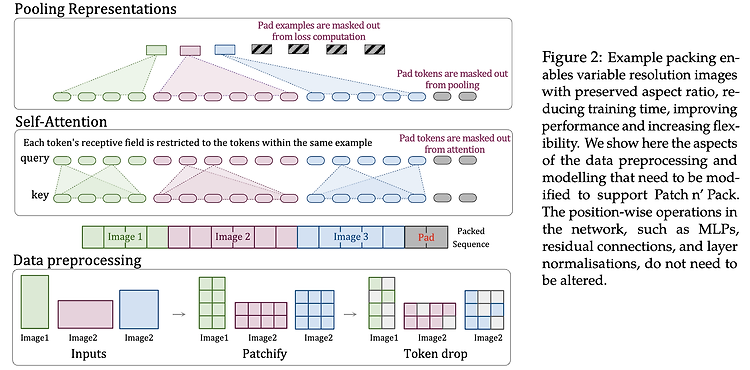
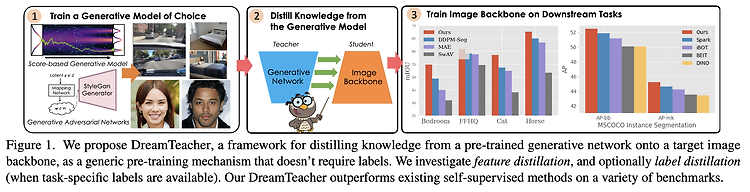
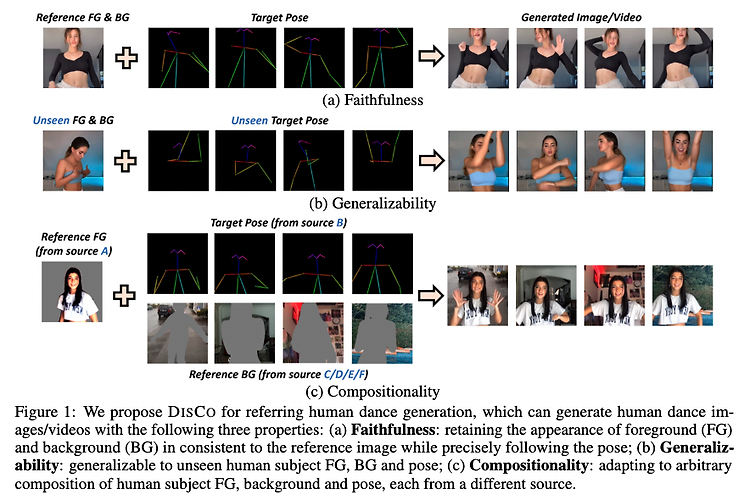
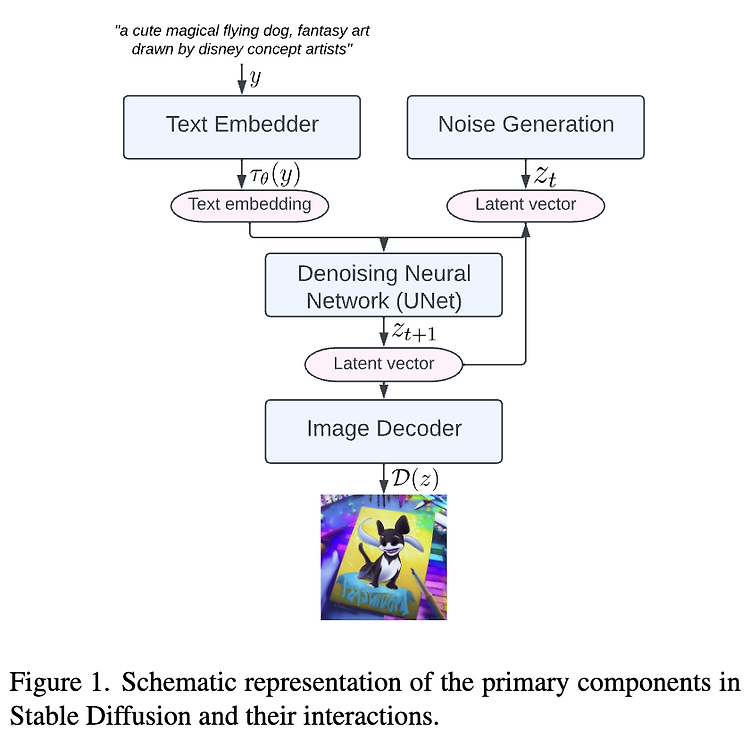
[3D Pose and Shape] Motion-X: A Large-scale 3D Expressive Whole-body Human Motion Dataset
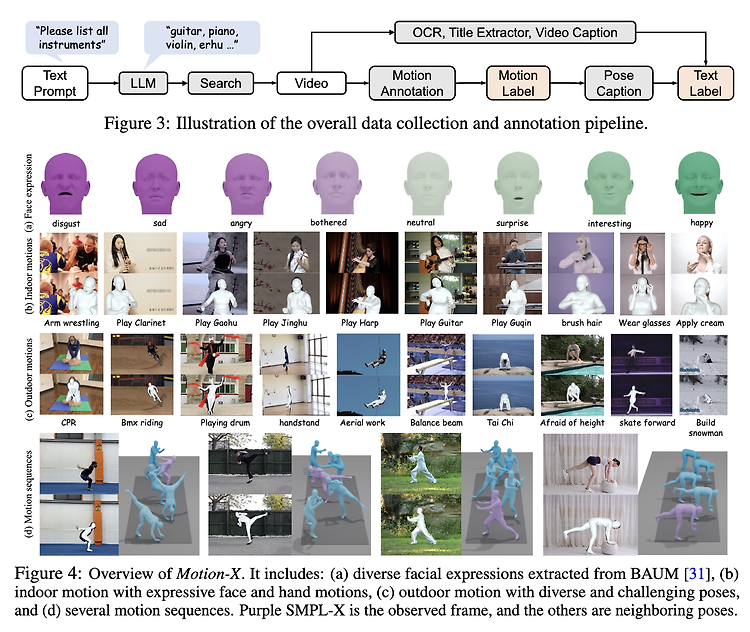
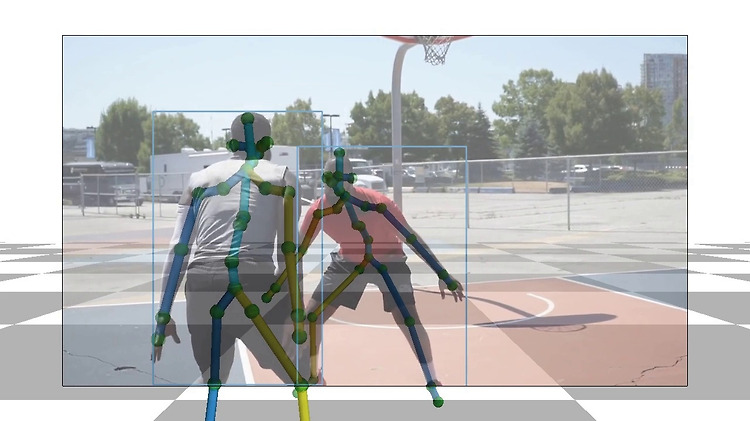
Project page : https://motion-x-dataset.github.io/ Motion-X: A Large-scale 3D Expressive Whole-body Human Motion Dataset We propose Motion-X, a large-scale 3D expressive whole-body motion dataset. Existing motion datasets predominantly contain body-only poses, lacking facial expressions, hand gestures, and fine-grained pose descriptions. Moreover, they are primarily collecte motion-x-dataset.git..
2023.08.07