 사용하던 단순한 residual block 을 이 논문에서는 soft-gated skip connection 으로 대체하는 것을 제안하였다. 이전 단계의 정보가 채널 당 다음 단계로 전파되는 정도를 학습하는 것이다. 이는 각 모듈이 더 복잡한 특징을 학습하는 것을 가능하게 해준다.
또한 논문에서는 기존 자세 추정 분야에서 자주 쓰이는 Hourglass 모델과 U-Net 모델을 합쳐 Hybrid network 를 제안하고 있다. 이를 합쳐 신경망 내의 identity connection의 수를 최소화 하였으며, 동일한 수의 매개변수를 가지면서도 정확도를 향상 시켰다. 기존 Hourglass 모델과 비교할 때 성능 저하 없이 모델 크기 및 복잡성을 65% 정도 감소시켰다고 한다. 모델의 larger version 은 MPII 및 LSP 데이터 세트에서 SOTA 를 달성한다.
2. Related work
2.1 Efficient neural networks
뻔한 이야기이지만 신경망의 깊이가 깊어질수록 학습이 잘 안되는 등의 gradient vanishiong or exploding 문제가 발생하곤 하는데 이를 해결하기 위하여 소개된 개념이 skip connection 이었다. 이 skip connection 은 ResNet, DenseNet 등에 적용되어 많은 정확도 향상을 일으켰다.
또한 잠깐 Hourglass 모델과 U-Net 구조를 살펴보면 아래와 같다. 왼쪽이 Hourglass 모델이고 오른쪽이 U-Net 모델이다.
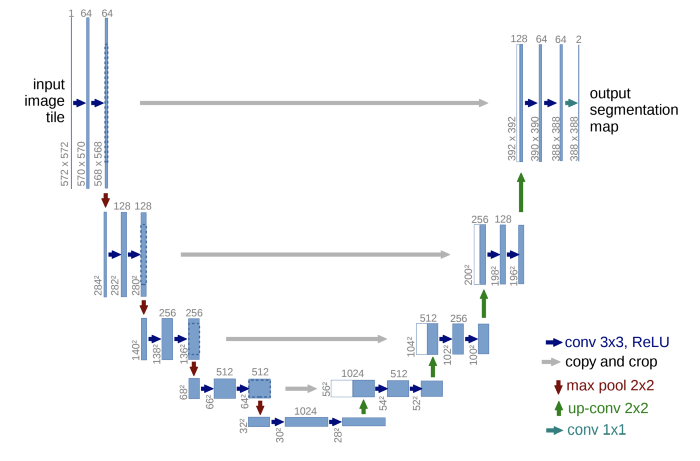
본 논문의 baseline 으로 쓰인 Stacked Hourglass Network 를 우선 간단하게 정리해보자면, 전체 신경망은 여러 겹의 Hourglass 즉 모래시계 모양의 배열로 이루어져있고, 이를 통해 Bottom-up, Top-down 과정을 반복하면서 다양한 resolution 의 정보를 학습할 수 있으며, 더 정확하게 자세 추정 즉 관절을 나타내는 keypoint 좌표들을 localization 하여 추정 할 수 있는 것이다. 이 모듈은 인코더-디코더(encoder-decoder) 구조로 되어있고 각 feature map 사이에 skip connection 이 포함되어있다. U-Net 도 마찬가지로 인코더-디코더 구조의 Fully Convolutional Networks 로 구성되어있다.
Newell, Alejandro, Kaiyu Yang, and Jia Deng. "Stacked hourglass networks for human pose estimation." European conference on computer vision. Springer, Cham, 2016.
Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015.
2.2 Human Pose Esitimation
주로 여기서는 single person pose estimation 을 다룬다. 참고로 이는 top-down 방식의 pose estimation 만을 설명하고 있었고, multi person pose estimation 은 bottom-up 방식인 OpenPose 등을 말하는 듯 하다. 그래서 보면 평가 지표에는 OpenPose 는 다루고 있지 않다.
수 많은 pose estimation 방법들은 computational requirement 를 적용하지 않고 신경망의 정확도를 높이는데 중점을 두었기 때문에 본 논문에서는 다양한 수준의 computational resource 에서 잘 작동하는 신경망을 제안한다. 또한 신경망의 가장 기본적인 구성요소 중 하나인 skip connection 을 개선시켰다.
3. Method
3.1 Soft-gated residual connections
기존의 Residual Module 은 깊은 신경망이 학습이 잘 되도록 하였으며, 정확도를 높일 수 있는 전형적인 방법이다. 각 residual unit 이 previous unit 에 대해 small correction 을 학습하면서 추정하게 된다. 본 논문에서는 전형적인 신경망 공식을 아래와 같이 hard gating function 이라고 정의하고 있었다.
하지만 이는 어떤 경우에 undesirable effect 를 가져오기 때문에 모델의 성능을 저해할 수도 있다고 주장한다. 본 논문에서는 residual network 구조에서 첫번째 및 마지막 unit 이 유지되는 한 내부에 존재하는 임의의 residual unit 을 제거해도 성능이 크게 저하되지 않았음을 발견하였다. 또한 Hourglass 모델에서는 일반적으로 인코더 및 디코더 내부의 각 resolution 수준에서 매우 적은 residual block 이 사용되기 때문에 (일반적으로는 한개) 이 block 을 수정하게 되면 학습이 잘 되지 않기 때문에 단순히 없앨 수는 없다. 따라서 새로운 방법인 soft gated connection 을 고안하게 되었다.
Sotf gating mechanism 은 다음과 같다.
각 파라미터의 의미는 다음과 같다.
- xl : 이전 레이어로부터 입력된 특징
- W : l 번째 residual block 으로부터의 weight set
- F : convolution layer set 을 사용하여 구현된 residual function
- α : backpropagation 으로 학습되는 channel-wise soft gate (scaling factor)
soft-gated skip connection 블록은 단계적으로 convolution 을 적용한 이전 SOTA 의 convolutional layer 에 skip connection 으로 학습 가능한 soft gate 구조를 더한 블록이다. 각각의 channel 이 서로 다른 정보를 담고 있으므로 channel-wise soft gate 가 feature 간 중요도를 조절해줌으로써 더 좋은 예측 성능을 보여줄 수 있는 것이다.
위 표에서처럼 identity transformation 을 사용하는 baseline 대비 sotf-gated residual connection 을 사용함으로써 성능을 향상시키는 결과를 보였다. skip connection에 sotf gate 를 적용하게 되면 불필요한 feature 의 비중을 줄여주고 중요한 feature 만을 남겨주게 된다.
아래 그래프는 soft gated connection 을 사용하기 위해 skip connection 에 추가한 scaling 계수들을 시각화 한 그림인데 흥미롭게도 대부분의 값이 0 주위에 클러스터링 되어있다는 것을 알 수 있다. 이는 대부분의 정보가 필요하지 않거나 잠재적으로 학습에 해로울 수 있다는 것을 시사한다. 이는 신경망의 깊이와는 상관 없이 신경망의 모든 계층에서 관찰된다. 또한 이전 block 에서 가져온 대부분의 feature은 채널 별 scaling 계수에 의해 필터링 된다.
또한 본 논문에서 제안하는 new hybrid network struction 는 introduction 에서 소개했던 것과 같이 Hourglass + U-Net 구조로 되어있다. 이는 신경망 내의 identity connection 을 최소화 함으로써 기존 신경망과 동일한 수의 매개변수를 사용하면서도 우수한 성능을 얻을 수 있다는 것을 보여주었다.
아래 신경망 구조를 살펴보면 (a) 는 baseline 이며, (b) 는 여기서 제안하는 soft gated connection 을 적용하는 방법 그리고 (c) 는 grouped convolution layer 를 적용한 방법이다. 위 그림에서 각 추가된 노란색 직사각형은 hierarchical residual module 을 나타내며, 빨간색 박스(왼편)는 max pooling, 그리고 파란색 박스(오른편)는 nearest neighbour upsampling 을 뜻한다.
아래와 같이 baseline 보다 제안하는 soft gated connection 방법이 0.5 % 의 성능 향상이 있었으며, grouped 방식은 오히려 성능이 soft gated connection 보다는 약간 떨어지는 것을 확인 할 수 있다.
3.3 Training
학습에 사용된 설정은 아래와 같다.
- the center of tight bounding box (center cropped to 256 x points is not provided)
- random rotation (from −30◦ to 30◦)
- scaling (from 0.75× to 1.25×)
- flipping and color using RMSprop
- batch size : 24
- epoch 75, 100 and 150
- learning rate : 2.5e^-4 to 1e^−5
- decay : 0
- loss function : MSE
4. Experimental Evaluation
데이터 세트는 MPII와 LSP 를 사용하였다.
PCK(Percentage of Correct Keypoint)는 참고로 예측한 키포인트와 GT 키포인트 사이의 거리가 특정 임계 값 내에 있는 경우를 고려하는 지표이다. 예를 들어 PCK@0.2 는 threshold 가 0.2 * torso diameter 로써 torso 는 사람의 몸통을 말한다. 보통 PCKh@0.5 를 사용하는데 PCKh 는 몸통이 아닌 머리 부분의 길이를 사용한 평가 지표이다. 보통 PCKh@0.5 를 많이 사용한다.
아래 사이트에서 SOTA 를 달성한다.
paperswithcode.com/task/pose-estimation
Papers with Code - Pose Estimation
Pose Estimation is a general problem in Computer Vision where we detect the position and orientation of an object. ( Image credit: [Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose](https://githu
paperswithcode.com
본 논문에서는 CU-Net 을 기반으로 성능을 평가하고 있다. CU-Net 은 참고로 Coupled U-Nets 구조이다.
Tang, Zhiqiang, et al. "CU-net: coupled U-nets." arXiv preprint arXiv:1808.06521 (2018).
본 논문에서는 stack 을 반으로 줄이고도 20% 정도 적은 parameter 로도 정확도 개선을 얻을 수 있다고 한다. 아래 표1의 3행에 보면 그 결과를 확인 할 수 있다. (the performance offered by CU-Net using 50% less HG stacks, 20% less parameters and FLOPs)
5. Summary (Contribution)
- residual units 을 재해석하여 새로운 Gated skip connections 제안
- 각 채널에는 현재 및 이전 residual module 간 데이터 흐름을 제어하는 학습 가능한 매개변수
- Hybrid Structure : HourGlass + U-Net
- 신경망 내의 identity connection 연결 수를 최소화
- 동일한 매개변수만으로도 성능 향상 효과
- State-of-the-art results on the MPII and LSP datasets
- Reduction of 3x in model size and complexity
- 모델 크기 및 복잡성 65% 감소
'AI Research Topic > Human Pose Estimation' 카테고리의 다른 글
꾸준희님의
글이 좋았다면 응원을 보내주세요!