[3D HPS] BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion
Paper : https://bedlam.is.tuebingen.mpg.de/media/upload/BEDLAM_CVPR2023.pdf
Project page : https://bedlam.is.tue.mpg.de/
BEDLAM
bedlam.is.tue.mpg.de
GitHub : https://github.com/pixelite1201/BEDLAM
GitHub - pixelite1201/BEDLAM
Contribute to pixelite1201/BEDLAM development by creating an account on GitHub.
github.com

이번에 리뷰할 논문은 GitHub에 약 3일전에 업로드된 CVPR 2023에 소개 될 논문 "BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion"입니다. 참고로 Max Planck Institute for Intelligent Systems과 Google에서 낸 논문입니다. 3D Human Pose and Shape (3D HPS) 분야 연구를 위해 만들어진 large-scale synthetic video dataset 입니다. 참고로 BEDLAM의 full name은 "Detailed Lifelike Animated Motion" 입니다. 이는 다양한 body shape, skin tone, motion을 담고 있습니다. 이러한 데이터를 통해서 real training image 없이도 real image dataset에서 SOTA를 달성했다고 하네요.
이전에 syn dataset에서는 dataset이 작거나, 비현실적이거나 사실적인 의상이 부족했다고 합니다. BEDLEM dataset에서는 이러한 기존의 단점들을 해결하여 SMPL-X 포맷의 GT 3d body가 있는 monocular RGB video로 데이터를 생성했습니다. 기존 연구에서는 SMPL 및 HMR(End-to-end recovery of human shape and pose) 의 도입으로 연구가 급속도로 발전하여 3D HPS의 정확도가 향상했지만, 여전히 모델 구조 개선과 training dataset 개선이라는 문제점이 남아있다고 합니다.
BEDLEM은 다양한 데이터를 생성하기 위해 271개의 body shape(남성 109명, 여성 162명)을 지원하고, 다양한 skin tone을 지원하기 위해 Meshcapade 방법의 100가지 skin texture를 사용했다고 합니다. 또한 이전 작업과는 달리 SMPL-X의 머리에 27가지 hair(Reallusion)를 추가했습니다. 또한 몸에 옷을 입히기 위해 3d 의상 디자이너를 고용해서 111개의 의상을 만들고 CLO3D를 사용하여 몸에 입히고 시뮬레이션 했다고 합니다. 또한 1691년 아티스트가 디자인한 texture를 이용하여 옷에 texture를 입히고, body는 AMASS에서 샘플링한 2311개의 동작을 사용하여 애니메이션화 했다고 합니다.
여기서 AMASS는 hand motion을 포함하지 않기 때문에 static hand를 GRAB dataset에서 샘플링된 hand motion으로 대체했습니다. 또한 다양한 3d scene과 HDRI panorama에서 움직이는 multiple people을 지원합니다. 사람은 3명에서 10명 정도이고, scene에서 여러 사람이 충돌하지 않도록 간단한 방법을 사용하고, 다양한 focal length로 시뮬레이션된 camera motion을 사용한다고 합니다.
또한 image sequence는 unreal engine을 사용하여 30fps로 motion blur와 함께 렌더링 됩니다. 총 이미지 당 1명-10명 정도의 사람이 포함되어있는 약 380K의 이미지들로 구성됩니다. 또한 1M 개의 bounding box가 포함되어있다고 합니다.
데이터를 만드는 과정은 아래 그림과 같습니다. 마지막 쪽 그림 g, h는 멀리서 보면 굉장히 사실적으로 보입니다.

아래와 같이 다양한 skin tone을 지원합니다.

아래 그림은 다양한 옷과 texture를 나타냅니다.

BMI 지수에 따라 texture를 매핑했네요 !

또한, 아래 그림과 같이 다양한 헤어 스타일을 지원합니다.

CLIFF 모델을 이용하여 학습한 결과는 아래와 같습니다. 참고로 CLIFF 모델 논문은 아래와 같습니다.
CLIFF: Carrying location information in full frames into human pose and shape estimation

각 3DPW, RICH에서 평가한 결과는 아래와 같습니다. RICH 데이터세트는 SMPL-X 포맷으로 이루어져 있습니다.

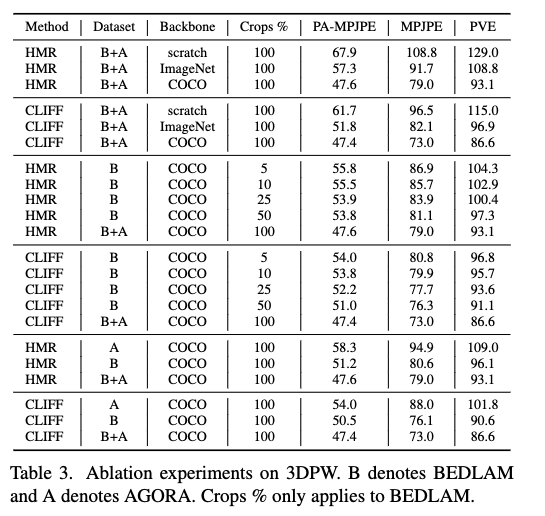
추가로 supplementary material에는 더 다양한 정보를 제공하고 있습니다. 주로 학습에 관련된 결과를 제공하고 있습니다.


'AI Research Topic > 3D Pose and Shape' 카테고리의 다른 글
꾸준희님의
글이 좋았다면 응원을 보내주세요!