[Pose Estimation] EfficientPose : Scalable single-person pose estimation
Groos, Daniel, Heri Ramampiaro, and Espen Ihlen. "EfficientPose: Scalable single-person pose estimation." arXiv preprint arXiv:2004.12186 (2020).
Paper : arxiv.org/abs/2004.12186
EfficientPose: Scalable single-person pose estimation
Human pose estimation facilitates markerless movement analysis in sports, as well as in clinical applications. Still, state-of-the-art models for human pose estimation generally do not meet the requirements for real-life deployment. The main reason for thi
arxiv.org
Github : github.com/daniegr/EfficientPose
daniegr/EfficientPose
Scalable single-person pose estimation. Contribute to daniegr/EfficientPose development by creating an account on GitHub.
github.com
인간 자세 추정(Human Pose Estimation)은 다양한 분야에서 markerless 기반 움직임 분석을 용이하게 하는 분야이다. 그러나 사람의 자세 추정을 위한 최신 모델들은 일반적으로 실제 deployment 요구사항들을 충족시키지 못한다는 문제점이 있다. 그 이유는 접근 방식들이 모두 계산량이 많기 때문이다. 따라서 본 논문에서는 최근 제안된 EfficientNet 의 이점을 활용하여 scalable single person pose estimation 이 가능한 convolutional neural network 를 제안한다.
이를 위해 effective multi-scale feature extractor 를 사용하는 EfficientPose 및 모바일용 bottleneck convolution 그리고 pose configuration 의 precision 을 향상시키는 upscaling 을 제안한다. 이는 실제로 1개보다 더 적은 GFLOP 을 소비하는 500K parameter 를 통해 edge device 에 배포가 가능하다. 이는 MPII 데이터 세트를 이용한 벤치마크에서 유명한 OpenPose 보다 성능이 훨씬 뛰어나면서 15배 정도 크기가 작으며, 다른 방법들 보다 20배 정도 효율적이라는 것을 보여준다.
1. Introduction
인간 자세 추정은 이미지 또는 비디오 프레임에서 스켈레톤 키포인트를 localization 하는 컴퓨터 비전 분야이다. 이는 야외 활동에서의 동작을 인식하거나 컴퓨터 애니메이션에서 동작 평가, 운동 연습 등에 이르기까지 다양한 분야에서 응용되고 있다. 또한 ConvNet 의 확산으로 인하여 자세 추정 분야가 급 발전하였고, 응용 영역이 점차 넓어지고 있다.
최근 EfficientNet 은 벤치마크에서 뛰어난 정확도를 보이고 있으며, computation 이 굉장히 효율적인 구조로 되어있다. 자세 추정 분야에서는 "정확도"를 보장하면서 "계산 효율적"인 구조들이 없다. OpenPose 는 실제 다양한 분야에서 응용되고 있지만 추론하는데 160 billion floating point operations (GFLOPs) 가 소요되므로 computation 측면에서 매우 비효율적이라고 할 수 있다. 또한 키포인트 추정치는 low-resolution 출력으로 제한된다. 이로인해 높은 정밀도가 필요한 스포츠 분야에서의 운동 평가, 의료 평가 등의 작업에서는 정확도 측면에서 적합하지 않다고 볼 수 있다. 이러한 문제에도 불구하고 OpenPose 는 markerless motion capture 작업에서 널리 응용되고 있는 유명한 방법이다.
따라서 본 논문에서는 "정확도"도 보장할 수 있으면서도 "계산 효율적"인 구조인 EfficientPose 라는 것을 제안한다. 본 논문의 Contribution 은 다음과 같다.
- 향상된 정밀도, 최적화 중 빠른 수렴(rapid convergence), 좋은 모델 크기, 낮은 컴퓨팅 비용을 만족하는 single person human pose estimation 방법인 EfficientPose 제안
- EfficientPose 를 통해 다양한 요구 사항을 만족 할 수 있는 확장 가능한 모델을 제공함으로써 다양한 응용 분야의 제약 및 계산 비용 예산 즉, 정확도 및 효율성 간의 trade-off 를 만족 할 수 있도록 함
- mobile convNet 구성 요소를 이용하여 edge device 에서 실행 가능하게 함
- 광범위한 비교 연구를 수행하였으며, OpenPose 에 비해 더 높은 효율성과 정확도를 달성하면서도 기존의 SOTA 방법에 비해 훨씬 적은 수의 매개변수를 통해 경쟁력 있는 결과를 달성함
2. Related work

OpenPose 는 일련의 a series of detection passes 를 수행하는 multi-stage architecture 로 구성되어있다. 368 x 368 픽셀의 입력 이미지를 제공하는 OpenPose는 ImageNet 에서 사전 훈련된 VGG-19 backbone 을 활용하여 그림 1-1 과 같이 basic feature 들을 추출하게 된다. 이 feature 는 5개의 dense blcok 으로 구성된 DenseNet 에 영감을 받아 detection block 에 제공되며, 각 block 에는 PReLU 활성화 함수와 함께 3 개의 3 x 3 convolution 이 포함되어있다. detection block 은 순서대로 쌓이게 되며, 위 그림 1의 3a ~ 3d 단계에서 part affinity field 의 4번째 passes는 body keypoint 간의 연관성(association)을 매핑하게 된다. 그 후 2개의 detection passes는 refined keypoint coordinate estimate 를 얻기 위해 keypoint heatmap 을 얻게 된다. keypoint coordinate의 detail 관점에서 OpenPose 는 46 x 46 픽셀의 출력 해상도로 제한된다.
OpenPose 구조는 ConvNet 의 발전으로 인하여 아래 세가지 이유로 인해 개선 가능성을 보인다.
첫째, automated network architecture search 는 VGG 및 ResNets 보다 image classification 에서 backbone 이 더 정확하고 효율적임을 발견하였다. EfficientNet 에서는 image resolution, width(number of network channels), depth(number of network layers)의 균형을 맞추기 위해 제안된 compound model scaling 방법이며, 그 결과 모델 크기와 정밀도 수준이 유연하고 확장 가능한 EfficientNet이 등장하였다.
EfficientNet-B0 에서 B7 까지 각 모델의 variant $ \phi $ 는 $ (\phi \in \left [ 0, 7 \right ]\in \mathbb{Z}\geq ) $ 총 FLOP 수는 아래 식과 같이 2배 증가하게 된다.
$ \left ( \alpha \cdot \beta^{2} \cdot \gamma^{2} \right )^{\phi }\approx 2^{\phi } $
$ \alpha =1.2 , \beta =1.1 , \gamma = 1.15 $
둘째, parallel multi-scale feature extraction 은 자세 추정의 정밀도 수준을 높여 high spatial resolution 과 low-scale semantice 을 모두 강조할 수 있기 때문이다. 그러나 자세 추정의 기존 multi-scale 방식 방법들은 계산 비용이 방대하였고, 10-72 GLOPS에 반영되며 일반적으로 16-56 million parameters 가 소요된다. 이러한 문제를 해결하기 위해 본 논무에서는 신경망의 크기 및 계산 효율성 측면에서 낮은 오버헤드로 여러 abstraction level 에서 feature 들을 통합하는 cross-resolution feature 를 제안한다.
셋째, EfficientNet 에 통합된 SE(Squeeze-and-excitation) 및 이 Swish 활성화 함수가 내장된 MBConv (Mobile Inverted Bottleneck Convolution)은 image classification 에서 정확도가 입증되었다. 일반 convolution 과 비교하여 FLOP을 최대 19배 까지 줄여줄 수 있다. 이 MBConv 모듈의 효율성은 channel-wise 방식으로 작동하는 depthwise convolution 에서 비롯된다. 이는 채널 수에 비례하는 요인으로 계산 비용을 줄일 수 있게 된다. 또한 SE는 discriminative feature 를 선택적으로 강조하며 필요한 convolution 수와 detection pass 횟수를 줄여준다. 이와 함께 MBConv 를 활용하면 OpenPose 에서 dense block 수를 줄일 수 있다.
넷째, bilinear kernel 을 사용한 transposed convolution 은 출력 결과인 confidence map 에서 더 높은 수준의 세부 정보 추출을 가능하게 하는 low-resolution feature 를 upscale 할 수 있다.
이를 통해 실제 응용 프로그램에서 정확성 및 효율성의 trade-off 를 맞출 수 있으며 OpenPose 와 달리 이는 메모리가 적고 처리 능력이 낮은 edge device 에서 실행될 수 있다.
3. The EfficientPose approach
3.1 Architecture

위 그림과 같이 EfficientPose 신경망은 위 구조와 같으며, OpenPose 구조를 몇 가지 수정하였다.
- high and low resolution input images
- scalable EfficientNet backbones
- cross-resolution feature
- scalable Mobile DenseNet detection blocks in fewer detection passes
- bilinear upscaling
우선 신경망의 입력은 고해상도 및 저해상도 이미지로 구성된다. 저해상도 이미지는 initial average pooling layer 에 의해 고해상도 이미지의 픽셀 높이와 너비의 절반으로 down sampling 된다. EfficientPose 의 feature extractor 는 ImageNet 에서 사전 학습된 EfficientNet 의 초기 블록으로 구성된다. high-level semantic 정보는 high-scale EfficientNet ($ \phi \in \left [ 2, 7 \right ]\ $)의 초기 세개의 블록을 사용하여 고해상도 이미지로부터 얻어낸다. low-level local 정보는 $ \phi \in \left [ 0, 3 \right ]\ $ 범위에 있는 lower-scale EfficientNet backbone 의 initial 두 블록에 의해 저해상도 이미지에서 추출된다.
표 1은 low-scale B0 에서 high-scale B7 까지 EfficientNet backbone 의 구성을 보여준다.
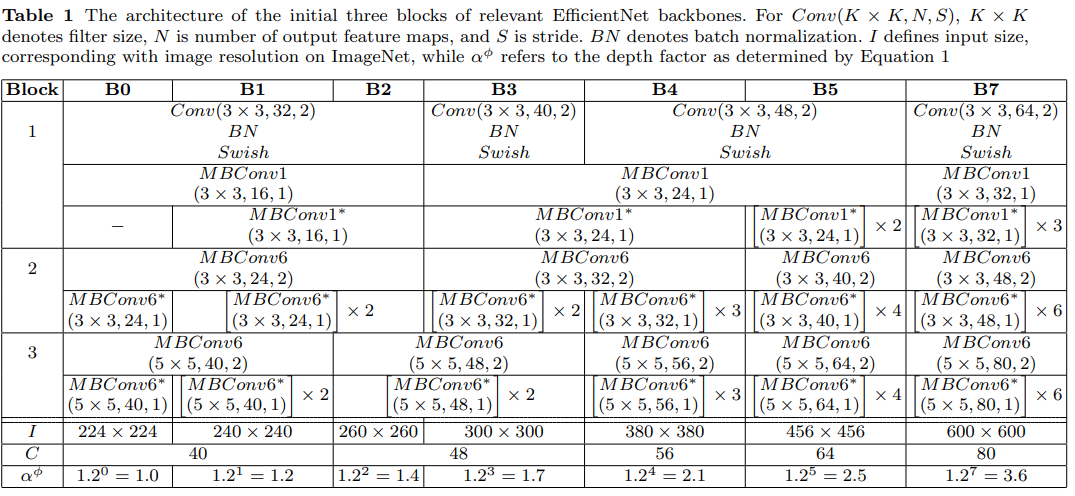
EfficientNet 의 첫번째 블록은 그림 3a 및 3b에 설명된 MBConv 를 사용하는 반면, 두번째 및 세번째 블록은 그림 3c 및 3d 의 MBConv layer 를 구성한다. 그림 2의 3단계 처럼 low-level 및 high-level EfficinetNet Backbone 에서 생성된 feature 는 연결되어 cross-resolution feature 를 구성하게 된다. 이런 식으로 EfficientPose 구조는 high-quality 포즈 추정이 가능하도록 할 수 있고, 전체 구조 및 관심 영역에서 중요한 local factor 를 선택적으로 강조 할 수 있다. 이런 식으로 multiple abstraction level 에서 feature 들을 동시에 처리 할 수 있다.
추출된 feature 에서 우리가 원하는 키포인트는 intermediate supervision 을 사용하는 iterative detection process 를 통해 localization 된다. 각 detection pass 는 detection block 과 output prediction 을 위한 단일 1 x 1 convolution 으로 구성된다.
그림 2-4와 같이 모든 detection passes에 있는 detection block 은 Mobile DenseNet 을 구성하는 동일한 구조를 이끌어낸다. Mobile DensNet 의 데이터는 residual connection 을 사용하여 detection block 의 subsequent layer 로 전달된다. Mobile DenseNet 은 feature reuse 를 지원하는 DenseNet 에서 영감을 받아 redundant layer 를 방지하고 MBConv with SE 를 사용하여 메모리 공간을 줄일 수 있다.
MBConv operation 에서 그림 3의 E-MBConv (K x K, B, S)에서 K x K 는 5 x 5 로 설정하고 expansion ratio 를 6 으로 설정한 모델이 최고의 성능을 달성하므로 이 조합을 지속적으로 활용한다. 또한 down sampling (S=1)을 피하고 high-level backbone (B = C)에 상대적인 채널 수를 출력하여 Mobile DensNet 의 너비를 조정한다.

또한 E-swith 를 $ \beta $ 값 1.25의 활성화 함수로 통합하여 MBConv6 작업을 수정하게 된다. 이는 정규 Swish 활성화 함수에 비해 학습 중에 진행을 가속화 하는 경향을 가진다. 또한 첫번째 1 x 1 convolution 을 조정하여 입력 채널 M 이 아닌 feature map B에 상대적인 feature map 수를 생성한다. 이렇게 하면 $ B \leq M, C\leq M \leq 3C $ 로 memory consumption 및 computational latency 가 줄어들게 된다. 3개의 연속적인 E-MBConv6 로 구성된 각 Mobile DenseNet 에서 모듈은 3C feature map 을 출력하게 된다.
EfficientPose 는 두 단계로 detection 을 수행한다. 첫째, 그림 2-5a 처럼 한번의 스켈레톤 추정을 통해 사람의 전체 자세를 예측한다. 이는 가능한 포즈 검출을 용이하게 하고 이미지에 여러 사람들이 있는 경우 혼돈을 방지하는데 도움을 줄 수 있다. 스켈레톤 추정은 part affinity field 를 통해 수행되며 스켈레톤 추정 후 관심 있는 키포인트에 대한 heatmap 을 추정하기 위해 두번의 detection pass 가 수행된다. 이들 중 전자(그림 2-5b)는 거친 검출(coarse detection) 역할을 수행하고 후자(그림2-5c)는 더 정확한 출력을 산출하기 위해 localization 을 개선하게 된다.
OpenPose 에서 final detection pass 의 heatmap 은 고해상도 입력에 내재된 세부적인 정보를 담을 수 없는 낮은 공간 해상도로 제한된다. 이러한 한계를 개선하기 위해 bilinear upsampling 을 수행하는 일련의 세 개의 transposed convolution 이 추가된다. 따라서 저해상도 출력을 고해상도 공간에 투영하여 detail level 을 높일 수 있다. 효율적으로 작동하면서 적절한 수준의 보간을 위해 각 transposed convolution 은 4 x 4 커널에서 stride 2 를 사용하여 map 의 크기를 2배로 증가시킨다.
3.2 Variants
원래 EfficientNet 에 적용되는 식의 계수를 사용하여 dimension, resolution, width, depth 에 대해 EfficientPose 를 확장한다. 표 2는 EfficinetPose 구조를 확장하여 얻은 5가지의 변형 모델을 보여준다. 입력 이미지의 공간적 차원을 정의하는 해상도는 고해상도 및 저해상도 입력의 해상도와 가장 잘 맞는 high-level 및 low-level EfficientNet backbone 을 사용하여 확장된다.

신경망의 너비는 각 E-MBConv6 에서 생성된 feature map 수를 나타낸다. 3.1 절에서 설명한대로 width scaling 은 high-level backbone과 동일한 width 를 사용하여 이루어지고, depth dimension 에서도 적절한 scaling 을 달성하기 위해 detection block 의 Mobile DenseNet 수(MD(C))에 편차가 발생한다. 이를 통해 모델 및 공간 해상도 전반에 걸쳐 receptive field 와 유사한 상대적인 크기가 보장된다.
각 모델 변형에 대해 high-level 의 EfficientNet backbone 에서 원래 depth factor $ \phi $ 에 가장 근접한 Mobile DenseNet 의 수(D) 를 선택하게 된다. 이 Mobile DenseNet 의 수는 가장 가까운 정수로 반올림하여 아래 식에 의해 결정된다.
$ D = \left [ \alpha ^{\phi } + 0.5 \right ] $
EfficientPose I ~ IV 외에도 단일 해상도 모델인 EfficientPose RT 는 가장 작은 EfficientNet 모델의 규모와 일치하도록 구성되어 latency 가 매우 짧은 어플리케이션에 사용 될 수 있다.
3.3 Summary of proposed famework
EfficientPose framework 는 compound scaling 의 이점을 얻을 수 있으며 확장 가능한 신경망을 구성하기 위한 계산 효율성이 뛰어난 Convolution Neural Network 를 발전시켜 다양한 계산 제약 조건에서 single person pose estimation 을 수행하는 5개의 ConvNet (EfficientPose RT-IV) 들로 구성된다.
보다 구체적으로 EfficientPose 는 고해상도 이미지와 저해상도 이미지를 모두 활용하여 각각 높은 수준과 낮은 수준의 backbone 을 통해 독립적으로 처리되는 두 개의 개별적인 viewpoint 를 제공하게 된다. 그 결과 feature 들은 연결되어 cross resolution feature 를 생성하여 global 및 local 이미지 정보를 선택적으로 강조 할 수 있다.
detection 단계는 확장 가능한 mobile deteciton block 을 사용하여 3단계로 detection 을 수행한다. 첫번째 단계 에서는 가능한 자세 구성을 생성하기 위해 part affinity field 를 통해 스켈레톤을 추정하고, 두번째 및 세번째 단계에서는 정확도가 점진적으로 향상되면서 키포인트의 위치를 추정하게 된다. 마지막으로 세번째 단계에서 저해상도 예측은 bilinear upsampling 을 통해 정밀도 수준이 더욱 더 향상된다.
4. Experiments and results
4.1 Experimental setup
- cyclical learning rate
- SGD
- random horizontal flipping
- scaling (0.75 − 1.25)
- rotation (+/− 45 degrees)
- PCKh@$ \tau $metric 사용
Ground Truth 위치에서 $ \tau l $거리 내에 있는 예측의 비율로 정의되며, $ l $ 은 head bounding box의 대각선의 60% 이고 $ \tau $는 허용되는 mis-judgment 의 비율이다. PCKh@50 은 MPII 의 standard performance metric 이지만 매우 정확한 키포인트 추정치를 산출하는 모델 능력을 평가하기 위해 더 엄격한 PCKh@10 metric 도 포함하였다. 일반적인 방식으로 multi-scale testing 을 통해 최종 모델 예측 결과를 얻는다.
MPII 에 대한 official evaluation 시도 횟수 제한으로 인하여 test metric 은 EfficientPose RT, EfficientPose IV 에 대해서만 제공한다. 모델 효율성을 측정하기 위해 FLOP 와 매개변수 수가 모두 제공된다.
4.2 Results
표 3은 MPII 데이터 세트에서 OpenPose 및 EfficientPose 를 평가할 때의 실험결과를 보여준다. 이는 EfficientPose 가 효율성 측면에서 OpenPose 를 능가한다는 것을 보여주고, 모델 크기는 4 ~ 56 배 더 작고 FLOP는 2.2 ~ 184 배 감소하였다는 것을 보여준다. 모든 모델의 variant 는 OpenPose 에 비해 PCKh@10 에서 0.8 ~ 12.9%로 향상된 high-precision localization 을 보여준다. 또한 high-end model 인 EfficientPose II-IV 는 PCKh@50 에서 0.6 ~ 2.2% 개선되었다.

표 4에서도 알수 있듯 EfficientPose IV 는 매개변수가 1,000만개 미만인 모델에 대해 mean PCKh@50 에서 91.2 를 달성하였다. OpenPose 와 비교하여 EfficientPose 는 학습 중에 rapid convergence 도 가능하다.
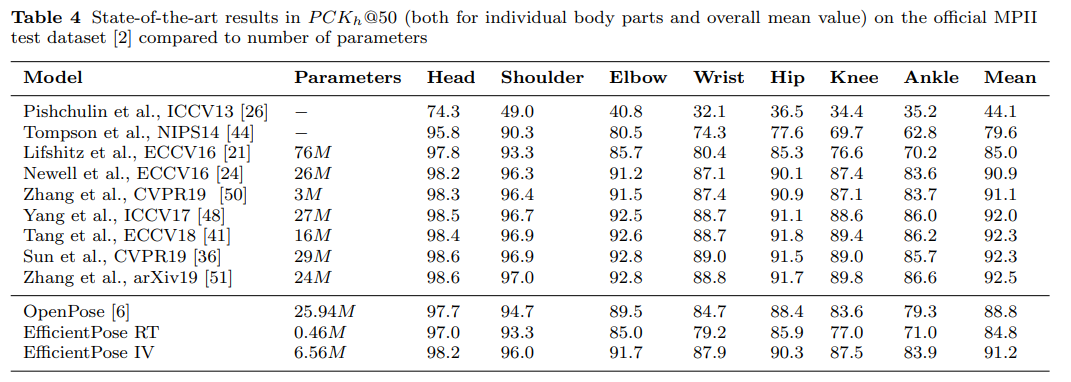
그림 4와 같이 학습 그래프는 EfficientPose가 초기에 수렴하는 반면 OpenPose는 적절한 수렴을 위해 최대 400 epoch가 필요함을 보여준다.
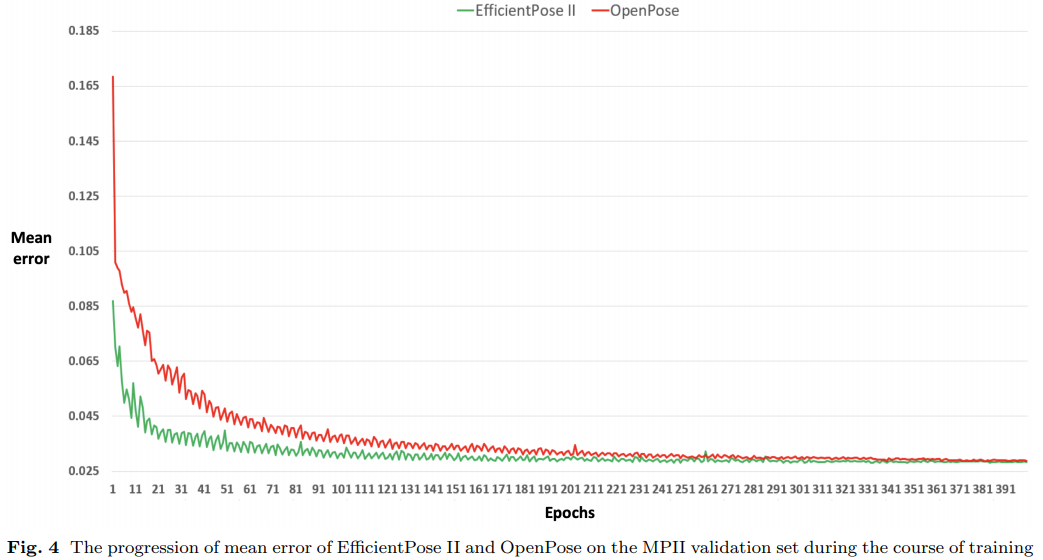
표 5에서도 알수 있듯 OpenPose는 마지막 200 epoch 동안 PCKh @ 50이 2.6 % 향상되는 장기간 학습의 이점을 누리는 반면 EfficientPose II는 0.4 %의 작은 이득을 얻었다.
5. Discuss
cross-resolution feature와 upscaling of output 에 의해 EfficientPose는 OpenPose 에 비해 정밀도 수준을 single person pose estimation에서 PCKh@10 기준 57 % 향상시켰다. 이는 single person pose estimation 도메인에서 자세추정을 수행 할 때 OpenPose 아키텍처의 한계를 반영한다. EfficientPose는 보다 일관적으로 높은 공간 해상도의 움직임 정보를 제공한다. 따라서 EfficientPose는 의료 및 스포츠 운동 평가와 같이 정밀도가 요구되는 single person pose estimation 애플리케이션을 처리하는 데 더 유용함을 입증하였다.
pose estimation 에서 MBConv를 사용하는 것은 첫 시도이며, 그럼에도 불구하고 EfficientPose는 매개 변수 수가 크게 감소 했음에도 불구하고 single person pose estimation 분야의 MPII 벤치 마크에서 SOTA 를 달성하였다. 이 MBConv은 좋은 구성 요소이며 Hourglass 및 HRNet과 같은 다른 새로운 pose estimation 구조와 결합 할 때 더 좋은 성능을 낼 수 있다.
이 연구에서 OpenPose 및 EfficientPose 는 MPII 데이터 세트에 최적화 되어있다. 행동인식 및 영상 감시 분야와 같이 MPII 의 가변성은 실제 문제에 적용하기에 적절 할 수 있지만, 다른 특정 시나리오에서는 적용하기 적절치 않을 수도 있다. MPII 는 대부분 성인들이 실내 및 실외에서 활동하는 동작들을 담고 있기 때문에 덜 자연적인 환경(병원 등)이나 어린이 및 유아와 같이 해부학적 비율이 다른 사람을 다루는 특정 도메인이라면 MPII 데이터 세트로 학습시킨 모델은 적절치 않을 수 있다. 이를 위해 MPII 모델을 미세 조정해야할 수도 있는데 본 논문에서 제안한 EfficientPose는 OpenPose 보다 쉽게 학습(빠르게 수렴)할 수 있기 때문에 전이 학습(Transfer Learning)이 편리하다는 것을 보여준다.
또한 여러 사람의 자세를 추정하는 도메인 즉 bottom-up 기반의 자세 추정 방식에서 OpenPose 보다 EfficientPose 가 계산 효율성이 좋기 때문에 이는 유용하게 동작한다.
그리고 EfficientPose를 학습 할 때 여러가지 방법으로 개선될 수 있는데
첫째, Adam 및 RMSProp 을 사용한다던지 기타 learning rate 조절 방법 및 sigma schedule 등 다른 방식들을 조합하여 성능을 개선해볼 수 있다.
둘째, EfficientPose의 backbone 만 ImageNet에서 사전 훈련되었다. large-scale pretraining 이 강력한 robust basic features 뿐만 아니라 higher-level semantics를 제공하므로 pose estimation의 정확도 수준이 제한 될 수 있다. 따라서 사전 훈련이 pose estimation의 모델 정밀도에 미치는 영향을 평가하는 것이 중요하다. ImageNet에서 대부분의 ConvNet 계층을 사전 교육하고 pose estimation 데이터에서 retrain 할 수 있다.
셋째, EfficientPose의 제안 된 compound scaling은 resolution, width, and depth 간의 scaling 관계가 pose estimation과 image recognition 모두에 대해 식 2에 의해 정의된다고 가정한다. 그러나 optimal compound scaling coefficients 는 pose estimation과 다를 수 있다. 여기서 정밀도 수준은 image classification 보다 이미지 해상도에 더 많이 의존한다.
따라서 추가 연구에서는 resolution, width, and depth 의 다양한 조합에서 neural architecture search을 수행하여 pose estimation에 대한 최적의 combination of scaling coefficients을 결정할 수 있다. scaling coefficients에 관계없이 EfficientPose에서 detction block 의 scaling을 개선 할 수 있다. block depth (즉, Mobile DenseNet의 수)는 Mobile DenseNet의 rigid nature에 따라 EfficientNet의 원래depth coefficient 와 약간 다르다. carefully designed detection block은 number of layers 및 receptive field size와 관련하여 더 많은 유연성을 제공하여 이 문제를 해결할 수 있다.
넷째, EfficientPose의 계산 효율성은 high-scale의 EfficientPose teacher network에서 low-scale의 EfficientPose student network로 지식을 전달하기 위해 teacher-student network training (i.e. knowledge distillation)을 사용하여 더욱 향상 될 수 있다. 이 기술은 stacked hourglass architecture와 함께 사용했을 때 pose estimation에서 이미 가능성을 보여준 연구 결과이다.
Sparse networks, network pruning, and weight quantization도 고려하여 점점 더 정확하고 반응이 빠른 pose estimation 의 시스템을 지원할 수 있다.
high performance inference 및 edge device 에 대한 배포를 위해 NVIDIA TensorRT 및 TensorFlow Lite 와 같은 특수 라이브러리를 사용하여 속도를 더욱 높일 수 있다.
6. Conclusion
EfficientPose는 OpenPose에 비해 향상된 정밀도로 single person pose estimation을 다룬다. 그럼에도 불구하고 EfficientPose 모델은 매개 변수 및 FLOP 수를 크게 줄이며, 이것은 계산 효율적인 ConvNet 구성 요소, 특히 MBConvs 및 EfficientNets에 대한 image recognition 내에서 이점을 적용함으로써 달성된다. EfficientPose 모델은 공개적으로 제공되어 움직임 분석에 대한 research initiatives를 제공한다.
이 방법은 계산 효율적인 multi-scale feature extractor, novel mobile detection blocks, pose association estimates 및 bilinear upscaling을 활용하는 확장 가능한 ConvNet 구조이다.
정확성과 효율성 사이의 trade-off 에서 유연성을 제공 할 수있는 model variants을 산출하기 위해 본 논문에서는 resolution, width, and depth 3 차원에서 모델 확장 성을 활용하는 EfficientPose 접근 방식을 개발했다. 우리의 실험 결과는 제안 된 접근 방식이 계산 효율적인 모델을 제공하여 에지 장치에서 실시간 추론을 허용한다는 것을 보여준다.
동시에, 우리의 프레임 워크는 일반적으로 사용되는 OpenPose 보다 훨씬 적은 매개 변수와 FLOP으로 더 정확한 키포인트 추정치를 제공할 수 있다. 향후 작업에서는 human pose estimation을 위한 최적의 optimal compound model을 조사하여 특히 정밀도 측면에서 모델 효율성을 더욱 향상시키는 새로운 기술을 개발할 계획이다. 또한 다양한 응용 프로그램에 EfficientPose를 배포하여 실제 시나리오에서 적용 가능성과 타당성을 확인할 것이다.