[3D Reconstruction] CS231A, Computer Vision, From 3D Reconstruction to Recognition
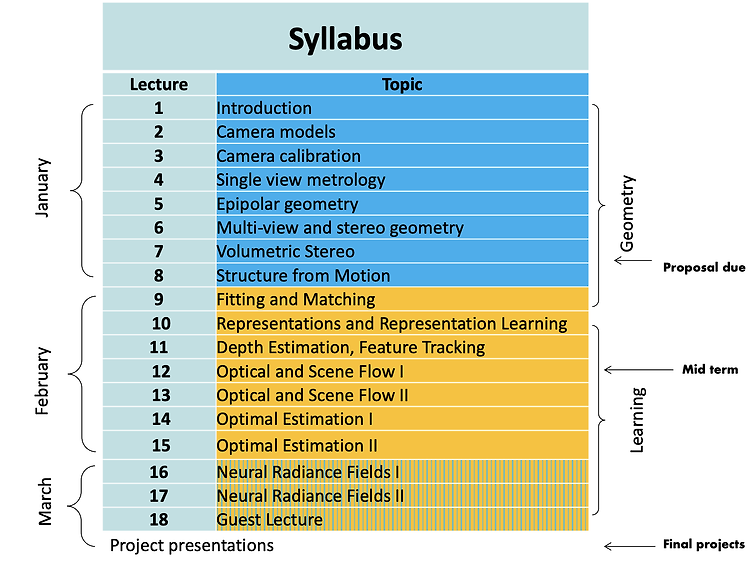
CS231A: Computer Vision, From 3D Reconstruction to Recognition https://web.stanford.edu/class/cs231a/ CS231A: Computer Vision, From 3D Reconstruction to Recognition Can I audit or sit in? In general we are very open to sitting-in guests if you are a member of the Stanford community (registered student, staff, and/or faculty). Out of courtesy, we would appreciate that you first email us or talk t..
2022.07.16