[Diffusion] SceneDiffuser, Diffusion-based Generation, Optimization, and Planning in 3D Scenes
Project page : https://scenediffuser.github.io/
SceneDiffuser
Siyuan Huang1✶✉️ Zan Wang1,2✶ Puhao Li1,3 Baoxiong Jia1 Tengyu Liu1 Yixin Zhu4 Wei Liang2✉️ Song-Chun Zhu1,3,4 ✶ indicates equal contribution ✉️ indicates corresponding authors 1National Key Labor
scenediffuser.github.io
Video : https://scenediffuser.github.io/assets/illustration-720.mp4
Paper : Diffusion-based Generation, Optimization, and Planning in 3D Scenes https://arxiv.org/abs/2301.06015
Diffusion-based Generation, Optimization, and Planning in 3D Scenes
We introduce SceneDiffuser, a conditional generative model for 3D scene understanding. SceneDiffuser provides a unified model for solving scene-conditioned generation, optimization, and planning. In contrast to prior works, SceneDiffuser is intrinsically s
arxiv.org

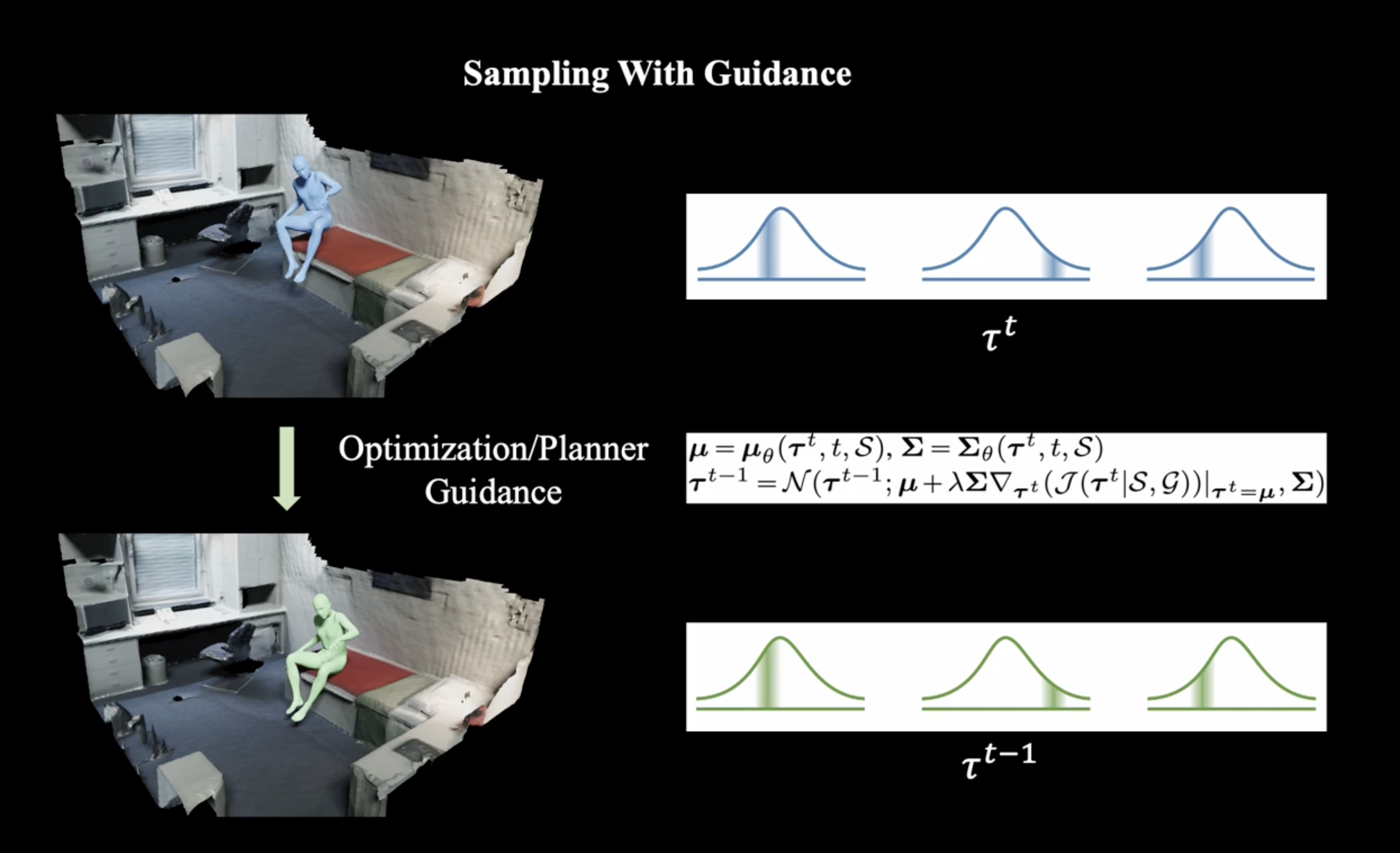
huggingface에서 SceneDiffuser를 공개했다. SceneDiffuser는 scene-conditioned generation, optimization, planning을 해결하기 위한 unified model을 제공한다. 이는 장면을 scene-aware, physics-based, goal-oriented 특징을 가지고 있다. iterative sampling 전략을 사용하여 scene-aware generateion, physics-based optimization, goal-oriented planning, diffusion-based denoising process을 사용한다. 이는 서로 다른 모듈과의 불일치와 previous scene-conditioned generative model의 posterior collapse를 완화시킨다. 또한 pose 및 motion generation, 민첩한 grasp generation, 3d navigation을 위한 pth planning, robot arms의 motion planning을 포함한 다양한 3d scene에 대한 작업을을 통해 SceneDiffuser를 평가한다.
guidance를 통해 sampling을 수행하며, optimization을 거친다.
아래와 같이 grasp generation 및 robot arms motion 도 생성할 수 있다.

